



数据科学和人工智能间的相似之处
人工智能和数据科学都包括用于分析和利用大量数据的工具、技术和算法。以下是二者的一些相似之处。
预测性应用
人工智能和数据科学技术都基于新数据进行预测,这是应用在分析先前数据时学到的模型和方法的结果。例如,根据前几年的数据预测未来的每月雨伞销售额便是数据科学中时间序列数据分析的一个例子。
同样,自动驾驶汽车是预测性人工智能系统的一个例子。自动驾驶汽车上路时,会计算与前车的距离以及两辆车的速度。根据预测前方汽车的急刹车,它可以将速度保持在能够避免碰撞的速度。
数据质量要求
如果训练数据不一致、有偏见或不完整,那么人工智能和数据科学技术给出的结果便都不太准确。例如,数据科学和人工智能算法可能:
- 会在新数据全新且不在原始数据集中时,将新数据过滤掉。
- 会在输入数据缺少变体时,将数据集中的特定属性优先于所有其他属性。
- 会因为输入数据错误而创建不存在或虚构的信息。
机器学习
机器学习(ML)是数据科学和人工智能的子类型。这意味着所有机器学习模型都可以视为数据科学模型,所有机器学习算法也可以视为人工智能算法。有一种常见的误解是,所有的人工智能都使用机器学习,但事实并非如此。复杂的人工智能解决方案并不一定需要机器学习。同样,并非所有数据科学解决方案都涉及机器学习。
主要差异:数据科学与人工智能
数据科学涉及分析数据,从而确定潜在模式和兴趣点以进行预测。应用数据科学采用数据分析中使用的模型和方法,并将其应用于现实情况中的新数据,得出概率输出。相比之下,人工智能使用应用的数据科学技术和其他算法来组成和运行接近人类智慧的复杂机器系统。
数据科学也可用于人工智能和计算机科学以外的应用。
目标
数据科学的目标是应用现有的统计和计算模型和方法来理解收集的数据中的兴趣点或模式。结果是预先确定的,并且从一开始就很容易确定。例如,您可以使用数据来预测未来的销售额或确定机器何时可以维修。
人工智能的目标是使用计算机从复杂的新数据中得出难以与人类智能推理区分的结果。结果是通用的,但难以定义,例如,生成创意文本或从文本生成图像。问题集的详细信息太庞大,无法准确定义,人工智能系统会自行解读问题。
范围
由于结果是预先确定的,因此数据科学的范围较小。此过程首先要确定可以根据数据回答的问题。范围包括:
- 数据收集和预处理。
- 对数据应用适当的模型和算法来回答这些问题。
- 解读结果。
相比之下,人工智能的范围要广泛得多,但具体步骤因所解决的问题而异。此过程首先要确定耗费人力的手动任务或人类可以成功执行的复杂推理任务,而我们希望机器可以复制这种能力。范围可能包括:
- 探索性数据分析。
- 将任务分成算法组件,形成系统。
- 收集测试数据,审查和完善逻辑流程的适用性和系统的复杂性。
- 测试系统。

方法
数据科学有各种数据建模技术。如何选择正确的技术要取决于数据和所提出的问题。这些技术包括线性回归、逻辑回归、异常检测、二进制分类、k 均值集群、主成分分析等。错误地应用统计分析会产生意料之外的结果。
人工智能应用程序通常依赖于复杂的预构建产品化组件。其中可能包括面部识别、自然语言处理、强化学习、知识图谱、生成式人工智能等等。
应用:数据科学与人工智能
只要有足够的高质量数据和模型来帮助回答特定问题,就可以应用数据科学。应用包括:
- 销售需求预测。
- 欺诈检测。
- 体育赔率。
- 风险评测。
- 能耗预测。
- 收入优化。
- 候选人筛选流程。
人工智能的应用几乎是无限的。常见应用包括:
- 机器人生产线。
- 聊天机器人。
- 生物识别系统。
- 医学影像分析。
- 预测性维护。
- 城市规划。
- 个性化营销。
职业:数据科学与人工智能
数据科学家的主要工作通常是技术性的深入研究数据。数据科学家可能致力于数据的收集和处理,为数据选择正确的数据模型,并解读结果以提出相关建议。工作可能在特定软件或系统中,甚至可能在建筑系统本身。
角色类型
数据科学工作包括数据科学家、数据分析师、数据工程师、机器学习工程师、研究科学家、数据可视化专家、特定领域的分析师职位等。人工智能领域也包含所有这些职位。但是,由于该领域涉及的范围十分广泛,因此还有许多其他相关的职位和工作重点领域,例如软件开发人员、产品经理、营销专家、人工智能测试人员、人工智能工程师等。
技能组合
数据科学家具有统计和算法方法的实际应用技能,可以对数据进行鉴定和分析,获得相关的见解。数据科学家需要统计数学和计算机科学背景,并能够熟练使用适用工具。
根据在人工智能领域的职位,所需的技能组合可能更偏重技术,也可能更偏重软技能。某些职位可能不需要任何技术经验。例如,人工智能软件开发人员需要相关编程语言、库和工具的实用知识。但是,生成式人工智能工具的人工智能测试人员则需要语言技能、创造性思维以及了解用户如何与系统交互。
职业发展
随着数据科学工具和工作流程更加自动化和产品化,纯数据科学职位的数量在不断减少。寻求纯数据科学职位的数据科学专业人士倾向于学术和尖端应用。由数据科学家负责工具操作的分析师角色则仍然很重要。数据科学家可以从初级职位开始,晋升到更高级的职位,也可以转职到人事或项目管理,甚至晋升为首席数据官。
根据人工智能职位本身的重点,同样也可以有类似的职业发展预期。您可以晋升为首席技术官、首席营销官、首席产品官等等。批判性地思考未来十年哪些工作将实现自动化可以帮助您确定经得起未来考验的职业方向。
差异摘要:数据科学与人工智能
| 数据科学 |
人工智能 |
|
| 创新中心是什么? |
使用统计和算法建模从数据中获得见解。 |
一个广义的术语,泛指模仿人类智能的基于机器的应用程序。 |
| 最适合 |
根据一组数据中回答问题。 |
高效完成复杂的人类任务。 |
| 方法 |
线性回归、逻辑回归、异常检测、二进制分类、k 均值集群、主成分分析等。 |
面部识别、自然语言处理、强化学习、知识图谱、生成式人工智能等。 |
| 范围 |
可以根据数据回答的预定义问题。 |
范围广、难定义 – 以任务为基础。 |
| 实施 |
使用一系列不同的工具来捕获、清理、建模、分析并报告数据。 |
视任务而定。通常基于复杂的预构建产品化组件。 |
AWS 如何帮助您应对数据科学和人工智能需求?
AWS 拥有全面的数据科学和 AI 产品与服务,旨在帮助您加强和提升组织和个人数据的分析和情报。
这包括用于结构化和非结构化数据的基于 API 的数据科学和 AI 模型,以及为数据科学和 AI 解决方案的端到端创建和部署提供完全托管式环境。
- Amazon SageMaker Studio 是一个集成式开发环境(IDE),其中包括用于开发数据科学和 ML 解决方案的专用工具堆栈。
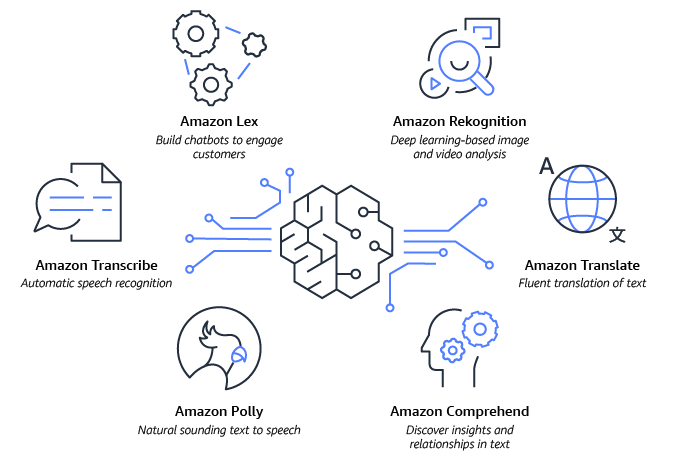
- Amazon Lex 可帮助您使用对话式 AI 构建自己的聊天机器人。
- Amazon Rekognition 提供预先训练和可定制的计算机视觉(CV)功能,可从您的图像和视频中提取信息和获得见解。
- Amazon Comprehend 可帮助您从文档文本中获取和理解有价值的见解。
- Amazon Personalize 利用 ML 来帮助您个性化客户体验。
- Amazon Forecast 有助于进行时间序列预测。
- Amazon Fraud Detector 可帮助您构建、部署和管理欺诈检测模型。
AWS 还提供越来越多的世界一流的生成式人工智能解决方案,这些解决方案可创新内容和想法,包括对话、故事、图像、视频和音乐。生成式人工智能解决方案包括:
- Amazon Bedrock 帮助组织构建和扩展生成式人工智能解决方案。
- AWS Trainium 可帮助更快地训练生成式人工智能模型。
- Amazon CodeWhisperer 是一款免费的生成式人工智能编码助手。
立即创建账户,开始使用 AWS 上的数据科学和人工智能。