Artificial Intelligence
Bring your own ML model into Amazon SageMaker Canvas and generate accurate predictions
Machine learning (ML) helps organizations generate revenue, reduce costs, mitigate risk, drive efficiencies, and improve quality by optimizing core business functions across multiple business units such as marketing, manufacturing, operations, sales, finance, and customer service. With AWS ML, organizations can accelerate the value creation from months to days. Amazon SageMaker Canvas is a visual, point-and-click service that allows business analysts to generate accurate ML predictions without writing a single line of code or requiring ML expertise. You can use models to make predictions interactively and for batch scoring on bulk datasets.
In this post, we showcase architectural patterns on how business teams can use ML models built anywhere by generating predictions in Canvas and achieve effective business outcomes.
This integration of model development and sharing creates a tighter collaboration between business and data science teams and lowers time to value. Business teams can use existing models built by their data scientists or other departments to solve a business problem instead of rebuilding new models in outside environments.
Finally, business analysts can import shared models into Canvas and generate predictions before deploying to production with just a few clicks.
Solution overview
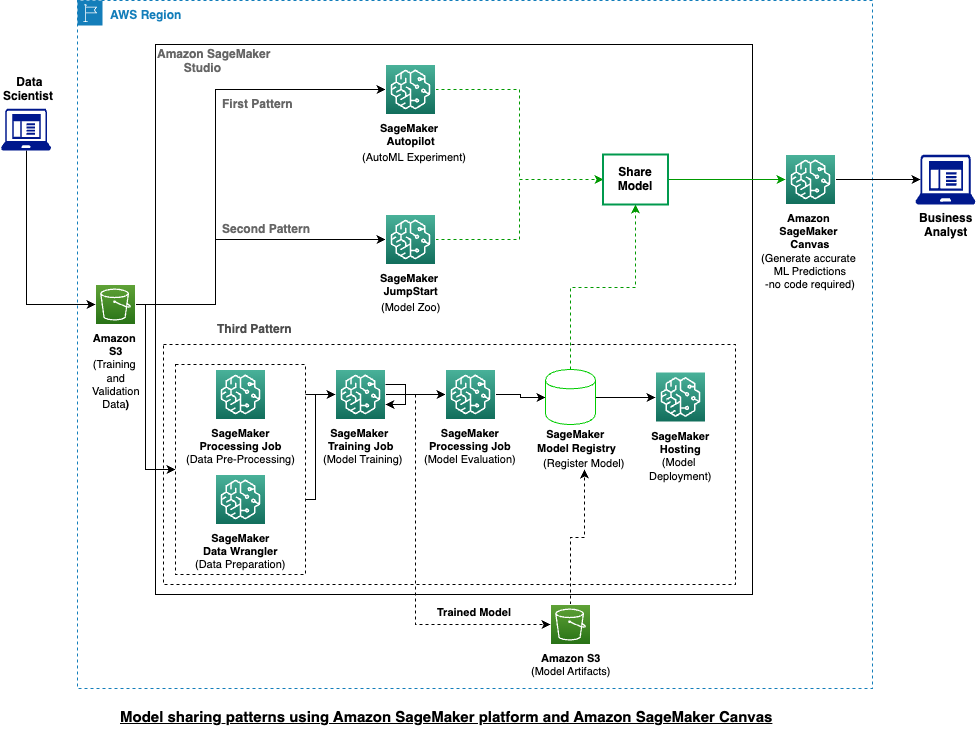
The following figure describes three different architecture patterns to demonstrate how data scientists can share models with business analysts, who can then directly generate predictions from those models in the visual interface of Canvas:
- Use Amazon SageMaker Autopilot and Canvas
- Use Amazon SageMaker JumpStart and Canvas
- Use SageMaker model registry and Canvas
Prerequisites
To train and build your model using SageMaker and bring your model into Canvas, complete the following prerequisites:
- If you don’t already have a SageMaker domain and Studio user, set up and onboard a Studio user to a SageMaker domain.
- Enable and set up Canvas base permissions for your users and grant users permissions to collaborate with Studio.
- You must have a trained model from Autopilot, JumpStart, or the model registry. For any model that you’ve built outside of SageMaker, you must register your model in the model registry before importing it into Canvas.
Now let’s assume the role of a data scientist who is looking to train, build, deploy, and share ML models with a business analyst for each of these three architectural patterns.
Use Autopilot and Canvas
Autopilot automates key tasks of an automatic ML (AutoML) process like exploring data, selecting the relevant algorithm for the problem type, and then training and tuning it. All of this can be achieved while allowing you to maintain full control and visibility on the dataset. Autopilot automatically explores different solutions to find the best model, and users can either iterate on the ML model or directly deploy the model to production with one click.
In this example, we use a customer churn synthetic dataset from the telecom domain and are tasked with identifying customers that are potentially at risk of churning. Complete the following steps to use Autopilot AutoML to build, train, deploy, and share an ML model with a business analyst:
- Download the dataset, upload it to an Amazon S3 (Amazon Simple Storage Service) bucket, and make a note of the S3 URI.
- On the Studio console, choose AutoML in the navigation pane.
- Choose Create AutoML experiment.
- Specify the experiment name (for this post,
Telecom-Customer-Churn-AutoPilot), S3 data input, and output location. - Set the target column as churn.
- In the deployment settings, you can enable the auto deploy option to create an endpoint that deploys your best model and runs inference on the endpoint.
For more information, refer to Create an Amazon SageMaker Autopilot experiment.

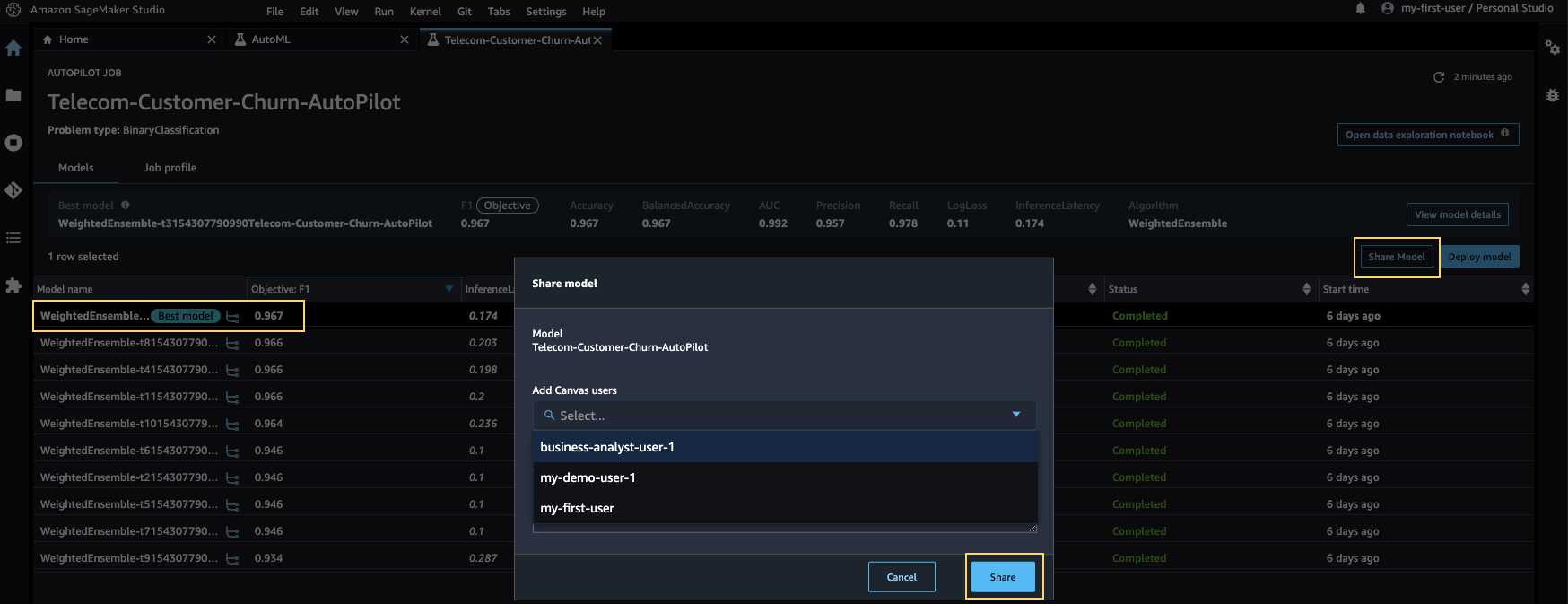
- Choose your experiment, then select your best model and choose Share model.
- Add a Canvas user and choose Share to share the model.
(Note: You can’t share model with the same Canvas user as used for Studio login. For example, Studio user-A can’t share model with Canvas User-A. But user-A can share model with user-B, hence choose different uses for model-sharing)
For more information, refer to Studio users: Share a model to SageMaker Canvas.
Use JumpStart and Canvas
JumpStart is an ML hub that provides pre-trained, open-source models for a wide range of ML use cases like fraud detection, credit risk prediction, and product defect detection. You can deploy more than 300 pre-trained models for tabular, vision, text, and audio data.
For this post, we use a LightGBM regression pre-trained model from JumpStart. We train the model on a custom dataset and share the model with a Canvas user (business analyst). The pre-trained model can be deployed to an endpoint for inference. JumpStart provides an example notebook to access the model after it is deployed.
In this example, we use the abalone dataset. The dataset contains examples of eight physical measurements such as length, diameter, and height to predict the age of abalone (a regression problem).
- Download the abalone dataset from Kaggle.
- Create an S3 bucket and upload the train, validation, and custom header datasets.
- On the Studio console, under SageMaker JumpStart in the navigation pane, choose Models, notebooks, solutions.
- Under Tabular Models, choose LightGBM Regression.

- Under Train Model, specify the S3 URIs for the training, validation, and column header datasets.
- Choose Train.

- In the navigation pane, choose Launched JumpStart assets.
- On the Training jobs tab, choose your training job.

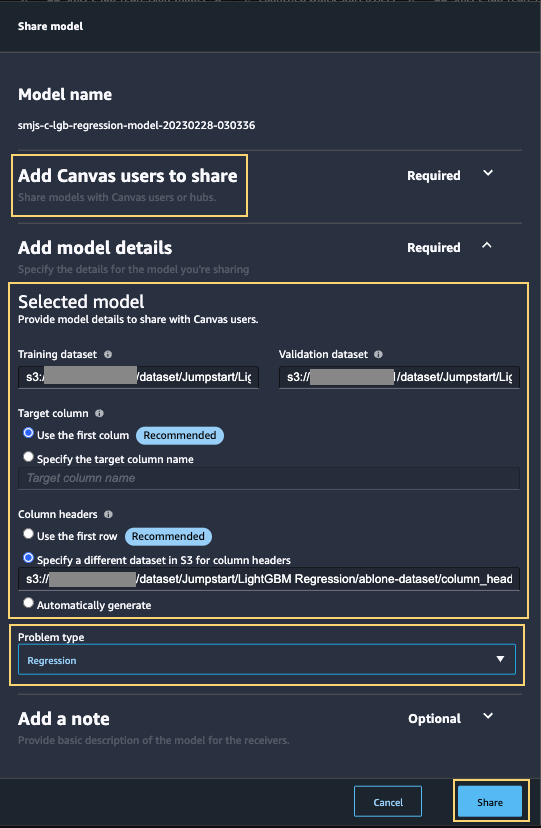
- On the Share menu, choose Share to Canvas.

- Choose the Canvas users to share with, specify the model details, and choose Share.
For more information, refer to Studio users: Share a model to SageMaker Canvas.
Use SageMaker model registry and Canvas
With SageMaker model registry, you can catalog models for production, manage model versions, associate metadata, manage the approval status of a model, deploy models to production, and automate model deployment with CI/CD.
Let’s assume the role of a data scientist. For this example, you’re building an end-to-end ML project that includes data preparation, model training, model hosting, model registry, and model sharing with a business analyst. Optionally, for data preparation and preprocessing or postprocessing steps, you can use Amazon SageMaker Data Wrangler and an Amazon SageMaker Processing job. In this example, we use the abalone dataset downloaded from LIBSVM. The target variable is the age of abalone.
- In Studio, clone the GitHub repo.
- Complete the steps listed in the README file.
- On the Studio console, under Models in the navigation pane, choose Model registry.
- Choose the model
sklearn-reg-ablone.

- Share model version 1 from the model registry to Canvas.
- Choose the Canvas users to share with, specify the model details, and choose Share.
For instructions, refer to the Model Registry section in Studio users: Share a model to SageMaker Canvas.

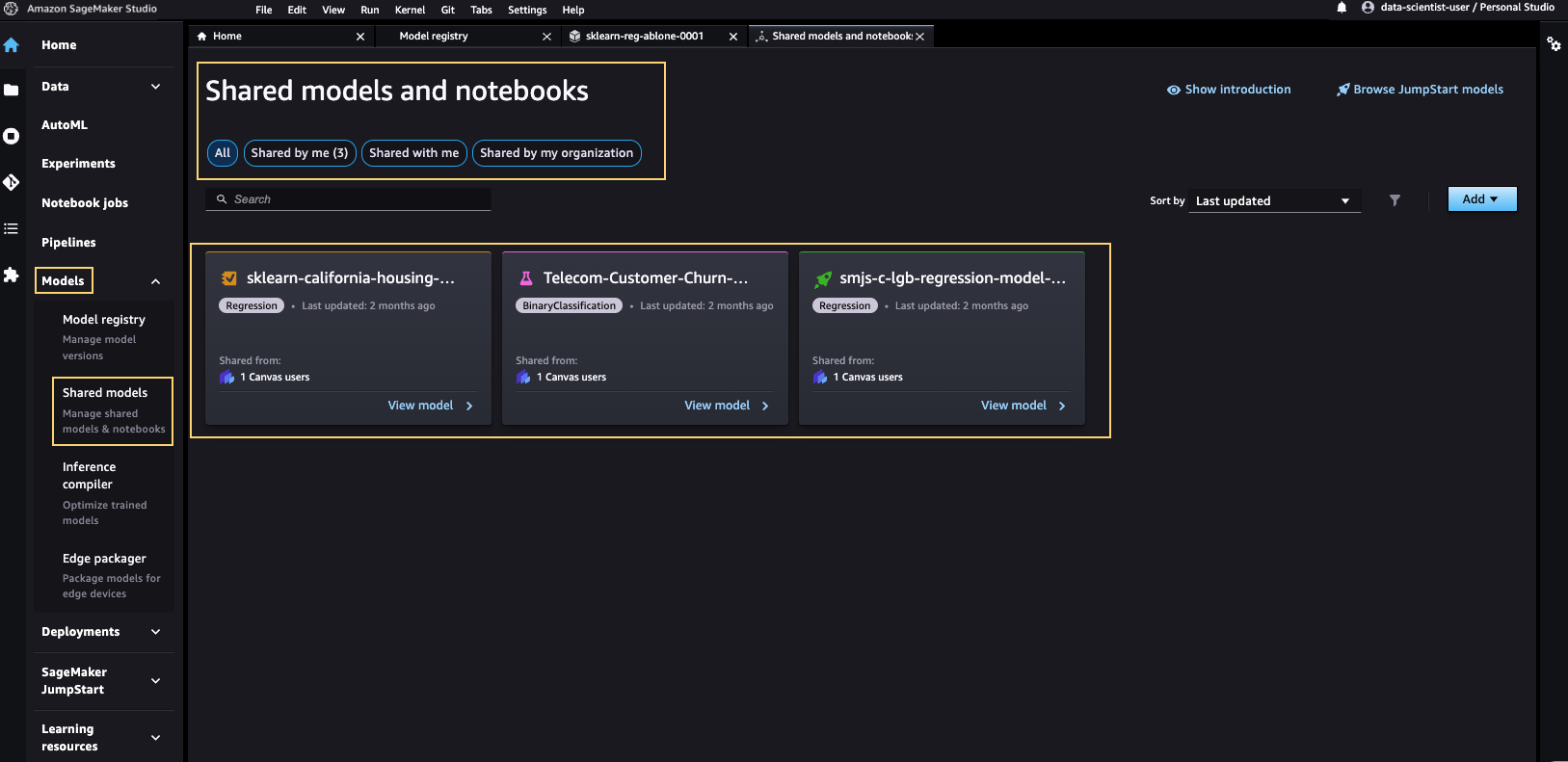
Manage shared models
After you share the model using any of the preceding methods, you can go to the Models section in Studio and review all shared models. In the following screenshot, we see 3 different models shared by a Studio user (data scientist) with different Canvas users (business teams).
Import a shared model and make predictions with Canvas
Let’s assume the role of business analyst and log in to Canvas with your Canvas user.
When a data scientist or Studio user shares a model with a Canvas user, you receive a notification within the Canvas application that a Studio user has shared a model with you. In the Canvas application, the notification is similar to the following screenshot.

You can choose View update to see the shared model, or you can go to the Models page in the Canvas application to discover all the models that have been shared with you. The model import from Studio can take up to 20 minutes.

After importing the model, you can view its metrics and generate real-time predictions with what-if analysis or batch predictions.
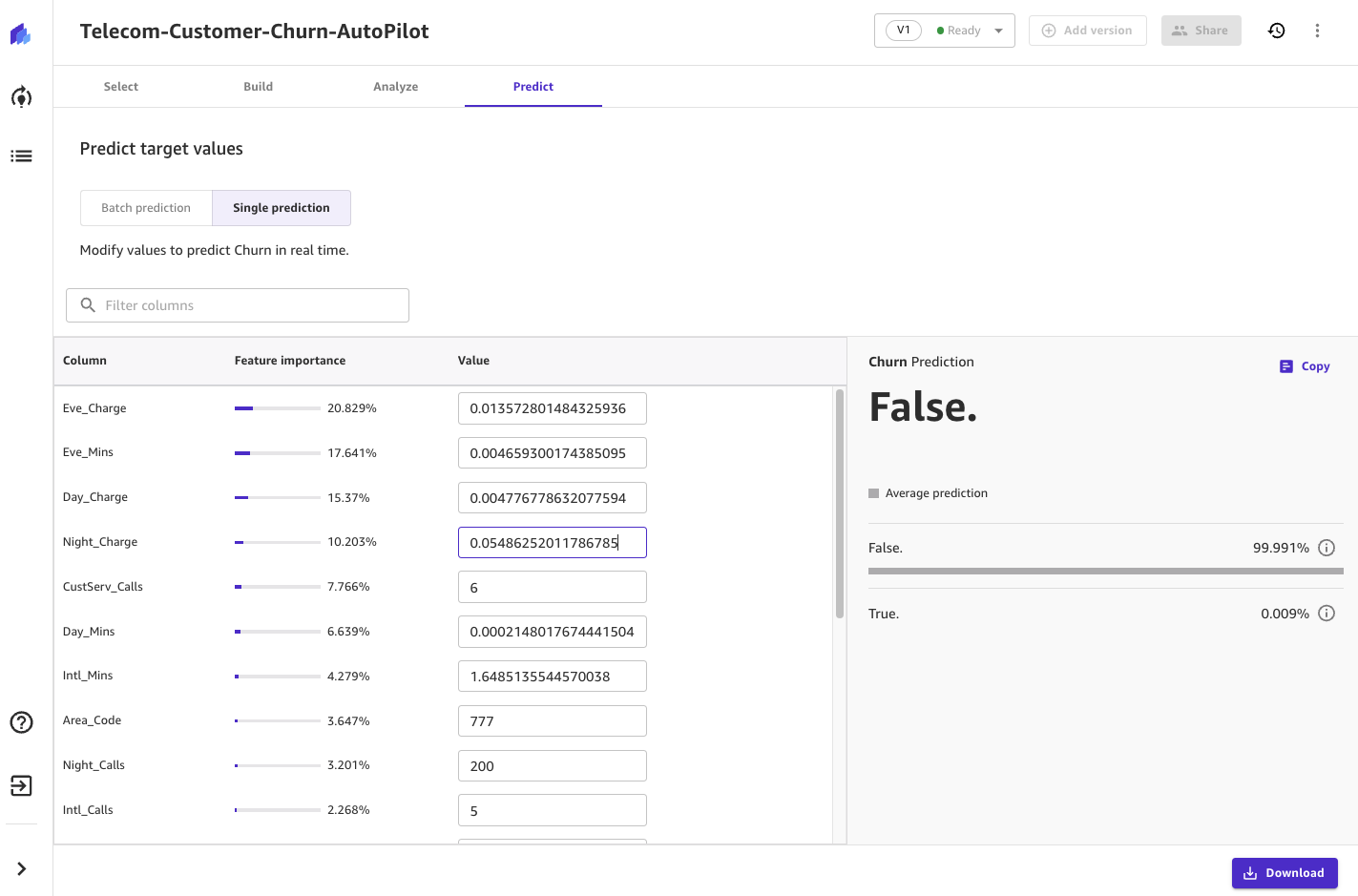
Considerations
Keep in mind the following when sharing models with Canvas:
- You store training and validation datasets in Amazon S3, and the S3 URIs are passed to Canvas with AWS Identity and Access Management (IAM) permissions.
- Provide the target column to Canvas or use the first column as default.
- For a Canvas container to parse inference data, the Canvas endpoint accepts either text (CSV) or application (JSON).
- Canvas doesn’t support multiple container or inference pipelines.
- A data schema is provided to Canvas if no headers are provided in the training and validation datasets. By default, the JumpStart platform doesn’t provide headers in the training and validation datasets.
- With Jumpstart, the training job needs to be complete before you can share it with Canvas.
Refer to Limitations and troubleshooting to help you troubleshoot any issues you encounter when sharing models.
Clean up
To avoid incurring future charges, delete or shut down the resources you created while following this post. Refer to Logging out of Amazon SageMaker Canvas for more details. Shut down the individual resources, including notebooks, terminal, kernels, apps and instances. For more information, refer to Shut Down Resources. Delete the model version, SageMaker endpoint and resources, Autopilot experiment resources, and S3 bucket.
Conclusion
Studio allows data scientists to share ML models with business analysts in a few simple steps. Business analysts can benefit from ML models already built by data scientists to solve business problems instead of creating a new model in Canvas. However, it might be difficult to use these models outside the environments in which they are built due to technical requirements and manual processes to import models. This often forces users to rebuild ML models, resulting in the duplication of effort and additional time and resources. Canvas removes these limitations so you can generate predictions in Canvas with models that you have trained anywhere. By using the three patterns illustrated in this post, you can register ML models in the SageMaker model registry, which is a metadata store for ML models, and import them into Canvas. Business analysts can then analyze and generate predictions from any model in Canvas.
To learn more about using SageMaker services, check out the following resources:
- Getting started with using Amazon SageMaker Canvas
- Launch Amazon SageMaker Studio
- Get started with Amazon SageMaker Autopilot
- Get Started with Data Wrangler
- SageMaker JumpStart
- Register and Deploy Models with Model Registry
If you have questions or suggestions, leave a comment.
About the authors
 Aman Sharma is a Senior Solutions Architect With AWS. He works with start-ups, small and medium businesses, and enterprise customers across the APJ region, more than 19 years of experience in consulting, architecting, and solutioning. He is passionate about democratizing AI and ML and helping customers in designing their data and ML strategies. Outside work, he likes to explore nature and wildlife.
Aman Sharma is a Senior Solutions Architect With AWS. He works with start-ups, small and medium businesses, and enterprise customers across the APJ region, more than 19 years of experience in consulting, architecting, and solutioning. He is passionate about democratizing AI and ML and helping customers in designing their data and ML strategies. Outside work, he likes to explore nature and wildlife.
 Zichen Nie is the Senior Software Engineer at AWS SageMaker leading the project Bring Your Own Model to SageMaker Canvas last year. She has been working in Amazon for more than 7 years and has experience in both Amazon Supply Chain Optimization and AWS AI services. She enjoys Barre workouts and music after work.
Zichen Nie is the Senior Software Engineer at AWS SageMaker leading the project Bring Your Own Model to SageMaker Canvas last year. She has been working in Amazon for more than 7 years and has experience in both Amazon Supply Chain Optimization and AWS AI services. She enjoys Barre workouts and music after work.