AWS Big Data Blog
Category: Amazon Elastic Kubernetes Service

Optimize traffic costs of Amazon MSK consumers on Amazon EKS with rack awareness
In this post, we walk you through a solution for implementing rack awareness in consumer applications that are dynamically deployed across multiple Availability Zones using Amazon EKS.

Use Batch Processing Gateway to automate job management in multi-cluster Amazon EMR on EKS environments
AWS customers often process petabytes of data using Amazon EMR on EKS. In enterprise environments with diverse workloads or varying operational requirements, customers frequently choose a multi-cluster setup due to the following advantages: Better resiliency and no single point of failure – If one cluster fails, other clusters can continue processing critical workloads, maintaining business […]

How ZS built a clinical knowledge repository for semantic search using Amazon OpenSearch Service and Amazon Neptune
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. This platform is an advanced information retrieval system engineered to assist healthcare professionals and researchers in navigating vast repositories of medical documents, medical literature, research articles, clinical guidelines, protocol documents, […]

Introducing Amazon EMR on EKS with Apache Flink: A scalable, reliable, and efficient data processing platform
AWS recently announced that Apache Flink is generally available for Amazon EMR on Amazon Elastic Kubernetes Service (EKS). Apache Flink is a scalable, reliable, and efficient data processing framework that handles real-time streaming and batch workloads (but is most commonly used for real-time streaming). Amazon EMR on EKS is a deployment option for Amazon EMR […]
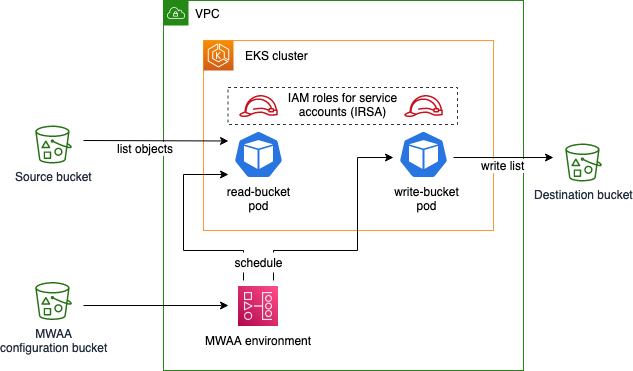
Set up fine-grained permissions for your data pipeline using MWAA and EKS
This blog post shows how to improve security in a data pipeline architecture based on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Kubernetes Service (Amazon EKS) by setting up fine-grained permissions, using HashiCorp Terraform for infrastructure as code.

Introducing Amazon EMR on EKS job submission with Spark Operator and spark-submit
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]

How SOCAR handles large IoT data with Amazon MSK and Amazon ElastiCache for Redis
This is a guest blog post co-written with SangSu Park and JaeHong Ahn from SOCAR. As companies continue to expand their digital footprint, the importance of real-time data processing and analysis cannot be overstated. The ability to quickly measure and draw insights from data is critical in today’s business landscape, where rapid decision-making is key. […]

Build event-driven data pipelines using AWS Controllers for Kubernetes and Amazon EMR on EKS
An event-driven architecture is a software design pattern in which decoupled applications can asynchronously publish and subscribe to events via an event broker. By promoting loose coupling between components of a system, an event-driven architecture leads to greater agility and can enable components in the system to scale independently and fail without impacting other services. […]

Run fault tolerant and cost-optimized Spark clusters using Amazon EMR on EKS and Amazon EC2 Spot Instances
Amazon EMR on EKS is a deployment option in Amazon EMR that allows you to run Spark jobs on Amazon Elastic Kubernetes Service (Amazon EKS). Amazon Elastic Compute Cloud (Amazon EC2) Spot Instances save you up to 90% over On-Demand Instances, and is a great way to cost optimize the Spark workloads running on Amazon […]

Introducing ACK controller for Amazon EMR on EKS
AWS Controllers for Kubernetes (ACK) was announced in August, 2020, and now supports 14 AWS service controllers as generally available with an additional 12 in preview. The vision behind this initiative was simple: allow Kubernetes users to use the Kubernetes API to manage the lifecycle of AWS resources such as Amazon Simple Storage Service (Amazon […]