Artificial Intelligence
Category: Analytics
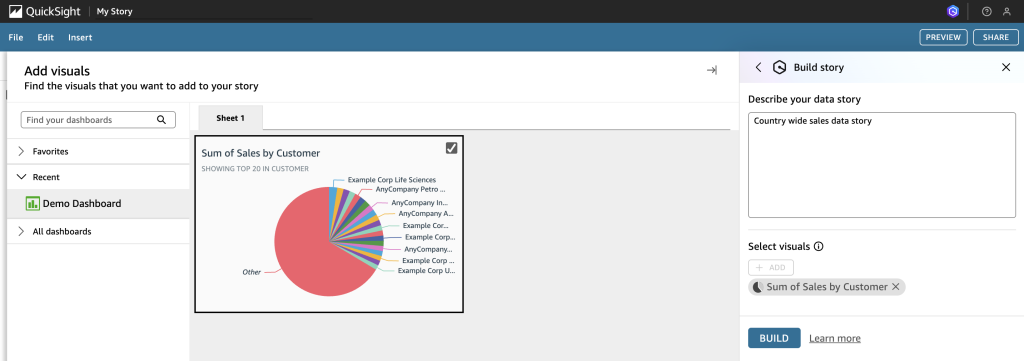
Automate Amazon QuickSight data stories creation with agentic AI using Amazon Nova Act
In this post, we demonstrate how Amazon Nova Act automates QuickSight data story creation, saving time so you can focus on making critical, data-driven business decisions.
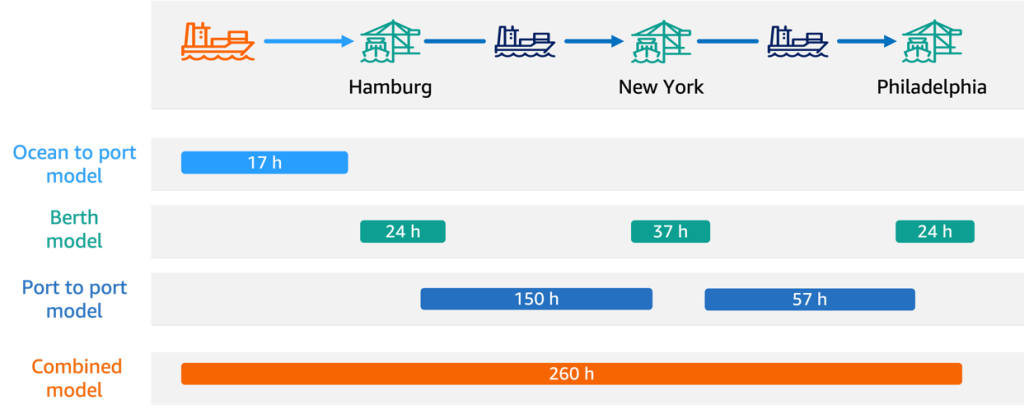
How Hapag-Lloyd improved schedule reliability with ML-powered vessel schedule predictions using Amazon SageMaker
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced its schedule reliability—a key performance indicator in the industry and quality promise to their customers.

Rapid ML experimentation for enterprises with Amazon SageMaker AI and Comet
In this post, we showed how to use SageMaker and Comet together to spin up fully managed ML environments with reproducibility and experiment tracking capabilities.

Build Agentic Workflows with OpenAI GPT OSS on Amazon SageMaker AI and Amazon Bedrock AgentCore
In this post, we show how to deploy gpt-oss-20b model to SageMaker managed endpoints and demonstrate a practical stock analyzer agent assistant example with LangGraph, a powerful graph-based framework that handles state management, coordinated workflows, and persistent memory systems.
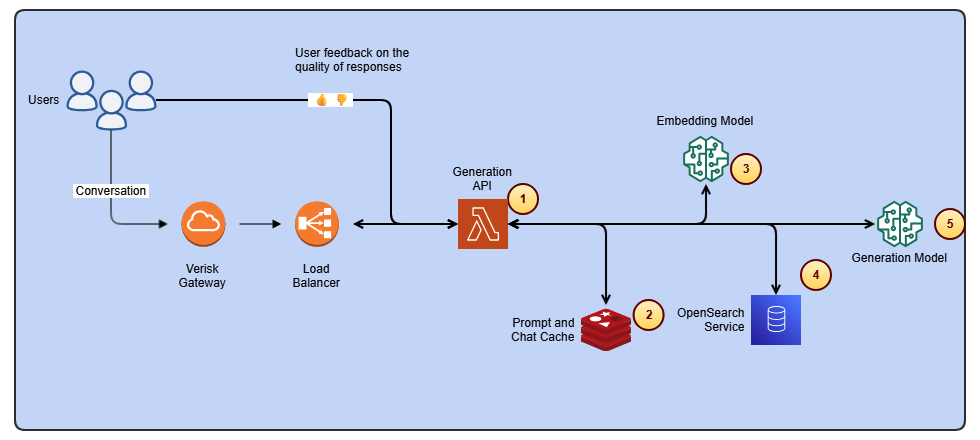
Streamline access to ISO-rating content changes with Verisk rating insights and Amazon Bedrock
In this post, we dive into how Verisk Rating Insights, powered by Amazon Bedrock, large language models (LLM), and Retrieval Augmented Generation (RAG), is transforming the way customers interact with and access ISO ERC changes.
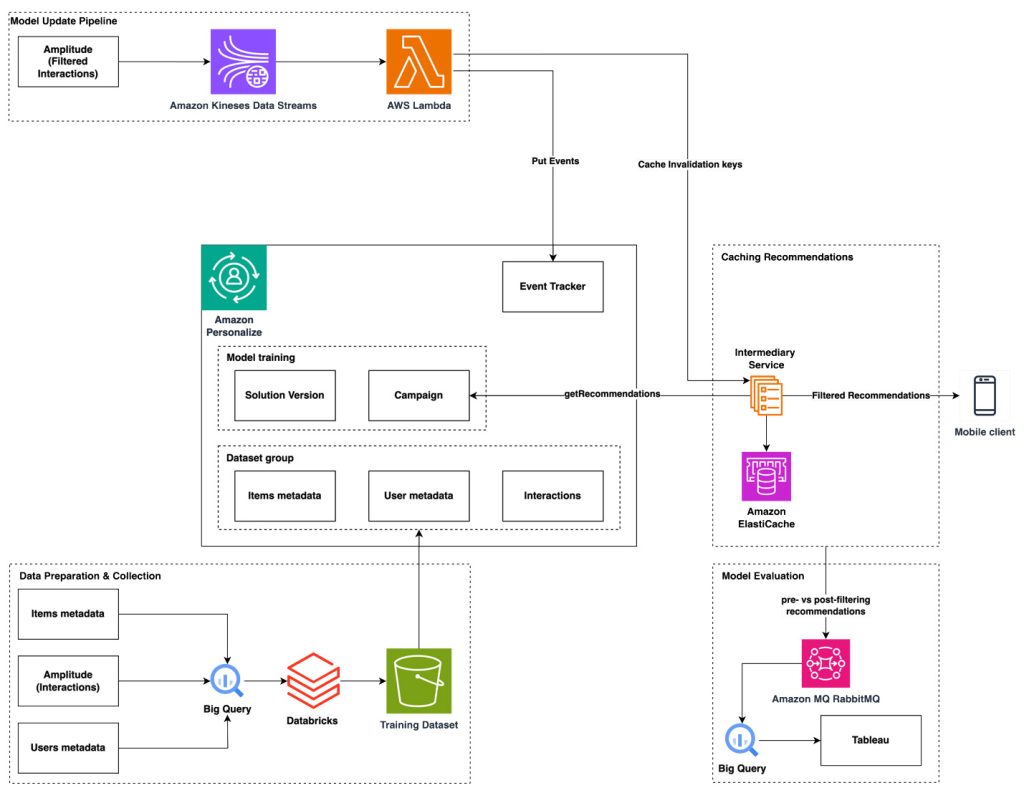
The power of AI in driving personalized product discovery at Snoonu
In this post, we share how Snoonu, a leading ecommerce platform in the Middle East, transformed their product discovery experience using AI-powered personalization. In this post, we share how Snoonu, a leading ecommerce platform in the Middle East, transformed their product discovery experience using AI-powered personalization.
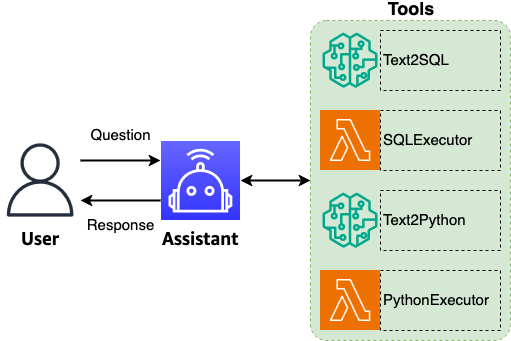
Natural language-based database analytics with Amazon Nova
In this post, we explore how natural language database analytics can revolutionize the way organizations interact with their structured data through the power of large language model (LLM) agents. Natural language interfaces to databases have long been a goal in data management. Agents enhance database analytics by breaking down complex queries into explicit, verifiable reasoning steps and enabling self-correction through validation loops that can catch errors, analyze failures, and refine queries until they accurately match user intent and schema requirements.

Deploy Amazon Bedrock Knowledge Bases using Terraform for RAG-based generative AI applications
In this post, we demonstrated how to automate the deployment of Amazon Knowledge Bases for RAG applications using Terraform.
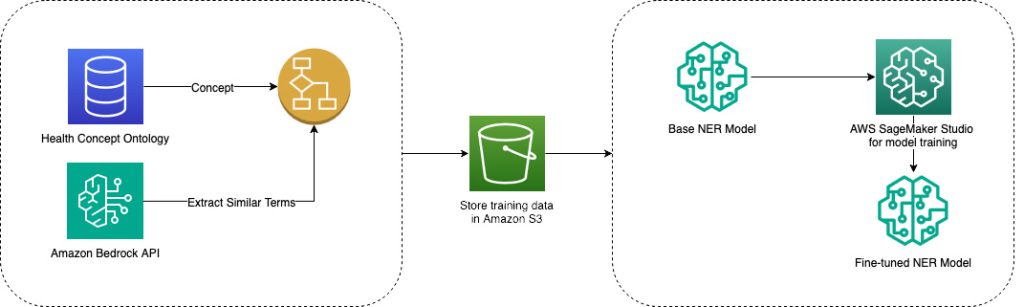
Learn how Amazon Health Services improved discovery in Amazon search using AWS ML and gen AI
In this post, we show you how Amazon Health Services (AHS) solved discoverability challenges on Amazon.com search using AWS services such as Amazon SageMaker, Amazon Bedrock, and Amazon EMR. By combining machine learning (ML), natural language processing, and vector search capabilities, we improved our ability to connect customers with relevant healthcare offerings.

Speed up delivery of ML workloads using Code Editor in Amazon SageMaker Unified Studio
In this post, we walk through how you can use the new Code Editor and multiple spaces support in SageMaker Unified Studio. The sample solution shows how to develop an ML pipeline that automates the typical end-to-end ML activities to build, train, evaluate, and (optionally) deploy an ML model.