Artificial Intelligence
Introducing hybrid machine learning
Gartner predicts that by the end of 2024, 75% of enterprises will shift from piloting to operationalizing artificial intelligence (AI), and the vast majority of workloads will end up in the cloud in the long run. For some enterprises that plan to migrate to the cloud, the complexity, magnitude, and length of migrations may be daunting. The speed of different teams and their appetites for new tooling can vary dramatically. An enterprise’s data science team may be hungry for adopting the latest cloud technology, while the application development team is focused on running their web applications on premises. Even with a multi-year cloud migration plan, some of the product releases must be built on the cloud in order to meet the enterprise’s business outcomes.
For these customers, we propose hybrid machine learning (ML) patterns as an intermediate step in your journey to the cloud. Hybrid ML patterns are those that involve a minimum of two compute environments, typically local compute resources such as personal laptops or corporate data centers, and the cloud. With the hybrid ML architecture patterns described in this post, enterprises can achieve their desired business goals without having to wait for the cloud migration to complete. At the end of the day, we want to support customer success in all shapes and forms.
We have published a new whitepaper, Hybrid Machine Learning, to help you integrate the cloud with existing on-premises ML infrastructure. For more whitepapers from AWS, see AWS Whitepapers & Guides.
Hybrid ML architecture patterns
The whitepaper gives you an overview of the various hybrid ML patterns across the entire ML lifecycle, including ML model development, data preparation, training, deployment, and ongoing management. The following table summarizes the eight different hybrid ML architectural patterns we discuss in the whitepaper. For each pattern, we provide a preliminary reference architecture in addition to the advantages and disadvantages. We also identify a “when to move” criterion to help you make decisions—for example, when the level of effort to maintain and scale a given pattern has exceeded the value it provides.
| Development | Training | Deployment |
| Develop on personal computers, train and host in the cloud | Train locally, deploy in the cloud | Serve ML models in the cloud to applications hosted on premises |
| Develop on local servers, train and host in the cloud | Store data locally, train and deploy in the cloud | Host ML models with Lambda@Edge to applications on premises |
| Develop in the cloud while connecting to data hosted on premises | Train with a third-party SaaS provider to host in the cloud | |
| Train in the cloud, deploy ML models on premises | Orchestrate hybrid ML workloads with Kubeflow and Amazon EKS Anywhere |
In this post, we dive deep into the hybrid architecture pattern for deployment with a focus on serving models hosted in the cloud to applications hosted on premises.
Architecture overview
The most common use case for this hybrid pattern is enterprise migrations. Your data science team may be ready to deploy to the cloud, but your application team is still refactoring their code to host on cloud-native services. This approach enables the data scientists to bring their newest models to market, while the application team separately considers when, where, and how to move the rest of the application to the cloud.
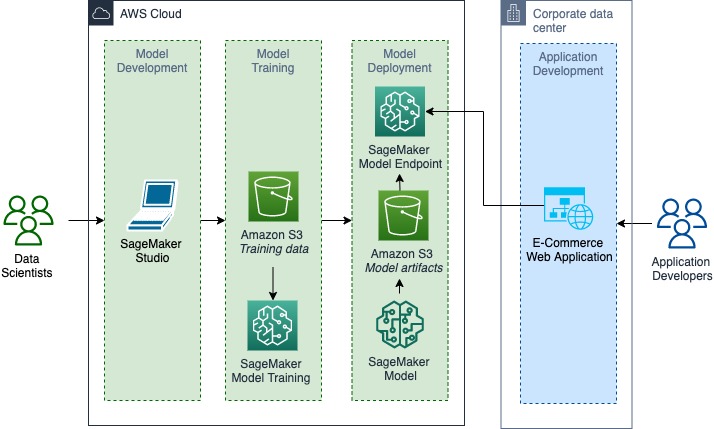
The following diagram shows the architecture for hosting an ML model via Amazon SageMaker in an AWS Region, serving responses to requests from applications hosted on premises.

Technical deep dive
In this section, we dive deep into the technical architecture and focus on the various components that comprise the hybrid workload explicitly and refer to resources elsewhere as necessary.
Let’s take a real-world use case of a retail company whose application development team has hosted their ecommerce web application on premises. The company wants to improve brand loyalty, grow sales and revenue, and increase efficiencies by using data to create more sophisticated and unique customer experiences. They intend to increase customer engagement by 50% by adding a “recommended for you” widget on their home screen. However, they’re struggling to deliver personalized experiences due to the limitations of static, rule-based systems, complexities and costs, and friction with platform integration due to their current legacy, on-premises architecture.
The application team has a 5-year enterprise migration strategy to refactor their web application using cloud-native architecture to move to the cloud, whereas the data science teams are ready to begin implementation in the cloud. With the hybrid architecture pattern described in this post, the company can achieve their desired business outcome quickly without having to wait for the 5-year enterprise migration to complete.
The data scientists develop the ML model, perform training, and deploy the trained model in the cloud. The ecommerce web application that’s hosted on premises consumes the ML model via the exposed endpoints. Let’s walk this through in detail.
In the model development phase, data scientists can use local development environments, such as PyCharm or Jupyter installations on their personal computer, and then connect to the cloud via AWS Identity and Access Management (IAM) permissions and interface with AWS service APIs through the AWS Command Line Interface (AWS CLI) or an AWS SDK (such as Boto3). They also have the flexibility to use Amazon SageMaker Studio, a single web-based visual interface that comes with common data science packages and kernels preinstalled for model development.
Data scientists can take advantage of SageMaker training capabilities, including access to on-demand CPU and GPU instances, automatic model tuning, managed Spot Instances, checkpointing for saving the state of models, managed distributed training, and many more, using the SageMaker training SDK and APIs. For an overview on training models with SageMaker, see Train a Model with Amazon SageMaker.
After the model is trained, data scientists can deploy the models using SageMaker hosting capabilities and expose a REST HTTP(s) endpoint serving predictions to end applications hosted on premises. The application development teams can integrate their on-premises applications to interact with the ML model via SageMaker hosted endpoints to get the inference results. Application developers can access the deployed models through application programming interface (API) requests with response times as low as a few milliseconds. This supports use cases requiring real-time responses, such as personalized product recommendations.
The client application on premises connects with the ML model hosted on the SageMaker hosted endpoint on AWS over a private network using VPN or Direct Connect connection, to provide inference results to its end users. The client application can use any client library to invoke the endpoint using an HTTP Post request along with necessary authentication credentials configured programmatically and the expected payload. SageMaker also has commands and libraries that abstract some of the low-level details such as authentication using the AWS credentials saved in our client application environment, such as the SageMaker invoke-endpoint runtime command from the AWS CLI, SageMaker runtime client from Boto3 (AWS SDK for Python), and the Predictor class from the SageMaker Python SDK.
To make the endpoint accessible over the internet, we can use Amazon API Gateway. Although you can directly access SageMaker hosted endpoints from API Gateway, a common pattern you can use is adding an AWS Lambda function in between. You can use the Lambda function for any preprocessing, which may be needed in order to send the request in the format expected by the endpoint, or postprocessing for transforming the response into the format required by the client application. For more information, see Call an Amazon SageMaker model endpoint using Amazon API Gateway and AWS Lambda.
The client application on premises connects with ML models hosted on SageMaker on AWS over a private network using VPN or Direct Connect connection, to provide inference results to its end users.
The following diagram illustrates how the data science team develops the ML model, performs training, and deploys the trained model in the cloud, while the application development team develops and deploys the ecommerce web application on premises.
After the model is deployed into the production environment, your data scientists can use Amazon SageMaker Model Monitor to continuously monitor the quality of the ML models in real time. They can also set up an automated alert triggering system when deviations in the model quality occur, such as data drift and anomalies. Amazon CloudWatch Logs collects log files monitoring the model status and notifies you when the quality of the model reaches certain thresholds. This enables your data scientists to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually. With AWS Managed Services, your data science team can avoid the downside of implementing monitoring solutions from scratch.
Your data scientists can reduce the overall time required to deploy their ML models in production by automating load testing and model tuning across SageMaker ML instances by using Amazon SageMaker Inference Recommender. It helps your data scientists select the best instance type and configuration (such as instance count, container parameters, and model optimizations) for their ML models.
Lastly, it’s always a best practice to decouple hosting your ML model from hosting your application. In this approach, the data scientists use dedicated resources to host their ML model, specifically ones that are separated from the application, which greatly simplifies the process to push better models. This is a key step in the innovation flywheel. This also prevents any form of tight coupling between the hosted ML model and the application, thereby enabling the model to be highly performant.
In addition to improving the model performance with updated research trends, this approach provides the ability to redeploy a model with updated data. The global COVID-19 pandemic has demonstrated the reality that markets are changing all the time, and the ML model need to stay up to date with the latest trends. The only way you can deliver on that requirement is by being able to retrain and redeploy your model with updated data.
Conclusion
Check out the whitepaper Hybrid Machine Learning, in which we look at additional patterns for hosting ML models via Lambda@Edge, AWS Outposts, AWS Local Zones, and AWS Wavelength. We explore hybrid ML patterns across the entire ML lifecycle. We look at developing locally, while training and deploying in the cloud. We discuss patterns for training locally to deploy on the cloud, and even to host ML models in the cloud to serve applications on premises.
How are you integrating the cloud with your existing on-premises ML infrastructure? Please share your feedback about hybrid ML in the comments so we can continue to improve our products, features, and documentation. If you want to engage the authors of this document for advice on your cloud migration, contact us at hybrid-ml-support@amazon.com.
About the Authors
 Alak Eswaradass is a Solutions Architect at AWS, based in Chicago, Illinois. She is passionate about helping customers design cloud architectures utilizing AWS services to solve business challenges. She hangs out with her daughters and explores the outdoors in her free time.
Alak Eswaradass is a Solutions Architect at AWS, based in Chicago, Illinois. She is passionate about helping customers design cloud architectures utilizing AWS services to solve business challenges. She hangs out with her daughters and explores the outdoors in her free time.
 Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
Emily Webber joined AWS just after SageMaker launched, and has been trying to tell the world about it ever since! Outside of building new ML experiences for customers, Emily enjoys meditating and studying Tibetan Buddhism.
 Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about machine learning and helping customers achieve their business objectives. In his spare time, he enjoys reading and hiking.
Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about machine learning and helping customers achieve their business objectives. In his spare time, he enjoys reading and hiking.