Artificial Intelligence
Category: Learning Levels

From data overload to actionable insights: How Verizon Connect scaled agentic AI to 100,000 users
In this post, we show you how Verizon Connect built and scaled an agentic AI solution to transform overwhelming fleet data into clear, actionable insights for 100,000 users daily. We walk you through the architectural decisions, implementation challenges, and measurable results that can guide your own data-to-insights transformation.

Technical deep dive: AgentCore payments and innovation in agentic commerce
Amazon Bedrock AgentCore payments is now available in preview, it provides instant payments to paid external services with no manual billing setup per provider, stablecoin support for cost-effective microtransactions that make sub-cent transactions economically viable, and configurable spending guardrails that give you fine-grained control over agent budgets and transaction limits. In this post, we walk you through a technical deep dive of AgentCore payments.

Build highly scalable serverless LangGraph multi-agent systems in AWS with Amazon Bedrock AgentCore
In this post, we provide a solution to build highly scalable, serverless multi-agent generative AI systems on AWS using LangGraph Agents as orchestrators integrated with Amazon Bedrock AgentCore Memory and Amazon Bedrock AgentCore Observability.

Build an enterprise observability solution for Amazon Quick
When hundreds to thousands of users are onboarded to an enterprise AI platform, business leaders and platform owners need visibility into who is using the platform, whether users are satisfied with the answers they receive, and which capabilities are driving the most engagement. Without a centralized observability solution, this data is scattered across multiple AWS […]

Amazon Nova Act is now HIPAA eligible
In this post, you will learn what Nova Act offers, how HIPAA eligibility applies to agentic AI, and how to get started.

Intelligent radiology workflow optimization with AI agents
Many healthcare organizations report that traditional worklist systems rely on rigid rules that ignore critical context, radiologist specialization, current workload, fatigue levels, and case complexity. This creates a persistent challenge: radiologists cherry-pick easier, higher-value cases while avoiding complex studies, leading to diagnostic delays and increased costs. Research across 62 hospitals analyzing 2.2 million studies found […]

Integrating AWS API MCP Server with Amazon Quick using Amazon Bedrock AgentCore Runtime
This post shows you how to use Amazon Bedrock AgentCore Runtime with Model Context Protocol (MCP) support to connect Amazon Quick with AWS services through the AWS API MCP Server, creating a conversational AI assistant that translates natural language into AWS Command Line Interface (AWS CLI) commands, without the need to switch between tools during critical moments.
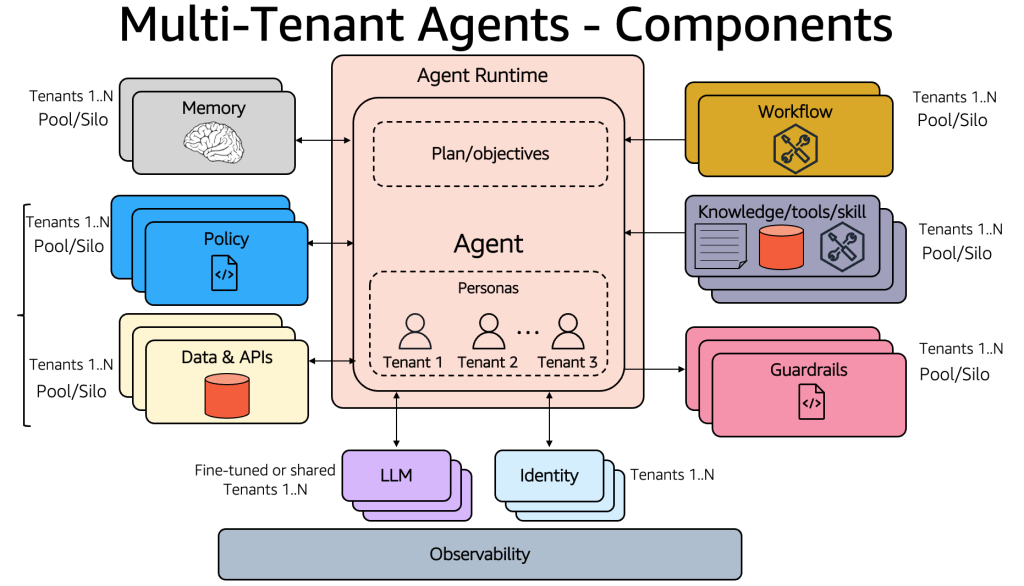
Building multi-tenant agents with Amazon Bedrock AgentCore
This post explores design considerations for architecting multi-tenant agentic applications and the framework needed to address SaaS architecture challenges with Amazon Bedrock AgentCore.

Break the context window barrier with Amazon Bedrock AgentCore
In this post, you will learn how to implement Recursive Language Models (RLM) using Amazon Bedrock AgentCore Code Interpreter and the Strands Agents SDK. By the end, you will know how to process documents of varying lengths, with no upper bound on context size, use Bedrock AgentCore Code Interpreter as persistent working memory for iterative document analysis, and orchestrate sub-large language model (sub-LLM) calls from within a sandboxed Python environment to analyze specific document sections.

Build AI agents for business intelligence with Amazon Bedrock AgentCore
In this post, we show you how OPLOG developed three AI agents using the Strands Agents SDK, deployed them to Amazon Bedrock AgentCore, and integrated Amazon Bedrock with Anthropic’s Claude Sonnet and Amazon Bedrock Knowledge Bases for Retrieval Augmented Generation (RAG).