Artificial Intelligence
Interpreting 3D seismic data automatically using Amazon SageMaker
Interpreting 3D seismic data correctly helps identify geological features that may hold or trap oil and gas deposits. Amazon SageMaker and Apache MXNet on AWS can automate horizon picking using deep learning techniques.
In this post, I use these services to build and train a custom deep-learning model for the interpretation of geological features on 3D seismic data. The purpose of this post is to show oil and gas data scientists how they can quickly and easily create customized semantic-segmentation models.
Amazon SageMaker is a fully managed service that enables data scientists to build, train, tune, and deploy machine learning models at any scale. This service provides a powerful and scalable compute environment that is also easy to use.
| About this blog post | |
| Time to read | 15 minutes |
| Time to complete | ~ 1 hour |
| Cost to complete | Under $60 |
| Learning level | Intermediate (200) |
| AWS services | Amazon SageMaker, EC2, Amazon S3 |
Overview
Understanding subsurface geology is critical for determining where and how deep to drill, optimizing oil and gas production, and so on. A technology called 3D seismic imaging turns seismic data into images, which then requires identifying geologic layers (such as salt bodies) and structures (such as faults and folds). This manual identification process, called “picking horizons,” can take weeks.
Manual horizon picking can be automated using deep learning techniques such as semantic segmentation, which uses deep convolutional neural networks for feature extraction and dense layers for segmentation and classification. However, to train a deep learning model for seismic applications, GPUs are required. Lack of compute resources prevents many oil and gas data scientists from applying deep learning methods for seismic applications.
In this post, I show how to find salt bodies using the U-Net structure for semantic segmentation and a public domain image dataset from a Kaggle competition. With these resources, you build an algorithm to identify subsurface salt deposits. You can easily clone and extend this notebook to other semantic segmentation applications in seismic data analysis.
Workflow
Use the following steps to do semantic segmentation in Amazon SageMaker:
- Upload the Kaggle data and create a data file.
- Prepare the images.
- Train the model.
- Deploy the model.
Prerequisites
To do semantic segmentation on Amazon SageMaker, you must first follow these steps:
- Create an AWS account (tutorial).
- Sign into your AWS account.
- Create an Amazon SageMaker notebook instance. The notebook instance is pending while it is being set up. It takes a few minutes to be available.
Upload the code and Kaggle data to Amazon SageMaker
Download the following notebook and code to your computer:
In the Amazon SageMaker console, choose Notebook, Notebook instances. In the Actions column, choose Open Jupyter. Upload the three files that you just downloaded, from your computer to the Amazon SageMaker instance, by clicking Upload.
On your SageMaker instance, choose New, Folder, and create a folder named “data”. From the GS Kaggle data that you just downloaded, copy the train folder into the data folder that you just created.
The rest of the notebook can stay as-is unless you must change the hyperparameters, such as number of epochs, number of instances, and so on.
Prepare the images
Now that you’ve created the Amazon SageMaker instance and copied the required code and data from Kaggle, do basic quality control on the images. Here is an example of the TGS salt image and its corresponding mask file.
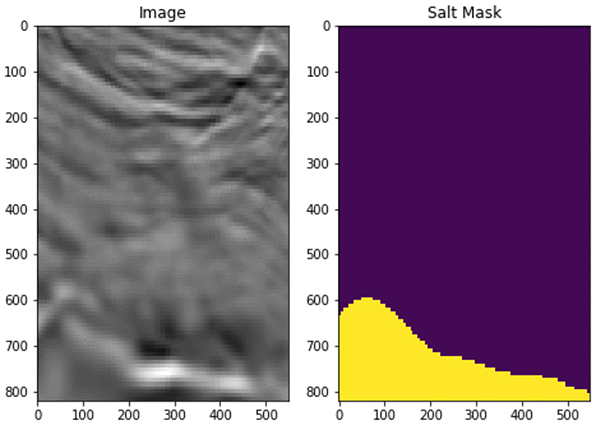
Then, stack the files into a single variable and do random cropping for data augmentation.
Train the model
When the data is prepared, upload it to Amazon S3 as described in the notebook for training. You can specify which instance type to use, as well as the number of instances.
For this example, I recommend running the image classification deep neural network on a GPU instance. Optionally, you can use multiple GPU instances for distributed training. All you have to do is to enter the number of the GPU instances and Amazon SageMaker does the rest.
Next, define the hyperparameters, as shown in the following code:
The following line of code uses the hyperparameters to train your model. For more information about Amazon SageMaker Python SDK for MXNet, see the sagemaker-python-sdk.
Deploy the model
After training, deploy the model on the cloud for making real-time predictions. Similar to training, you can select the type and count of instances on which to deploy your model, as shown in the following code:
Here are some examples of predicting the salt body using the model that you just built:
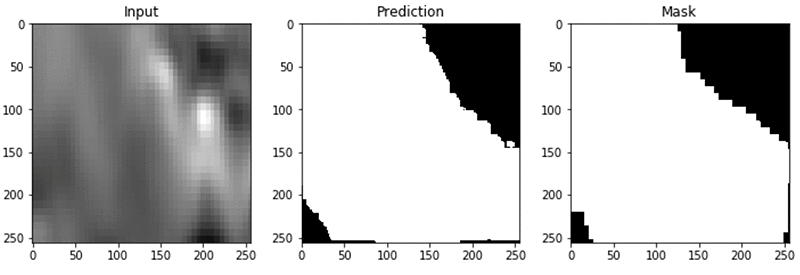
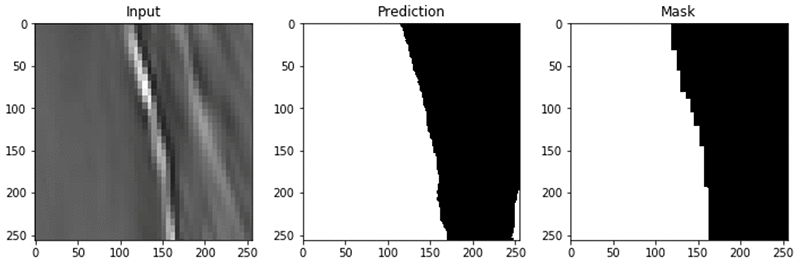
Conclusion
In this post, you learned how to use Amazon SageMaker to do semantic segmentation for seismic applications, with minimal coding effort. This example can easily be customized for any other application by simply replacing the folder names for your images. For more detailed examples of semantic segmentation using Amazon SageMaker for other applications, see the following:
- Segmenting brain tissue using Apache MXNet with Amazon SageMaker and AWS Greengrass ML Inference – Part 1
- Semantic Segmentation algorithm is now available in Amazon SageMaker
If you have questions or suggestions, please leave a comment below.
Acknowledgment
Thanks to Brad Kenstler of AWS, who provided the original code for Amazon SageMaker semantic segmentation.
About the Author
 Mehdi E. Far is a Lead Data Scientist at Solutions Prototyping team. He is based in Houston Texas, focusing on Global Accounts. He has a background in Geophysics and Petroleum Engineering.
Mehdi E. Far is a Lead Data Scientist at Solutions Prototyping team. He is based in Houston Texas, focusing on Global Accounts. He has a background in Geophysics and Petroleum Engineering.