Artificial Intelligence
Accelerate Generative AI Inference on Amazon SageMaker AI with G7e Instances
As the demand for generative AI continues to grow, developers and enterprises seek more flexible, cost-effective, and powerful accelerators to meet their needs. Today, we are thrilled to announce the availability of G7e instances powered by NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs on Amazon SageMaker AI.
You can provision nodes with 1, 2, 4, and 8 RTX PRO 6000 GPU instances, with each GPU providing 96 GB of GDDR7 memory. This launch provides the capability to use a single-node GPU, G7e.2xlarge instance to host powerful open source foundation models (FMs) like GPT-OSS-120B, Nemotron-3-Super-120B-A12B (NVFP4 variant), and Qwen3.5-35B-A3B, offering organizations a cost-effective and high-performing option. This makes it well suited for those looking to improve costs while maintaining high performance for inference workloads. The key highlights for G7e instances include:
- Twice the GPU memory compared to G6e instances, enabling deployment of large language models (LLMs) in FP16 up to:
- 35B parameter model on a single GPU node (G7e.2xlarge)
- 150B parameter model on a 4 GPU node (G7e.24xlarge)
- 300B parameter model on an 8 GPU node (G7e.48xlarge)
- Up to 1600 Gbps of networking throughput
- Up to 768 GB GPU Memory on G7e.48xlarge
Amazon Elastic Compute Cloud (Amazon EC2) G7e instances represent a significant leap in GPU-accelerated inference on the cloud. They deliver up to 2.3x inference performance compared to the previous-generation G6e instances. Each G7e GPU provides 1,597 GB/s bandwidth, doubling the per-GPU memory of G6e and quadrupling that of G5. Networking scales to 1,600 Gbps with EFA on the largest G7e size—a 4x jump over G6e and 16x over G5—unlocking low-latency multi-node inference and fine-tuning scenarios that were previously impractical on G-series instances. The following table summarizes the generational progression at the 8-GPU tier:
| Spec | G5 (g5.48xlarge) | G6e (g6e.48xlarge) | G7e (g7e.48xlarge) |
| GPU | 8x NVIDIA A10G | 8x NVIDIA L40S | 8x NVIDIA RTX PRO 6000 Blackwell |
| GPU Memory per GPU | 24 GB GDDR6 | 48 GB GDDR6 | 96 GB GDDR7 |
| Total GPU Memory | 192 GB | 384 GB | 768 GB |
| GPU Memory Bandwidth | 600 GB/s per GPU | 864 GB/s per GPU | 1,597 GB/s per GPU |
| vCPUs | 192 | 192 | 192 |
| System Memory | 768 GiB | 1,536 GiB | 2,048 GiB |
| Network Bandwidth | 100 Gbps | 400 Gbps | 1,600 Gbps (EFA) |
| Local NVMe Storage | 7.6 TB | 7.6 TB | 15.2 TB |
| Inference vs. G6e | Baseline | ~1x | Up to 2.3x |
With 768 GB of aggregate GPU memory on a single instance, G7e can host models that previously required multi-node setups on G5 or G6e, reducing operational complexity and inter-node latency. Combined with support for FP4 precision using fifth-generation Tensor Cores and NVIDIA GPUDirect RDMA over EFAv4, G7e instances are positioned as the go-to choice for deploying LLMs, multimodal AI, and agentic inference workloads on AWS.
Use cases well suited for G7e
G7e’s combination of memory density, bandwidth, and networking capabilities makes it well suited for a broad range of modern generative AI workloads:
- Chatbots and conversational AI – G7e’s low TTFT and high throughput keep interactive experiences responsive even under heavy concurrent load.
- Agentic and tool-calling workflows – The 4x improvement in CPU-to-GPU bandwidth makes G7e particularly effective for Retrieval Augmented Generation (RAG) pipelines and agentic workflows where fast context injection from retrieval stores is critical.
- Text generation, summarization, and long-context inference – G7e’s 96 GB per-GPU memory accommodates large KV caches for extended document contexts—reducing truncation and enabling richer reasoning over long inputs.
- Image generation and vision models – Where earlier instances encounter out-of-memory errors on larger multimodal models, G7e’s doubled memory resolves these limitations cleanly.
- Physical AI and scientific computing – G7e’s Blackwell-generation compute, FP4 support, and spatial computing capabilities (DLSS 4.0, 4th-gen RT cores) extend its applicability to digital twins, 3D simulation, and physical AI model inference.
Deployment walkthrough
Prerequisites
To try this solution using SageMaker AI, you need the following prerequisites:
- An AWS account that will contain all your AWS resources.
- An AWS Identity and Access Management (IAM) role to access Amazon SageMaker AI. To learn more about how IAM works with SageMaker AI, see Identity and Access Management for Amazon SageMaker AI.
- Access to Amazon SageMaker Studio or a SageMaker notebook instance, or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using Amazon SageMaker Studio for straightforward deployment and inference.
- Quota for one instance of ml.g7e.2xlarge [or larger] for Amazon SageMaker AI endpoint usage. You can request a quota increase through the Service Quotas console.
Deployment
You can clone the repository and use the sample notebook provided here.
Performance benchmarks
To quantify the generational improvement, we benchmarked Qwen3-32B (BF16) on both G6e and G7e instances using the same workload: ~1,000 input tokens and ~560 output tokens per request. This is representative of document summarization or correction tasks. Both configurations use the native vLLM container with prefix caching enabled.
The benchmarking suite used to produce these results is available in the sample Jupyter notebook. It follows a three-step process: (1) deploy the model on a SageMaker AI endpoint using the native vLLM container, (2) load test at concurrency levels from 1–32 simultaneous requests, and (3) analyze the results to produce the following performance tables.
G6e Baseline: ml.g6e.12xlarge [4x L40S, $13.12/hr]
With 4x L40S GPUs and tensor parallelism degree 4, G6e delivers strong per-request throughput: 37.1 tok/s at single concurrency and 21.5 tok/s at C=32.
| C | Success | p50 (s) | p99 (s) | tok/s | RPS | Agg tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 16.1 | 16.3 | 37.1 | 0.07 | 37 | $38.09 |
| 8 | 100% | 19.8 | 20.2 | 30.3 | 0.42 | 242 | $5.85 |
| 16 | 100% | 23.1 | 23.5 | 26.0 | 0.73 | 416 | $3.41 |
| 32 | 100% | 26.0 | 29.2 | 21.5 | 1.21 | 686 | $2.06 |
G7e: ml.g7e.2xlarge [1x RTX PRO 6000 Blackwell, $4.20/hr]
G7e runs the same 32B-parameter model on a single GPU with tensor parallelism degree 1. While per-request tok/s is lower than G6e’s 4-GPU configuration, the cost story is dramatically different.
| C | Success | p50 (s) | p99 (s) | tok/s | RPS | Agg tok/s | $/M tokens |
|---|---|---|---|---|---|---|---|
| 1 | 100% | 27.2 | 27.5 | 22.0 | 0.04 | 22 | $21.32 |
| 8 | 100% | 28.7 | 28.9 | 20.9 | 0.28 | 167 | $2.81 |
| 16 | 100% | 30.3 | 30.6 | 19.9 | 0.53 | 318 | $1.48 |
| 32 | 100% | 33.2 | 33.3 | 18.5 | 0.99 | 592 | $0.79 |
What the numbers tell us
At production concurrency (C=32), G7e achieves $0.79 per million output tokens, a 2.6x cost reduction compared to G6e’s $2.06. This is driven by two factors: G7e’s significantly lower hourly rate ($4.20 vs $13.12) and its ability to maintain consistent throughput under load.G7e’s single-GPU architecture also scales more gracefully. Latency increases 22% from C=1 to C=32 (27.2s to 33.2s), compared to 62% for G6e (16.1s to 26.0s). With tensor parallelism degree 1, there is:
- No inter-GPU synchronization overhead
- No all-reduce operations at every transformer layer
- No cross-GPU KV cache fragmentation
- No NVLink communication bottleneck
As concurrency rises and the GPU becomes more saturated, this absence of coordination overhead keeps latency predictable. For latency-sensitive workloads at low concurrency, G6e’s 4-GPU parallelism still delivers faster individual responses. For production deployments optimizing for cost per token at scale, G7e is the clear choice, and as we show in the next section, combining G7e with EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency) speculative decoding pushes the advantage even further.
Combined benchmarks: G7e + EAGLE speculative decoding
The hardware improvements from G7e are significant on their own but combining them with EAGLE speculative decoding produces compounding gains. EAGLE accelerates LLM decoding by predicting multiple future tokens from the model’s own hidden representations, then verifying them in a single forward pass. This produces identical output quality while generating multiple tokens per step. For a detailed walkthrough of EAGLE on SageMaker AI, including optimization job setup and the Base vs Trained EAGLE workflow, see Amazon SageMaker AI introduces EAGLE based adaptive speculative decoding to accelerate generative AI inference.
In this section, we measure the stacked improvement from baseline through G7e + EAGLE3 using Qwen3-32B in BF16. The benchmark workload uses ~1,000 input tokens and ~560 output tokens per request, representative of document summarization or correction tasks. EAGLE3 is enabled using a community-trained speculator (~1.56 GB) with num_speculative_tokens=4.
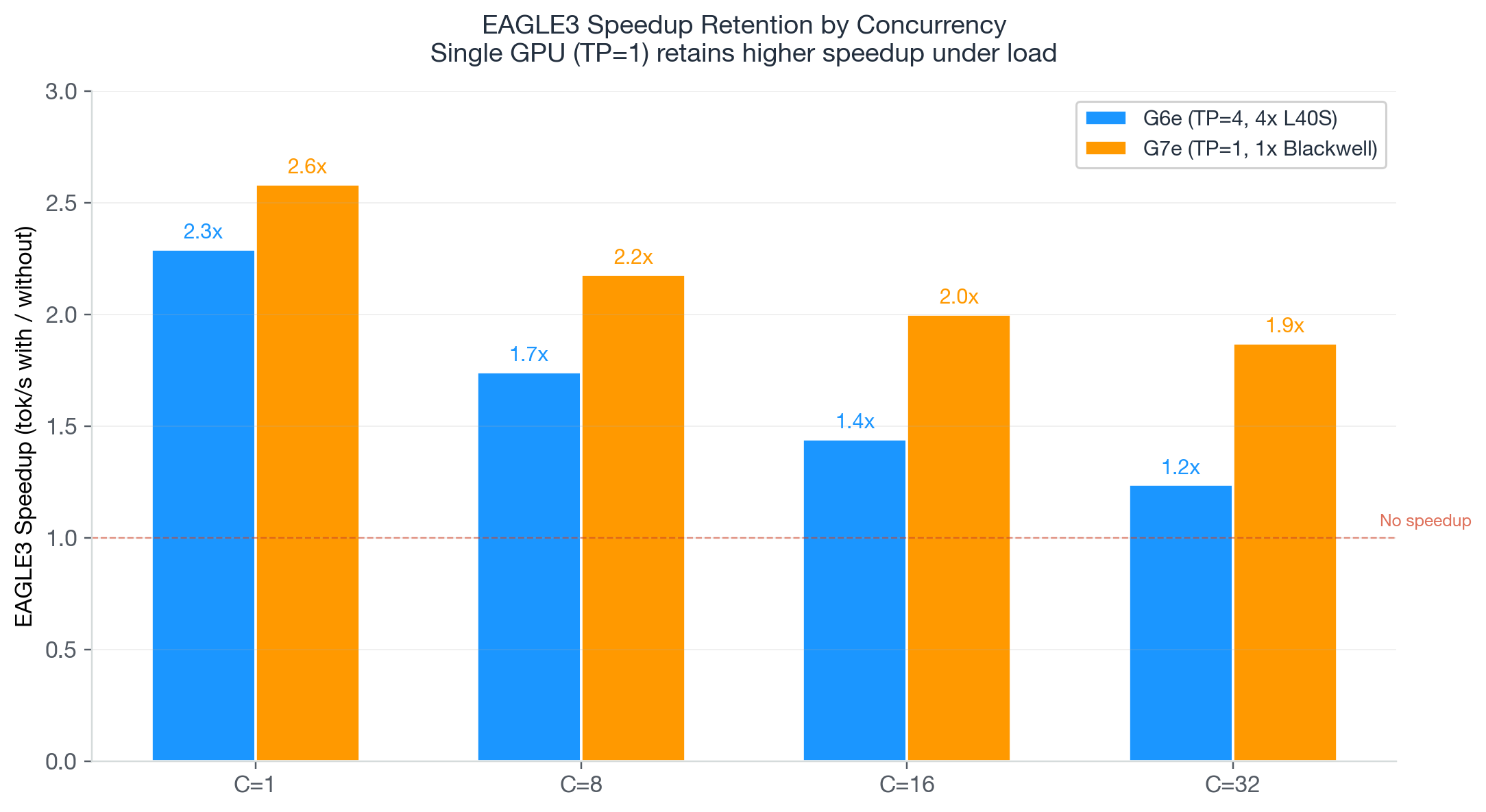
G7e + EAGLE3 delivers a 2.4x throughput improvement and 75% cost reduction over the previous-generation baseline. At $0.41 per million output tokens, it is also 4x cheaper than G6e + EAGLE3 ($1.72) despite offering higher throughput.
Enabling EAGLE3
For production deployments with fine-tuned models, the SageMaker AI EAGLE optimization toolkit can train custom EAGLE heads on your own data, further improving the speculative acceptance rate and throughput beyond what community speculators provide.
Pricing
G7e instances on Amazon SageMaker AI are billed at standard SageMaker AI inference pricing for the selected instance type and usage duration. There is no additional per-token or per-request fee for serving on G7e.
EAGLE optimization jobs run on SageMaker AI training instances and are billed at the standard SageMaker training instance rate for the job duration. The resulting improved model artifacts are stored in Amazon Simple Storage Service (Amazon S3) at standard storage rates. There is no additional charge for EAGLE-accelerated inference after the improved model is deployed. You only pay the standard endpoint instance cost.
The following table shows on-demand pricing for key G7e, G6e, and G5 instance sizes in US East (N. Virginia) for reference. G7e rows are highlighted.
| Instance | GPUs | GPU Memory | Typical Use Case |
| ml.g5.2xlarge | 1 | 24 GB | Small LLMs (≤7B FP16); dev and test |
| ml.g5.48xlarge | 8 | 192 GB | Large multi-GPU LLM serving on G5 |
| ml.g6e.2xlarge | 1 | 48 GB | Mid-size LLMs (≤14B FP16) |
| ml.g6e.12xlarge | 2 | 96 GB | Large LLMs (≤36B FP16); previous gen baseline |
| ml.g6e.48xlarge | 8 | 384 GB | Very large LLMs (≤90B FP16) |
| ml.g7e.2xlarge | 1 | 96 GB | Large LLMs (≤70B FP8) on a single GPU |
| ml.g7e.24xlarge | 4 | 384 GB | Very large LLMs; high-throughput serving |
| ml.g7e.48xlarge | 8 | 768 GB | Maximum throughput; largest models |
You can also reduce inference costs with Amazon SageMaker Savings Plans, which offer discounts of up to 64% in exchange for a commitment to a consistent usage amount. These are well suited for production inference endpoints with predictable traffic.
Clean up
To avoid incurring unnecessary charges after completing your testing, delete the SageMaker endpoints created during the walkthrough. You can do this through the SageMaker AI console or with the Python SDK as shown in the Amazon SageMaker AI Developer Guide.
If you ran an EAGLE optimization job, also delete the output artifacts from Amazon S3 to avoid ongoing storage charges.
Conclusion
G7e instances on Amazon SageMaker AI represent the next significant leap in cost-effective generative AI inference. The Blackwell GPU architecture delivers 2x memory per GPU, 1.85x memory bandwidth, and up to 2.3x inference performance over G6e. This enables previously multi-GPU workloads to run efficiently on a single GPU and raising the throughput ceiling for every GPU configuration. Combined with the EAGLE speculative decoding of SageMaker AI, the improvements compound further. EAGLE’s memory-bandwidth-bound acceleration benefits directly from G7e’s increased bandwidth, while G7e’s larger memory capacity allows EAGLE draft heads to co-exist with larger models without memory pressure. Together, the hardware and software improvements deliver throughput gains that translate directly into lower cost per output token at scale.
The progression from G5 to G6e to G7e, layered with EAGLE optimization, represents a nearly continuous hardware-software co-optimization path, one that keeps improving as models evolve, and production traffic data is captured and fed back into EAGLE retraining.