AWS Big Data Blog
Category: Amazon SageMaker

Optimize efficiency with language analyzers using scalable multilingual search in Amazon OpenSearch Service
Organizations manage content across multiple languages as they expand globally. Ecommerce platforms, customer support systems, and knowledge bases require efficient multilingual search capabilities to serve diverse user bases effectively. This unified search approach helps multinational organizations maintain centralized content repositories while making sure users, regardless of their preferred language, can effectively find and access relevant […]

Accelerate your data and AI workflows by connecting to Amazon SageMaker Unified Studio from Visual Studio Code
In this post, we demonstrate how to connect your local VS Code to SageMaker Unified Studio so you can build complete end-to-end data and AI workflows while working in your preferred development environment.
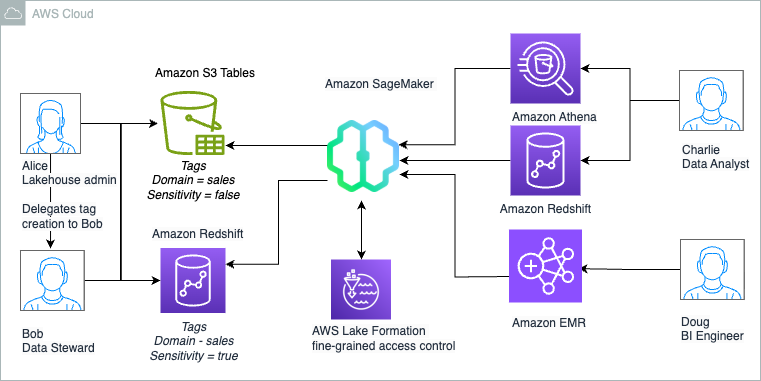
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Amazon SageMaker Catalog expands discoverability and governance for Amazon S3 general purpose buckets
In July 2025, Amazon SageMaker announced support for Amazon Simple Storage Service (Amazon S3) general purpose buckets and prefixes in Amazon SageMaker Catalog that delivers fine-grained access control and permissions through S3 Access Grants. In this post, we explore how this integration addresses key challenges our customers have shared with us, and how data producers, such as administrators and data engineers, can seamlessly share and govern S3 buckets and prefixes using S3 Access Grants, while making it readily discoverable for data consumers.

Guide to adopting Amazon SageMaker Unified Studio from ATPCO’s Journey
ATPCO is the backbone of modern airline retailing, helping airlines and third-party channels deliver the right offers to customers at the right time. ATPCO addressed data governance challenges using Amazon DataZone. SageMaker Unified Studio, built on the same architecture as Amazon DataZone, offers additional capabilities, so users can complete various tasks such as building data pipelines using AWS Glue and Amazon EMR, or conducting analyses using Amazon Athena and Amazon Redshift query editor across diverse datasets, all within a single, unified environment. In this post, we walk you through the challenges ATPCO addresses for their business using SageMaker Unified Studio.

Integrate scientific data management and analytics with the next generation of Amazon SageMaker, Part 1
In this blog post, AWS introduces a solution to a common challenge in scientific research – the inefficient management of fragmented scientific data. The post demonstrates how the next generation of Amazon SageMaker, through its Unified Studio and Catalog features, helps scientists streamline their workflow by integrating data management and analytics capabilities.

Develop and deploy a generative AI application using Amazon SageMaker Unified Studio
In this post, we demonstrate how to use Amazon Bedrock Flows in SageMaker Unified Studio to build a sophisticated generative AI application for financial analysis and investment decision-making.

Enhance governance with asset type usage policies in Amazon SageMaker
In this post, we introduce authorization policies for custom asset types—a new governance capability in Amazon SageMaker that gives organizations fine-grained control over who can create and manage assets using specific templates. This feature enhances data governance by allowing teams to enforce usage policies that align with business and security requirements across the organization.

Accelerate your analytics with Amazon S3 Tables and Amazon SageMaker Lakehouse
Amazon SageMaker Lakehouse is a unified, open, and secure data lakehouse that now seamlessly integrates with Amazon S3 Tables, the first cloud object store with built-in Apache Iceberg support. In this post, we guide you how to use various analytics services using the integration of SageMaker Lakehouse with S3 Tables.

Streamline data discovery with precise technical identifier search in Amazon SageMaker Unified Studio
We’re excited to introduce a new enhancement to the search experience in Amazon SageMaker Catalog, part of the next generation of Amazon SageMaker—exact match search using technical identifiers. In this post, we demonstrate how to streamline data discovery with precise technical identifier search in Amazon SageMaker Unified Studio.