Artificial Intelligence
Segmenting brain tissue using Apache MXNet with Amazon SageMaker and AWS Greengrass ML Inference – Part 1
Annotation and segmentation of medical images is a laborious endeavor that can be automated in part via deep learning (DL) techniques. These approaches have achieved state-of-the-art results in generic segmentation tasks, the goal of which is to classify images at the pixel level.
In Part 1 of this blog post, we demonstrate how to train and deploy neural networks to automatically segment brain tissue from an MRI scan in a simple, streamlined way using Amazon SageMaker. We use Apache MXNet to train a convolutional neural network (CNN) on Amazon SageMaker using the Bring Your Own Script paradigm. We train two networks: U-Net and the efficient, low-latency ENet. In Part 2, we will seehow to use AWS Greengrass ML Inference to deploy ENet to a portable edge device for offline inference in low- or no-connectivity environments.
Although the post applies this approach to brain MRIs, as a technique for generic segmentation it’s applicable to similar use cases such as analyzing x-rays.
This blog post provides a high-level overview. For a complete tutorial notebook, see Amazon SageMaker Brain Segmentation on GitHub.
By the end of this blog post, we will predict brain tissue segmentations from MRIs as shown here.
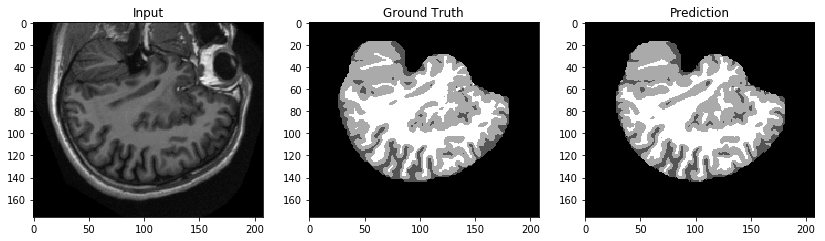
While this use case deals with medical imaging as raw images and not Protected Health Information (PHI), please note the following:
AWS Greengrass is not an AWS HIPAA Eligible Service at the time of this writing. Consistent with the AWS Business Associate Addendum (BAA), AWS Greengrass should not be used to create, receive, maintain, or transmit Protected Health Information (PHI) under the U.S. Health Insurance Portability and Accountability Act (HIPAA). It is each customer’s responsibility to determine whether they are subject to HIPAA, and if so, how best to comply with HIPAA and its implementing regulations. Accounts that create, receive, maintain, or transmit PHI using a HIPAA Eligible Service should encrypt PHI as required under the BAA. For a current list of HIPAA Eligible Services, and for more information generally, see the AWS HIPAA Compliance page.
Overview
Use case
Medical imaging techniques enable medical professionals to see inside the human body, but the professional often needs precise segmentation of the tissues in the image for analytical procedures and inferences. This is particularly relevant in use cases where volumetric and surface analysis are key to deriving insights from the raw images, such as assessing the cardiovascular health of a patient. Typically, medical professionals do this segmentation manually, which is time-consuming. Recently, convolutional neural networks have been shown to be highly performant at generic segmentation tasks. In this post, we use Amazon SageMaker to train and deploy two such networks to automatically segment brain tissue from MRI images. Amazon SageMaker is a fully managed platform that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at any scale.
Of additional interest for such models is edge deployment. Running inference offline at the edge has potential for significant impact in medical image annotation. Given the dearth of medical professionals in parts of the world with limited or no internet connectivity, a portable, low-power solution that can automate annotation locally has many advantages. This post also shows how to deploy models trained in Amazon SageMaker to the edge using AWS Greengrass. This service enables you to run local compute, messaging, data caching, sync, and ML Inference capabilities for connected devices in a secure way.
Setting up
To reproduce the steps outlined here, you need to run the Jupyter notebook with associated code in the repository that accompanies this blog post. Amazon SageMaker provides fully managed instances that are preloaded with ML and DL frameworks and run Jupyter notebooks. We suggest launching one and cloning the repository into your notebook instance to follow along.
Note – If you do use an Amazon SageMaker notebook instance, you likely need to store the data used in this post on a separate device. Possible choices include using shared memory or mounting an Amazon Elastic File System.
CNN architectures
In this post, we apply two models to the task of brain tissue segmentation:
- U-Net – Introduced in the paper U-Net: Convolutional Networks for Biomedical Image Segmentation, this network was originally used for medical-imaging use cases but has since proven to be reliable in generic segmentation domains. Due to its architectural and conceptual simplicity, it’s often used as a baseline.
- ENet – Introduced in the paper ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation, ENet is designed to be low-latency and to operate in environments with low compute capacity (e.g., edge devices). Compared to existing architectures, ENet optimizes for processing time over accuracy.
Data
In this post, we use a small subset of cross-sectional brain MRI data from the Open Access Series of Imaging Studies (OASIS). This project offers a wealth of neuroimaging datasets.
Exploratory data analysis and preprocessing
Before we can start training our networks, we need to visualize the data to better understand it and preprocess it for training a segmentation network. Then we put the preprocessed data on Amazon S3 for Amazon SageMaker to use during model training.
Visualization
The data comes as a vector image in the .img format, each file representing a complete three-dimensional MRI scan of a particular brain. Although organ tissue segmentation is inherently a three-dimensional task, we approximate it by segmenting 2-D cross-sectional MRI slices. This is less complex and compute-intensive than volumetric segmentation and performs reasonably well.
First, load an example into memory as a numpy array and visualize a slice.
The array that we loaded into memory is three-dimensional as expected. We have selected a particular slice along the third axis, as shown in the following image.
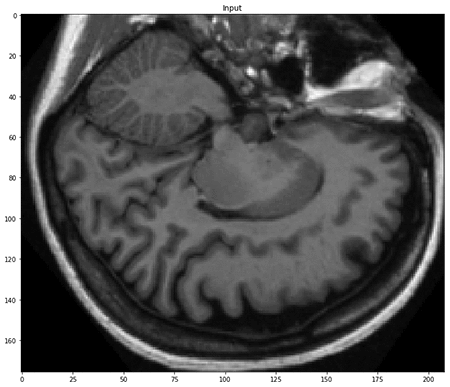
As in any semantic segmentation task, the label for each input is a mask of integers, each uniquely corresponding to a particular class. In this case, those classes are types of brain tissue and background, as seen here.
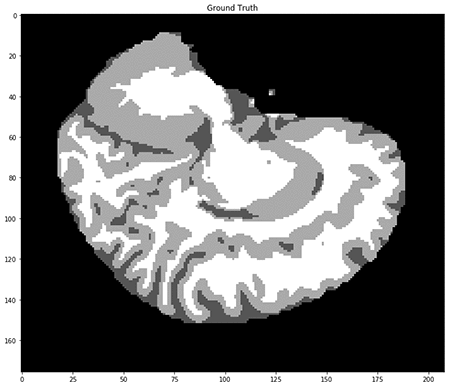
Preprocessing
Now we need to preprocess the data to train our network on it. We’re going to split the data into a training and validation set (80/20) by patient. This is important to remove any possibility of data leakage; neighboring brain MRI slices will correlate, and splitting by patient ensures clean validation.
To preprocess the MRI images, we need to convert them from their native format to arrays that we can save as PNG images. The raw MRI arrays have values that represent radiological intensities. These have a far wider range than pixel intensities and are loaded into memory as uint16. Upon saving the slices as PNGs, the data is scaled to fall within the [0,255] range of uint8.
Note – This scaling can result in differences between tissue pixel distributions from image to image, but this doesn’t have an impact on model training.
Notice that we’re grabbing every other slice. This is because the raw MRI is twice as granular as the corresponding mask.
For the masks, we need to save the raw masks as images with exactly one pixel per tissue class. The pixel values of the raw images aren’t exact, and so each raw mask’s pixel values are mapped to a specific integer.
Now we can create subsets for test samples and distributed training, compressing each subset.
Model training
Setting up
Begin by importing the Amazon SageMaker Python SDK. We’re going to define the following:
- A session object that provides convenience methods within the context of Amazon SageMaker and our own account.
- An Amazon SageMaker role ARN used to delegate permissions to the training and hosting service. We need this so that these services can access the Amazon S3 buckets where our data and model are stored.
We also imported the Amazon SageMaker estimator object MXNet. This object references default containers that AWS provides, and users provide only entry point scripts and supporting code. Although this tutorial uses the MXNet framework, you can just as easily bring your own script with Tensorflow, Chainer, and now PyTorch.
Uploading data to Amazon S3
Next, upload the preprocessed data to Amazon S3 using the upload_data method to put the objects in a default Amazon SageMaker bucket. Pass the parent directory containing the compressed files to the method, which syncs the child tree to the bucket.
Entry Point
As previously mentioned, the MXNet estimator uses a default MXNet container, and the user simply provides the code that defines the training. (For an example, see Training and Hosting SageMaker Models Using the Apache MXNet Module API on GitHub.)
The script that we pass as an entry point to the estimator is brain_segmentation.py.
This script defines the training loop, which constitutes the life cycle of the training job. Some points to notice:
- Hyperparameters – We pass this hyperparameter mapping to the estimator as part of the training configuration.
- Network – This hyperparameter defines the network to train, either unet or enet.
- Local imports – The model, iterator, and loss/metric definitions are in local modules. We pass this script and accompanying modules to the estimator
We encourage you to look at the modules in the tutorial repository to gain deeper insight into these models and iterators.
Note – ML hyperparameter tuning can be complex and time-consuming and require expertise. This is even more true for neural networks. With automatic model tuning in Amazon SageMaker, developers and data scientists can launch hyperparameter tuning jobs that optimize on a given metric or metrics using Bayesian optimization. You can use automatic model tuning on any Amazon SageMaker training job including this one. To see how, we recommend starting with Hyperparameter Tuning with Amazon SageMaker and MXNet on GitHub.
Using local mode for local testing
When bringing your own script or model to Amazon SageMaker, you should test your code to make sure that it’s bug-free. Best practice is to test your custom algorithm container locally. Otherwise, you have to wait for Amazon SageMaker to spin up your training instance(s) before receiving an error. This is supported with local mode.
To run the container locally, download, install, and configure Docker to run locally with Amazon SageMaker, which you can be do with this helper script.
Next, define the Amazon S3 input types (we test on sample sets).
Now we can define our estimator with training configurations, including the entry point script and directory for the accompanying code. Notice we’re setting train_instance_type to local to launch the job locally.
Now call fit on the Amazon S3 inputs, mapping train and test labels to each. Because we’re in local mode, the container is downloaded and the image run locally.
Next, test the serving image locally as well by calling deploy.
The deploy method returns a predictor, which we can use to submit requests to the endpoint.
At one epoch on a sample data set, the results are predictably terrible, as shown in the following image. Training for more epochs will result in better performance.
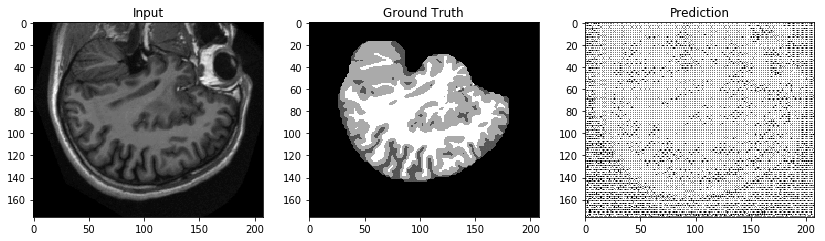
Having tested our script, we can launch real training jobs and endpoints with confidence.
U-Net
First, we train U-Net as a baseline for comparison with the faster, lightweight ENet. By default, the training job runs for 100 epochs.
This time, train on the entire training set and validate on the entire validation set.
ENet
To train ENet, just change the network hyperparameter to enet.
Distributed training
The data that we have trained on is a very small subset of what’s available at OASIS. With training at scale, distributed training is often a more cost-effective approach to training your network than vertical scaling, in terms of both time and money. At our scale, this approach might or might not be faster than a single machine, but we provide it as demonstration.
Launching a distributed training job on Amazon SageMaker with your own script takes only a few steps, as follows:
- The script that we provide must support distributed training. In MXNet, do this by defining a key-value store. This portion of the entry point script checks to see if the job has multiple devices and, if so, defines the key-value store for synchronous distributed training.
- Set
train_instance_countfrom one to many. - Shard training data across nodes.
For the last step, we define a sharded Amazon S3 input by setting distribution to ShardedByS3Key. This option attempts to evenly split the number of objects under the provided prefix across nodes (this implicitly means you need as many objects under the prefix as nodes). Had you kept this argument as FullyReplicated, each node would have copies of the entire data set.
Now you can launch a distributed training job.
Deploying the inference endpoints
Now that we’ve trained both models, we can use Amazon SageMaker to deploy them to web-hosted HTTP endpoints to serve inferences and predictions at low latency. By default, these endpoints respond to POST requests of in-memory image arrays.
Deploying the U-Net endpoint
First we deploy U-Net to an endpoint.
Let’s get a test response and compare the inference with the input and ground truth.
Qualitatively speaking, these results in the following image look promising.
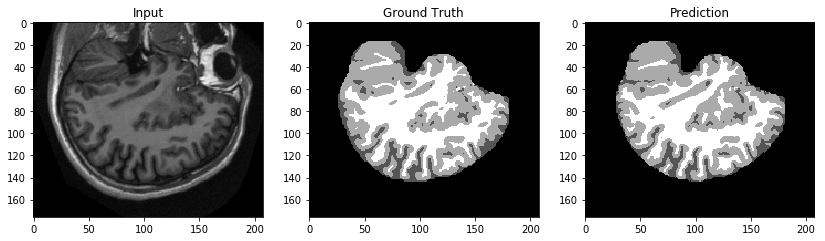
Deploying the ENet endpoint
Now let’s deploy our ENet model. Instead of using the deploy method in estimator, as an exercise we create a model object, MXNetModel, instead. We pass the location of the ENet model artifact from the training job. This is how you would bring your own model to Amazon SageMaker to deploy to an endpoint.
Let’s get a test response and compare the inference with the input and ground truth.
Again, the results in the following image look qualitatively promising.
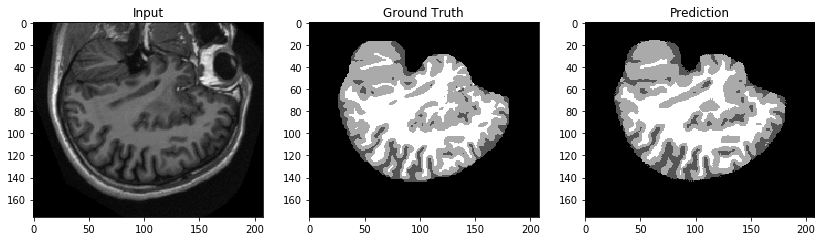
Invoking the endpoint using an Amazon S3 URI
MXNet endpoints in Amazon SageMaker are by default set up to run inference on data sent via POST request. The assumption is that the data sent is in the format of the data that the model is trained on. For computer vision models, this can be problematic due to the bandwidth limits on Amazon SageMaker requests.
One workaround is to instead submit an Amazon S3 Uniform Resource Identifier (URI), have the endpoint download the image locally, transform, and put the resulting mask back to Amazon S3. In this approach, there is no limit to the size of the content transformed.
Let’s take a look at what entry point for this custom serving image would look like.
Because we already have a trained model, we directly define the model object using MXNetModel with the Amazon S3 location of our model artifact from the earlier training job.
Now we upload our test image to Amazon S3.
The body of our request will be in JSON format, so define a dict containing the relevant fields and invoke the endpoint.
Now download the result and visualize.
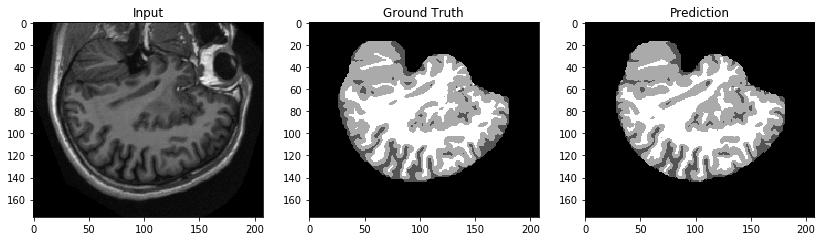
Evaluating and comparing the models
Both models look qualitatively performant, but we need to quantify this and compare the latency between the two models. Recall that ENet is designed to trade off accuracy for efficiency and low latency.
Using confusion matrices
An effective way to visualize performance for multi-class classification is with a confusion matrix, which compares ground truth labels with predicted labels. Because semantic segmentation is ostensibly per-pixel multiclass classification, confusion matrices are useful here, too.
We use the following code from the scikit-learn documentation to plot confusion matrices.
We can use the U-Net endpoint to get predictions to compare to ground truths from the validation set.
Now we can compare the predictions to the ground truth labels.
This gives us the normalized confusion matrix, as shown in the following image.
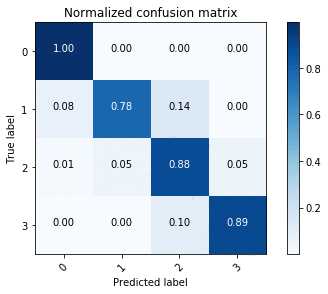
Doing the same with the ENet endpoint provides the confusion matrix in the following image.
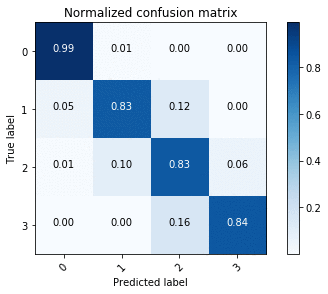
Using the confusion matrices, we see that U-Net outperforms ENet in terms of accuracy overall, but this is to be expected given the accuracy-latency tradeoff.
Quantifying inference latency
To quantify inference times for the two models, we timed forward passes for U-Net and ENet in the following environments:
- Amazon EC2 c5.2xlarge instances for CPU with MKL-DNN
- Amazon EC2 p3.2xlarge instances for GPU with NVIDIA Tesla V100
- Raspberry Pi 3 (RPi) board
We ran trials for batch sizes of 1, 8, 16, 32, and 64.
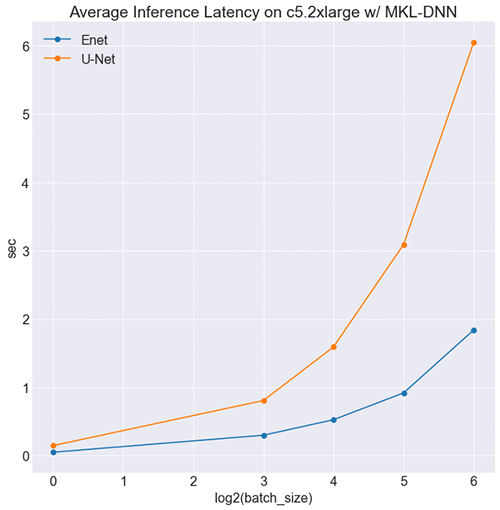
Results for the CPU environment
As shown in the following image, at all batch sizes, ENet runs faster than U-Net and is real-time. ENet is designed to require 75 times less FLOPS than models like U-Net, and the effect on latency is apparent.
Results for the GPU environment
Interestingly, U-Net is faster than ENet at smaller batch sizes, as shown in the following image.
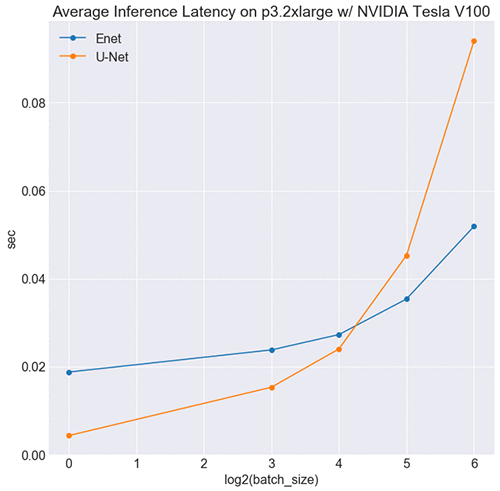
This might seem counterintuitive, but it makes sense when you consider the respective sizes of each network’s symbolic graph. Symbolically ENet is considerably larger than U-Net (see here), which translates to more kernel launches upon inference. At smaller batch sizes, the cost of launching kernels and transferring memory outweighs ENet’s computational gains, and it’s slower. At a certain threshold, the computational efficiency overtakes this cost, and it’s faster than U-Net.
You could ameliorate this by optimizing ENet’s computational graph through NVIDIA TensorRT, which among other things provides kernel fusion. This technique fuses layers and tensors to ensure that each kernel launch maximizes computation. It’s coming soon to MXNet.
Results for the RPi (CPU) environment
Based on results from benchmarking on CPU, we expect ENet to outperform U-Net on RPi, and that is indeed the case, as shown in the following image.
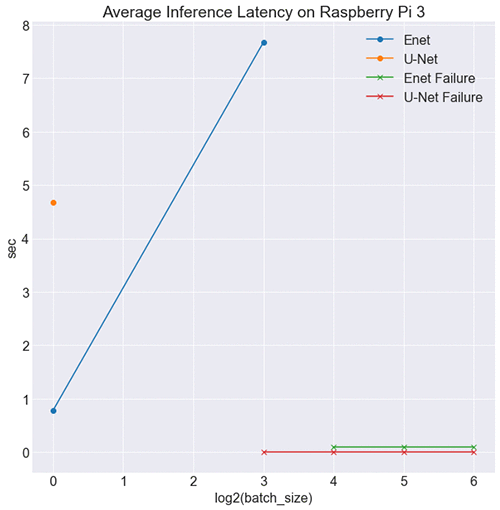
What’s more important is how ENet is effective in a low-resource environment. At batch sizes 16, 32, and 64, the RPi was unable to hold the test data in memory. However, at batch size 8, U-Net failed, and ENet didn’t. This is a testament to ENet’s low impact because the RPi board couldn’t handle U-Net inference for the same batch size. Enet is also low impact in terms of model size, with 1.5 Mb worth of parameters compared to U-Net’s 30 Mb, making it ideal for edge inference.
Conclusion
In Part 1 of this post, we have shown how to train a convolutional neural network to automate brain tissue segmentation by bringing your own MXNet script to Amazon SageMaker. We showed how to test your script locally using local mode and how to shard your data for distributed training jobs. Aside from default endpoint deployment, we demonstrated how you can write custom serving code to respond to Amazon S3 URIs instead of image data. We discussed the tradeoff of accuracy and efficiency between U-Net and ENet, and we determined that ENet is ideal in low-resource environments.
In Part 2, we see how to use AWS Greengrass to deploy our ENet model trained in Amazon SageMaker to an edge device. There it serves inference as a portable ML solution for brain segmentation.
Acknowledgements
This work was made possible with data provided by Open Access Series of Imaging Studies (OASIS), OASIS-1, by Marcus et al., 2007, used under CC BY 4.0.
The following data were provided by OASIS:
- OASIS-3: Principal Investigators: T. Benzinger, D. Marcus, J. Morris; NIH P50AG00561, P30NS09857781, P01AG026276, P01AG003991, R01AG043434, UL1TR000448, R01EB009352. AV-45 doses were provided by Avid Radiopharmaceuticals, a wholly owned subsidiary of Eli Lilly.
- OASIS: Cross-Sectional: Principal Investigators: D. Marcus, R, Buckner, J, Csernansky J. Morris; P50 AG05681, P01 AG03991, P01 AG026276, R01 AG021910, P20 MH071616, U24 RR021382.
- OASIS: Longitudinal: Principal Investigators: D. Marcus, R, Buckner, J. Csernansky, J. Morris; P50 AG05681, P01 AG03991, P01 AG026276, R01 AG021910, P20 MH071616, U24 RR021382.
Publications:
- Open Access Series of Imaging Studies (OASIS): Cross-Sectional MRI Data in Young, Middle Aged, Nondemented, and Demented Older Adults
Marcus, DS, Wang, TH, Parker, J, Csernansky, JG, Morris, JC, Buckner, RL. Journal of Cognitive Neuroscience, 19, 1498-1507. doi: 10.1162/jocn.2007.19.9.1498
About the Author
 Brad Kenstler is a Data Scientist on the Amazon Machine Learning Solutions Lab team. As part of the ML Solutions Lab, he helps AWS customers leverage ML & AI within their own organization for their own business use-cases and processes. His primary field of interest lies in the intersection of computer vision and deep learning. Outside of work, Brad enjoys listening to heavy metal, tasting new bourbons, and watching the San Francisco 49ers.
Brad Kenstler is a Data Scientist on the Amazon Machine Learning Solutions Lab team. As part of the ML Solutions Lab, he helps AWS customers leverage ML & AI within their own organization for their own business use-cases and processes. His primary field of interest lies in the intersection of computer vision and deep learning. Outside of work, Brad enjoys listening to heavy metal, tasting new bourbons, and watching the San Francisco 49ers.
.