AWS Big Data Blog
Category: Amazon SageMaker

Improve the discoverability of your unstructured data in Amazon SageMaker Catalog using generative AI
This is a two-part series post. In the first part, we walk you through how to set up the automated processing for unstructured documents, extract and enrich metadata using AI, and make your data discoverable through SageMaker Catalog. The second part is currently in the works and will show you how to discover and access the enriched unstructured data assets as a data consumer. By the end of this post, you will understand how to combine Amazon Textract and Anthropic Claude through Amazon Bedrock to extract key business terms and enrich metadata using Amazon SageMaker Catalog to transform unstructured data into a governed, discoverable asset.

Get started faster with one-click onboarding, serverless notebooks, and AI agents in Amazon SageMaker Unified Studio
Using Amazon SageMaker Unified Studio serverless notebooks, AI-assisted development, and unified governance, you can speed up your data and AI workflows across data team functions while maintaining security and compliance. In this post, we walk you through how these new capabilities in SageMaker Unified Studio can help you consolidate your fragmented data tools, reduce time to insight, and collaborate across your data teams.

Accelerate context-aware data analysis and ML workflows with Amazon SageMaker Data Agent
In this post, we demonstrate the capabilities of SageMaker Data Agent, discuss the challenges it addresses, and explore a real-world example analyzing New York City taxi trip data to see the agent in action.
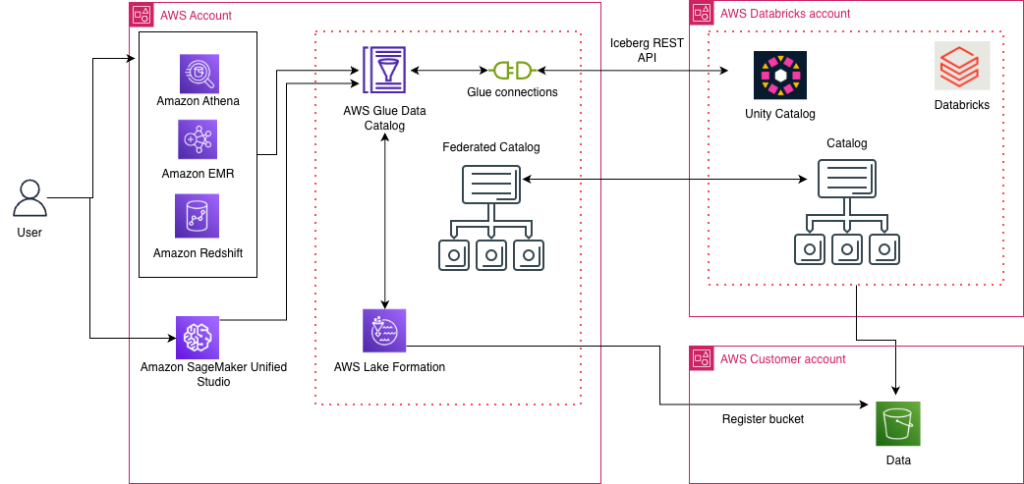
Access Databricks Unity Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has launched the catalog federation capability, enabling direct access to Apache Iceberg tables managed in Databricks Unity Catalog through the AWS Glue Data Catalog. With this integration, you can discover and query Unity Catalog data in Iceberg format using an Iceberg REST API endpoint, while maintaining granular access controls through AWS Lake Formation. In this post, we demonstrate how to set up catalog federation between the Glue Data Catalog and Databricks Unity Catalog, enabling data querying using AWS analytics services.

Use Amazon SageMaker custom tags for project resource governance and cost tracking
Amazon SageMaker announced a new feature that you can use to add custom tags to resources created through an Amazon SageMaker Unified Studio project. This helps you enforce tagging standards that conform to your organization’s service control policies (SCPs) and helps enable cost tracking reporting practices on resources created across the organization. In this post, we look at use cases for custom tags and how to use the AWS Command Line Interface (AWS CLI) to add tags to project resources.

Introducing catalog federation for Apache Iceberg tables in the AWS Glue Data Catalog
AWS Glue now supports catalog federation for remote Iceberg tables in the Data Catalog. With catalog federation, you can query remote Iceberg tables, stored in Amazon S3 and cataloged in remote Iceberg catalogs, using AWS analytics engines and without moving or duplicating tables. In this post, we discuss how to get started with catalog federation for Iceberg tables in the Data Catalog.

Accelerate data lake operations with Apache Iceberg V3 deletion vectors and row lineage
In this post, we walk you through the new capabilities in Iceberg V3, explain how deletion vectors and row lineage address these challenges, explore real-world use cases across industries, and provide practical guidance on implementing Iceberg V3 features across AWS analytics, catalog, and storage services.

Cross-account lakehouse governance with Amazon S3 Tables and SageMaker Catalog
In this post, we walk you through a practical solution for secure, efficient cross-account data sharing and analysis. You’ll learn how to set up cross-account access to S3 Tables using federated catalogs in Amazon SageMaker, perform unified queries across accounts with Amazon Athena in Amazon SageMaker Unified Studio, and implement fine-grained access controls at the column level using AWS Lake Formation.

Optimize efficiency with language analyzers using scalable multilingual search in Amazon OpenSearch Service
Organizations manage content across multiple languages as they expand globally. Ecommerce platforms, customer support systems, and knowledge bases require efficient multilingual search capabilities to serve diverse user bases effectively. This unified search approach helps multinational organizations maintain centralized content repositories while making sure users, regardless of their preferred language, can effectively find and access relevant […]

Accelerate your data and AI workflows by connecting to Amazon SageMaker Unified Studio from Visual Studio Code
In this post, we demonstrate how to connect your local VS Code to SageMaker Unified Studio so you can build complete end-to-end data and AI workflows while working in your preferred development environment.