Artificial Intelligence
Code-free machine learning: AutoML with AutoGluon, Amazon SageMaker, and AWS Lambda
One of AWS’s goals is to put machine learning (ML) in the hands of every developer. With the open-source AutoML library AutoGluon, deployed using Amazon SageMaker and AWS Lambda, we can take this a step further, putting ML in the hands of anyone who wants to make predictions based on data—no prior programming or data science expertise required.
AutoGluon automates ML for real-world applications involving image, text, and tabular datasets. AutoGluon trains multiple ML models to predict a particular feature value (the target value) based on the values of other features for a given observation. During training, the models learn by comparing their predicted target values to the actual target values available in the training data, using appropriate algorithms to improve their predictions accordingly. When training is complete, the resulting models can predict the target feature values for observations they have never seen before, even if you don’t know their actual target values.
AutoGluon automatically applies a variety of techniques to train models on data with a single high-level API call—you don’t need to build models manually. Based on a user-configurable evaluation metric, AutoGluon automatically selects the highest-performing combination, or ensemble, of models. For more information about how AutoGluon works, see Machine learning with AutoGluon, an open source AutoML library.
To get started with AutoGluon, see the AutoGluon GitHub repo. For more information about trying out sophisticated AutoML solutions in your applications, see the AutoGluon website. Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models efficiently. AWS Lambda lets you run code without provisioning or managing servers, can be triggered automatically by other AWS services like Amazon Simple Storage Service (Amazon S3), and allows you to build a variety of real-time data processing systems.
With AutoGluon, you can achieve state-of-the-art predictive performance on new observations with as few as three lines of Python code. In this post, we achieve the same results with zero lines of code—making AutoML accessible to non-developers—by using AWS services to deploy a pipeline that trains ML models and makes predictions on tabular data using AutoGluon. After deploying the pipeline in your AWS account, all you need to do to get state-of-the-art predictions on your data is upload it to an S3 bucket with a provided AutoGluon package.
The code-free ML pipeline
The pipeline starts with an S3 bucket, which is where you upload the training data that AutoGluon uses to build your models, the testing data you want to make predictions on, and a pre-made package containing a script that sets up AutoGluon. After you upload the data to Amazon S3, a Lambda function kicks off an Amazon SageMaker model training job that runs the pre-made AutoGluon script on the training data. When the training job is finished, AutoGluon’s best-performing model makes predictions on the testing data, and these predictions are saved back to the same S3 bucket. The following diagram illustrates this architecture.
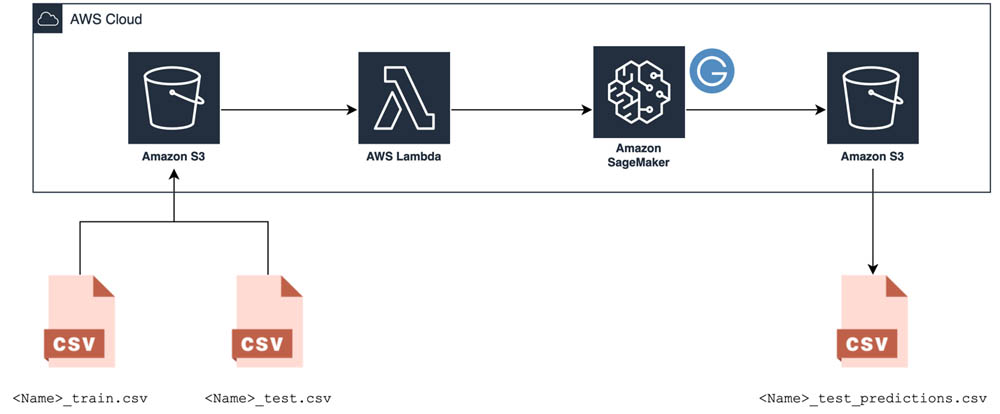
Deploying the pipeline with AWS CloudFormation
You can deploy this pipeline automatically in an AWS account using a pre-made AWS CloudFormation template. To get started, complete the following steps:
- Choose the AWS Region in which you’d like to deploy the template. If you’d like to deploy it in another region, please download the template from GitHub and upload it to CloudFormation yourself.
Northern Virginia 
Oregon Ireland Sydney - Sign in to the AWS Management Console.
- For Stack name, enter a name for your stack (for example,
code-free-automl-stack). - For BucketName, enter a unique name for your S3 bucket (for example,
code-free-automl-yournamehere). - For TrainingInstanceType, enter your compute instance.
This parameter controls the instance type Amazon SageMaker model training jobs use to run AutoGluon on your data. AutoGluon is optimized for the m5 instance type, and 50 hours of Amazon SageMaker training time with the m5.xlarge instance type are included as part of the AWS Free Tier. We recommend starting there and adjusting the instance type up or down based on how long your initial job takes and how quickly you need the results.
- Select the IAM creation acknowledgement checkbox and choose Create stack.

- Continue with the AWS CloudFormation wizard until you arrive at the Stacks page.

It takes a moment for AWS CloudFormation to create all the pipeline’s resources. When you see the CREATE_COMPLETE status (you may need to refresh the page), the pipeline is ready for use.
- To see all the components shown in the architecture, choose the Resources tab.
- To navigate to the S3 bucket, choose the corresponding link.

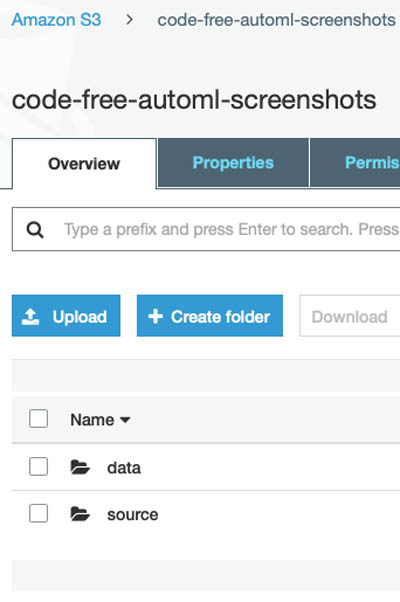
Before you can use the pipeline, you have to upload the pre-made AutoGluon package to your new S3 bucket.
- Create a folder called
sourcein that bucket.

- Upload the sourcedir.tar.gz package there; keep the default object settings.

Your pipeline is now ready for use!
Preparing the training data
To prepare your training data, go back to the root of the bucket (where you see the source folder) and make a new directory called data; this is where you upload your data.
Gather the data you want your models to learn from (the training data). The pipeline is designed to make predictions for tabular data, the most common form of data in real-world applications. Think of it like a spreadsheet; each column represents the measurement of some variable (feature value), and each row represents an individual data point (observation).
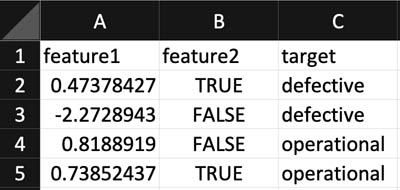
For each observation, your training dataset must include columns for explanatory features and the target column containing the feature value you want your models to predict.
Store the training data in a CSV file called <Name>_train.csv, where <Name> can be replaced with anything.
Make sure that the header name of the desired target column (the value of the very first row of the column) is set to target so AutoGluon recognizes it. See the following screenshot of an example dataset.
Preparing the test data
You also need to provide the testing data you want to make predictions for. If this dataset already contains values for the target column, you can compare these actual values to your model’s predictions to evaluate the quality of the model.
Store the testing dataset in another CSV file called <Name>_test.csv, replacing <Name> with the same string you chose for the corresponding training data.
Make sure that the column names match those of <Name>_train.csv, including naming the target column target (if present).
Upload the <Name>_train.csv and <Name>_test.csv files to the data folder you made earlier in your S3 bucket.
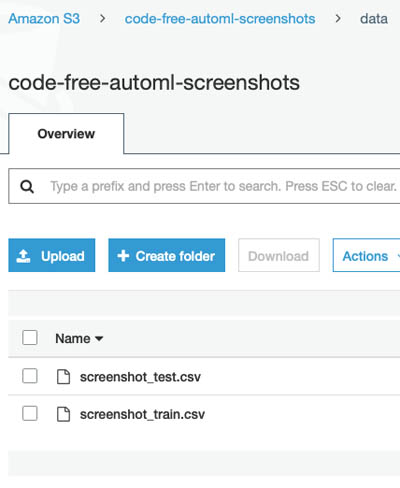
The code-free ML pipeline kicks off automatically when the upload is finished.
Training the model
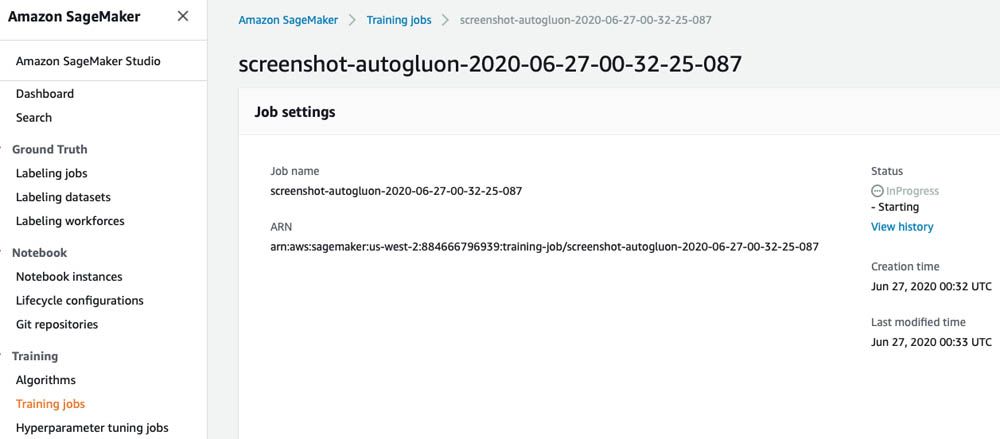
When the training and testing dataset files are uploaded to Amazon S3, AWS logs the occurrence of an event and automatically triggers the Lambda function. This function launches the Amazon SageMaker training job that uses AutoGluon to train an ensemble of ML models. You can view the job’s status on the Amazon SageMaker console, in the Training jobs section (see the following screenshot).
Performing inference
When the training job is complete, the best-performing model or weighted combination of models (as determined by AutoGluon) is used to compute predictions for the target feature value of each observation in the testing dataset. These predictions are automatically stored in a new directory within a results directory in your S3 bucket, with the filename <Name>_test_predictions.csv.
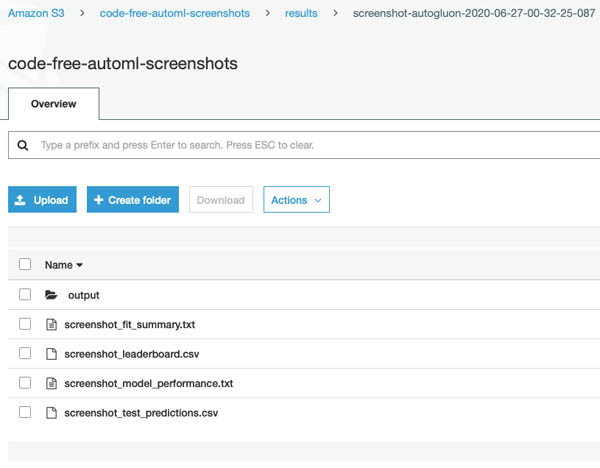
AutoGluon produces other useful output files, such as <Name>_leaderboard.csv (a ranking of each individual model trained by AutoGluon and its predictive performance) and <Name>_model_performance.txt (an extended list of metrics corresponding to the best-performing model). All these files are available for download to your local machine from the Amazon S3 console (see the following screenshot).
Extensions
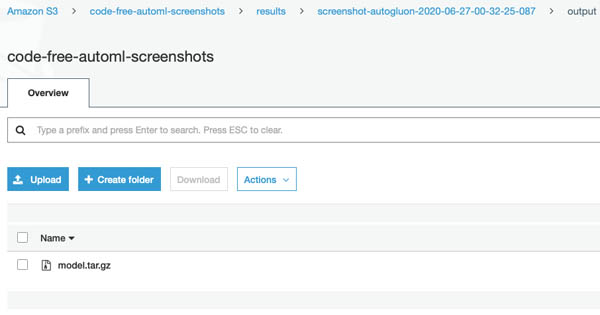
The trained model artifact from AutoGluon’s best-performing model is also saved in the output folder (see the following screenshot).
You can extend this solution by deploying that trained model as an Amazon SageMaker inference endpoint to make predictions on new data in real time or by running an Amazon SageMaker batch transform job to make predictions on additional testing data files. For more information, see Work with Existing Model Data and Training Jobs.
You can also reuse this automated pipeline with custom model code by replacing the AutoGluon sourcedir.tar.gz package we prepared for you in the source folder. If you unzip that package and look at the Python script inside, you can see that it simply runs AutoGluon on your data. You can adjust some of the parameters defined there to better match your use case. That script and all the other resources used to set up this pipeline are freely available in this GitHub repository.
Cleaning up
The pipeline doesn’t cost you anything more to leave up in your account because it only uses fully managed compute resources on demand. However, if you want to clean it up, simply delete all the files in your S3 bucket and delete the launched CloudFormation stack. Make sure to delete the files first; AWS CloudFormation doesn’t automatically delete an S3 bucket with files inside.
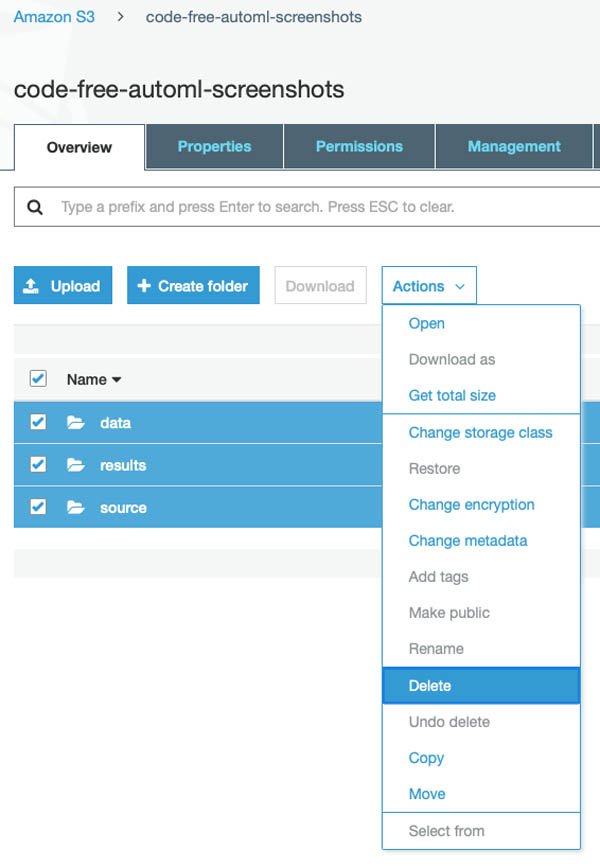
To delete the files from your S3 bucket, on the Amazon S3 console, select the files and choose Delete from the Actions drop-down menu.
To delete the CloudFormation stack, on the AWS CloudFormation console, choose the stack and choose Delete.
In the confirmation window, choose Delete stack.
Conclusion
In this post, we demonstrated how to train ML models and make predictions without writing a single line of code—thanks to AutoGluon, Amazon SageMaker, and AWS Lambda. You can use this code-free pipeline to leverage the power of ML without any prior programming or data science expertise.
If you’re interested in getting more guidance on how you can best use ML in your organization’s products and processes, you can work with the Amazon ML Solutions Lab. The Amazon ML Solutions Lab pairs your team with Amazon ML experts to prepare data, build and train models, and put models into production. It combines hands-on educational workshops with brainstorming sessions and advisory professional services to help you work backward from business challenges, and go step-by-step through the process of developing ML-based solutions. At the end of the program, you can take what you have learned through the process and use it elsewhere in your organization to apply ML to business opportunities.
About the Authors
 Abhi Sharma is a deep learning architect on the Amazon ML Solutions Lab team, where he helps AWS customers in a variety of industries leverage machine learning to solve business problems. He is an avid reader, frequent traveler, and driving enthusiast.
Abhi Sharma is a deep learning architect on the Amazon ML Solutions Lab team, where he helps AWS customers in a variety of industries leverage machine learning to solve business problems. He is an avid reader, frequent traveler, and driving enthusiast.
 Ryan Brand is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.
Ryan Brand is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.
 Tatsuya Arai Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon Machine Learning Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.
Tatsuya Arai Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon Machine Learning Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.