AWS Big Data Blog
Category: Analytics
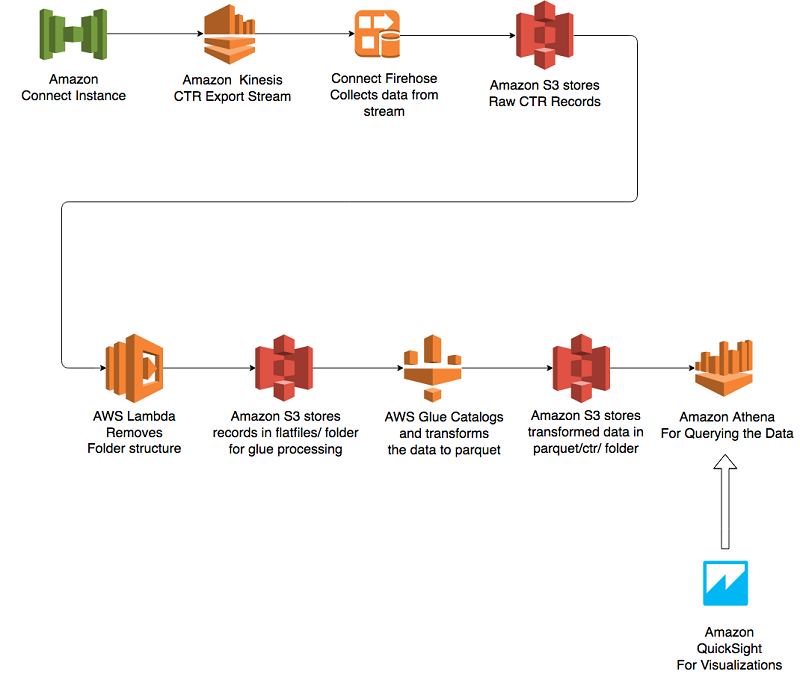
Analyze Amazon Connect records with Amazon Athena, AWS Glue, and Amazon QuickSight
In this blog post, we focus on how to get analytics out of the rich set of data published by Amazon Connect. We make use of an Amazon Connect data stream and create an end-to-end workflow to offer an analytical solution that can be customized based on need.

Orchestrate Apache Spark applications using AWS Step Functions and Apache Livy
In this post, I’ll show you how to use AWS Step Functions to orchestrate your Spark jobs that are running on Amazon EMR.
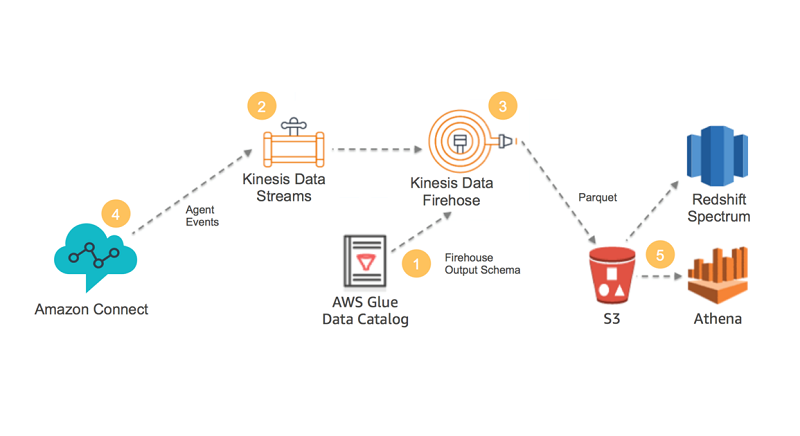
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.

Use AWS Glue to run ETL jobs against non-native JDBC data sources
In this post, we demonstrate how to connect to data sources that are not natively supported in AWS Glue today. We walk through connecting to and running ETL jobs against two such data sources, IBM DB2 and SAP Sybase.

Analyze data in Amazon DynamoDB using Amazon SageMaker for real-time prediction
I’ll describe how to read the DynamoDB backup file format in Data Pipeline, how to convert the objects in S3 to a CSV format that Amazon ML can read, and I’ll show you how to schedule regular exports and transformations using Data Pipeline.
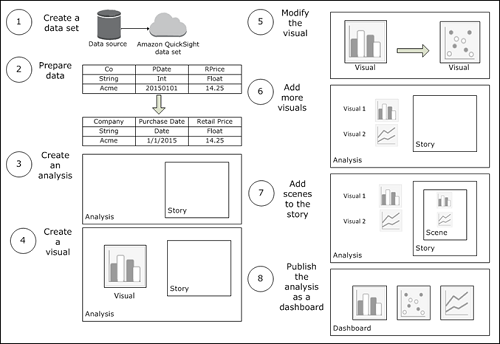
10 visualizations to try in Amazon QuickSight with sample data
Using Amazon QuickSight, you can see patterns across a time-series data by building visualizations, performing ad hoc analysis, and quickly generating insights.

Implement continuous integration and delivery of serverless AWS Glue ETL applications using AWS Developer Tools
In this post, I walk you through a solution that implements a CI/CD pipeline for serverless AWS Glue ETL applications supported by AWS Developer Tools (including AWS CodePipeline, AWS CodeCommit, and AWS CodeBuild) and AWS CloudFormation.
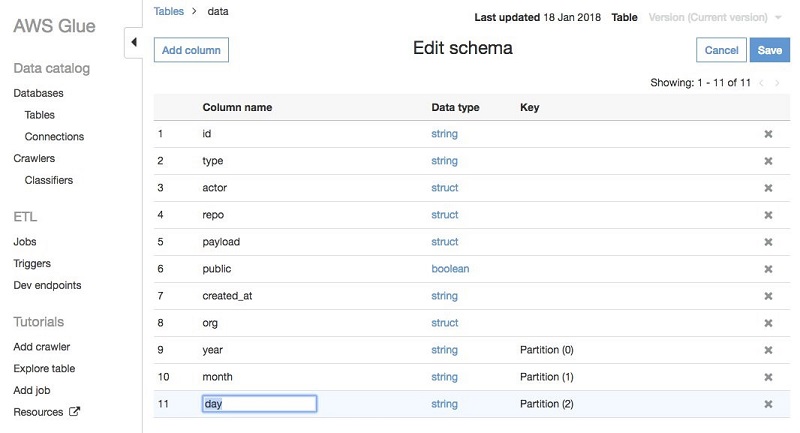
Work with partitioned data in AWS Glue
In this post, we show you how to efficiently process partitioned datasets using AWS Glue. First, we cover how to set up a crawler to automatically scan your partitioned dataset and create a table and partitions in the AWS Glue Data Catalog. Then, we introduce some features of the AWS Glue ETL library for working with partitioned data.
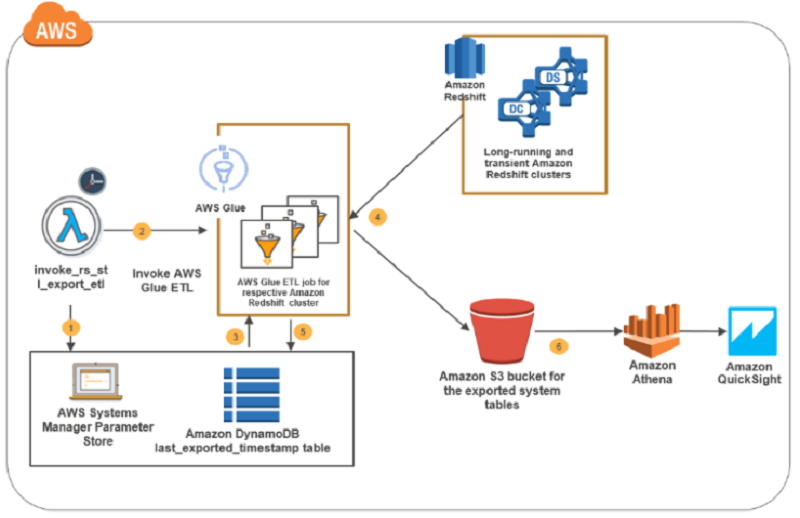
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.

Getting started: Training resources for Big Data on AWS
Whether you’ve just signed up for your first AWS account or you’ve been with us for some time, there’s always something new to learn as our services evolve to meet the ever-changing needs of our customers. To help ensure you’re set up for success as you build with AWS, we put together this quick reference guide for Big Data training and resources available here on the AWS site.