Artificial Intelligence
How the UNDP Independent Evaluation Office is using AWS AI/ML services to enhance the use of evaluation to support progress toward the Sustainable Development Goals
The United Nations (UN) was founded in 1945 by 51 original Member States committed to maintaining international peace and security, developing friendly relations among nations, and promoting social progress, better living standards, and human rights. The UN is currently made up of 193 Member States and has evolved over the years to keep pace with a rapidly changing world. The United Nations Development Programme (UNDP) is the UN’s development agency and operates in over 170 countries and territories. It plays a critical role in helping countries achieve the Sustainable Development Goals (SDGs), which are a global call to action to end poverty, protect the planet, and ensure all people enjoy peace and prosperity.
As a learning organization, the UNDP highly values the evaluation function. Each UNDP program unit commissions evaluations to access the performance of their projects and programs. The Independent Evaluation Office (IEO) is a functionally independent office within the UNDP that supports the oversight and accountability functions of the Executive Board and management of the UNDP, UNCDF, and UNV. The core functions of the IEO are to conduct independent programmatic and thematic evaluations that are of strategic importance to the organization—like its support for the COVID-19 pandemic recovery.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC). AIDA is a web-based platform that allows program managers and evaluators to expand their evidence base by searching existing data in a smarter, more efficient, and innovative way to produce insights and lessons learned. By searching at the granular level of paragraphs, AIDA finds pieces of evidence that would not be found using conventional searches. The creation of AIDA aligns with the UNDP Strategic Plan 2022–2025 to use digitization and innovation for greater development impact.
The challenge
The IEO is the custodian of the UNDP Evaluation Resource Center (ERC). The ERC is a repository of over 6,000 evaluation reports that cover every aspect of the organization’s work, everywhere it has worked, since 1997. The findings and recommendations of the evaluation reports inform UNDP management, donor, and program staff to better design future interventions, take course-correction measures in their current programs, and make funding and policy decisions at every level.
Before AIDA, the process to extract evaluative evidence and generate lessons and insights was manual, resource-intensive, and time-consuming. Moreover, traditional search methods didn’t work well with unstructured data, therefore the evidence base was limited. To address this challenge, the IEO decided to use AI and ML to better mine the evaluation database for lessons and knowledge.
The AIDA team was mindful of the challenging task of extracting evidence from unstructured data such as evaluation reports. Usually, evaluation reports are 80–100 pages, are in multiple languages, and contain findings, conclusions, and recommendations. Even though evaluations are guided by the UNDP Evaluation Guideline, there is no standard written format for these evaluations, and the aforementioned sections may occur at different locations in the document, or not all of them may exist. Therefore, accurately exacting evaluative evidence at the paragraph level and applying appropriate labels was a significant ML challenge.
Solution overview
The AIDA technical solution was developed by AWS Professional Services and the UNICC. The core technology platform was designed and developed by the AWS ProServe team. The UNICC was responsible for developing the AIDA web portal and human-in-the-loop interface. The AIDA platform was envisioned to provide a simple and highly accurate mechanism to search UNDP evaluation reports across various themes and export them for further analysis. AIDA’s architecture needed to address several requirements:
- Automate the extraction and labeling of evaluation data
- Process thousands of reports
- Allow the IEO to add new labels without calling on the expertise of data scientists and ML experts
To deliver the requirements, the components were designed with these tenets in mind:
- Technically and environmentally sustainable
- Cost conscious
- Extensible to allow for future expansion
The resulting solution can be broken down to three components, as shown in the following architecture diagram:
- Data ingestion and extraction
- Data classification
- Intelligent search
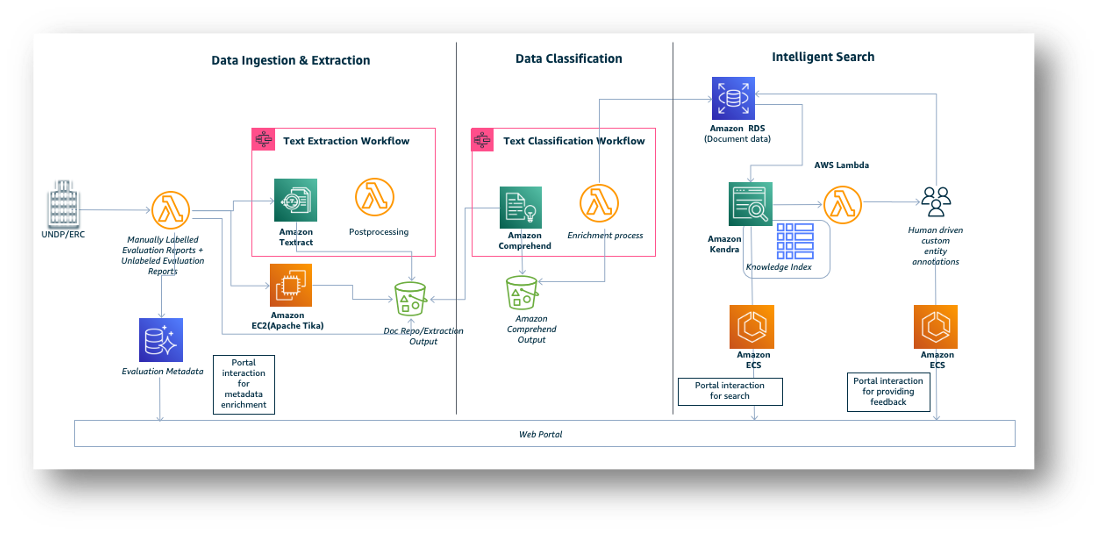
The following sections describe these components in detail.
Data ingestion and extraction
Evaluation reports are prepared and submitted by UNDP program units across the globe—there is no standard report layout template or format. The data ingestion and extraction component ingests and extracts content from these unstructured documents.
Amazon Textract is used to extract data from PDF documents. This solution uses the asynchronous StartDocumentTextDetection API to build the document processing workflow that handles Amazon Textract asynchronous invocation, raw response extraction, and persistence in Amazon Simple Storage Service (Amazon S3). This solution adds an Amazon Textract postprocessing component to handle paragraph-based text extraction. The postprocessing component uses bounding box metadata from Amazon Textract for intelligent data extraction. The postprocessing component is capable of extracting data from complex, multi-format, multi-page PDF files with varying headers, footers, footnotes, and multi-column data. The Apache Tika open-source Python library is used for data extraction from word documents.
The following diagram illustrates this workflow, orchestrated with AWS Step Functions.
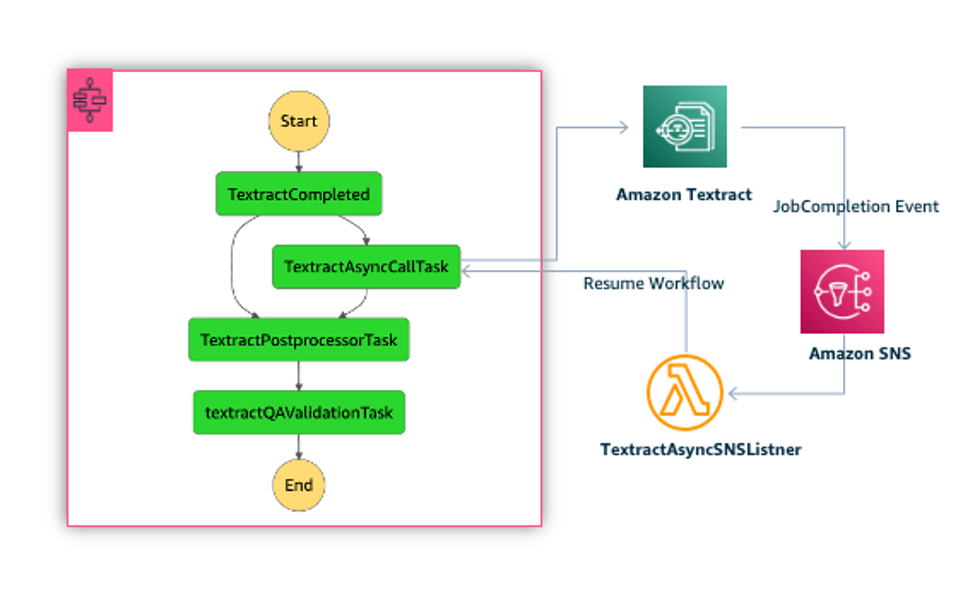
This workflow has the following steps:
TextractCompletedis the first step to ensure documents are not processed multiple times with Amazon Textract. This step is to avoid unnecessary processing time and cost by preventing duplicate processing.TextractAsyncCallTasksubmits the documents to be processed by Amazon Textract using the asynchronous StartDocumentTextDetection API. This API processes the documents and stores the JSON output files in Amazon S3 for postprocessing.TextractAsyncSNSListeneris an AWS Lambda function that handles the Amazon Textract job completion event, and returns the metadata back to the workflow for further processing.TextractPostProcessorTaskis an AWS Lambda function that uses the metadata and processes the JSON output files produced by Amazon Textract to extract meaningful paragraphs.TextractQAValidationTaskis an AWS Lambda function that performs some simple text validations on the extracted paragraphs and collects metrics like number of complete or incomplete paragraphs. These metrics are used to measure the quality of text extractions.
Please refer to TextractAsync, an IDP CDK construct that abstracts the invocation of the Amazon Textract Async API, handling Amazon Simple Notification Service (Amazon SNS) messages and workflow processing to accelerate your development.
Data classification
The data classification component identifies the critical parts of the evaluation reports, and further classifies them into a taxonomy of categories organized around the various themes of the Sustainable Development Goals. We have built one multi-class and two multi-label classification models with Amazon Comprehend.

Extracted paragraphs are processed using Step Functions, which integrates with Amazon Comprehend to perform classification in batch mode. Paragraphs are classified into findings, recommendations, and conclusions (FRCs) using a custom multi-class model, which helps identify the critical sections of the evaluation reports. For the identified critical sections, we identify the categories (thematic and non-thematic) using a custom multi-label classification model. Thematic and non-thematic classification is used to identify and align the evaluation reports with Sustainable Development Goals like no poverty (SDG-1), gender equality (SDG-5), clean water and sanitation (SDG-6), and affordable and clean energy (SDG-7).
The following figure depicts the Step Functions workflow to process text classification.

To reduce cost on the classification process, we have created the workflow to submit Amazon Comprehend jobs in batch mode. The workflow waits for all the Amazon Comprehend jobs to complete and performs data refinement by aggregating the text extraction and Amazon Comprehend results to filter the paragraphs that aren’t identified as FRC, and aggregates the thematic and non-thematic classification categories by paragraphs.
Extracted paragraphs with their classification categories are stored in Amazon RDS for PostgreSQL. This is a staging database to preserve all the extraction and classification results. We also use this database to further enrich the results to aggregate the themes of the paragraphs, and filter paragraphs that are not FRC. Enriched content is fed to Amazon Kendra.
For the first release, we had over 2 million paragraphs extracted and classified. With the help of FRC custom classification, we were able to accurately narrow down the paragraphs to over 700,000 from 2 million. The Amazon Comprehend custom classification model helped accurately present the relevant content and substantially reduced the cost on Amazon Kendra indexes.
Amazon DynamoDB is used for storing document metadata and keeping track of the document processing status across all key components. Metadata tracking is particularly useful to handle errors and retries.
Intelligent search
The intelligent search capability allows the users of the AIDA platform to intuitively search for evaluative evidence on UNDP program interventions contained within all the evaluation reports. The following diagram illustrates this architecture.

Amazon Kendra is used for intelligent searches. Enriched content from Amazon RDS for PostgreSQL is ingested into Amazon Kendra for indexing. The web portal layer uses the intelligent search capability of Amazon Kendra to intuitively search the indexed content. Labelers use the human-in-the-loop user interface to update the text classification generated by Amazon Comprehend for any extracted paragraphs. Changes to the classification are immediately reflected in the web portal, and human-updated feedback is extracted and used for Amazon Comprehend model training to continuously improve the custom classification model.
AIDA incorporates a human-in-the-loop functionality, which boosts AIDA’s capacity to correct classifications (FRC, thematic, non-thematic) and data extractions errors. Labels, updated by the humans performing the human-in-the-loop function, are augmented to the training dataset and used to retrain the Amazon Comprehend models to continuously improve classification accuracy.
Conclusion
In this post, we discussed how evaluators, through the IEO’s AIDA platform, are using Amazon AI and ML services like Amazon Textract, Amazon Comprehend, and Amazon Kendra to build a custom document processing system that identifies, extracts, and classifies data from unstructured documents. Using Amazon Textract for PDF text extraction improved paragraph-level evidence extraction from under 60% to over 80% accuracy. Additionally, multi-label classification improved from under 30% to 90% accuracy by retraining models in Amazon Comprehend with improved training datasets.
This platform enabled evaluators to intuitively search relevant content quickly and accurately. Transforming unstructured data to semi-structured data empowers the UNDP and other UN entities to make informed decisions based on a corpus of hundreds or thousands of data points about what works, what doesn’t work, and how to improve the impact of UNDP operations for the people it serves.
For more information about the intelligent document processing reference architecture, refer to Intelligent Document Processing. Please share your thoughts with us in the comments section.
About the Authors
 Oscar A. Garcia is the Director of the Independent Evaluation Office (IEO) of the United Nations Development Program (UNDP). As Director, he provides strategic direction, thought leadership, and credible evaluations to advance UNDP work in helping countries progress towards national SDG achievement. Oscar also currently serves as the Chairperson of the United Nations Evaluation Group (UNEG). He has more than 25 years of experience in areas of strategic planning, evaluation, and results-based management for sustainable development. Prior to joining the IEO as Director in 2020, he served as Director of IFAD’s Independent Office of Evaluation (IOE), and Head of Advisory Services for Green Economy, UNEP. Oscar has authored books and articles on development evaluation, including one on information and communication technology for evaluation. He is an economist with a master’s degree in Organizational Change Management, New School University (NY), and an MBA from Bolivian Catholic University, in association with the Harvard Institute for International Development.
Oscar A. Garcia is the Director of the Independent Evaluation Office (IEO) of the United Nations Development Program (UNDP). As Director, he provides strategic direction, thought leadership, and credible evaluations to advance UNDP work in helping countries progress towards national SDG achievement. Oscar also currently serves as the Chairperson of the United Nations Evaluation Group (UNEG). He has more than 25 years of experience in areas of strategic planning, evaluation, and results-based management for sustainable development. Prior to joining the IEO as Director in 2020, he served as Director of IFAD’s Independent Office of Evaluation (IOE), and Head of Advisory Services for Green Economy, UNEP. Oscar has authored books and articles on development evaluation, including one on information and communication technology for evaluation. He is an economist with a master’s degree in Organizational Change Management, New School University (NY), and an MBA from Bolivian Catholic University, in association with the Harvard Institute for International Development.
 Sathya Balakrishnan is a Sr. Customer Delivery Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr. Customer Delivery Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Thuan Tran is a Senior Solutions Architect in the World Wide Public Sector supporting the United Nations. He is passionate about using AWS technology to help customers conceptualize the art of the possible. In this spare time, he enjoys surfing, mountain biking, axe throwing, and spending time with family and friends.
Thuan Tran is a Senior Solutions Architect in the World Wide Public Sector supporting the United Nations. He is passionate about using AWS technology to help customers conceptualize the art of the possible. In this spare time, he enjoys surfing, mountain biking, axe throwing, and spending time with family and friends.
 Prince Mallari is an NLP Data Scientist in the Professional Services team at AWS, specializing in applications of NLP for public sector customers. He is passionate about using ML as a tool to allow customers to be more productive. In his spare time, he enjoys playing video games and developing one with his friends.
Prince Mallari is an NLP Data Scientist in the Professional Services team at AWS, specializing in applications of NLP for public sector customers. He is passionate about using ML as a tool to allow customers to be more productive. In his spare time, he enjoys playing video games and developing one with his friends.