Artificial Intelligence
Personalize your machine translation results by using fuzzy matching with Amazon Translate
A person’s vernacular is part of the characteristics that make them unique. There are often countless different ways to express one specific idea. When a firm communicates with their customers, it’s critical that the message is delivered in a way that best represents the information they’re trying to convey. This becomes even more important when it comes to professional language translation. Customers of translation systems and services expect accurate and highly customized outputs. To achieve this, they often reuse previous translation outputs—called translation memory (TM)—and compare them to new input text. In computer-assisted translation, this technique is known as fuzzy matching. The primary function of fuzzy matching is to assist the translator by speeding up the translation process. When an exact match can’t be found in the TM database for the text being translated, translation management systems (TMSs) often have the option to search for a match that is less than exact. Potential matches are provided to the translator as additional input for final translation. Translators who enhance their workflow with machine translation capabilities such as Amazon Translate often expect fuzzy matching data to be used as part of the automated translation solution.
In this post, you learn how to customize output from Amazon Translate according to translation memory fuzzy match quality scores.
Translation Quality Match
The XML Localization Interchange File Format (XLIFF) standard is often used as a data exchange format between TMSs and Amazon Translate. XLIFF files produced by TMSs include source and target text data along with match quality scores based on the available TM. These scores—usually expressed as a percentage—indicate how close the translation memory is to the text being translated.
Some customers with very strict requirements only want machine translation to be used when match quality scores are below a certain threshold. Beyond this threshold, they expect their own translation memory to take precedence. Translators often need to apply these preferences manually either within their TMS or by altering the text data. This flow is illustrated in the following diagram. The machine translation system processes the translation data—text and fuzzy match scores— which is then reviewed and manually edited by translators, based on their desired quality thresholds. Applying thresholds as part of the machine translation step allows you to remove these manual steps, which improves efficiency and optimizes cost.
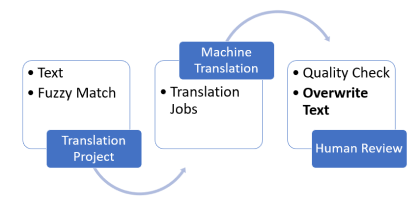
Figure 1: Machine Translation Review Flow
The solution presented in this post allows you to enforce rules based on match quality score thresholds to drive whether a given input text should be machine translated by Amazon Translate or not. When not machine translated, the resulting text is left to the discretion of the translators reviewing the final output.
Solution Architecture
The solution architecture illustrated in Figure 2 leverages the following services:
- Amazon Simple Storage Service – Amazon S3 buckets contain the following content:
- Fuzzy match threshold configuration files
- Source text to be translated
- Amazon Translate input and output data locations
- AWS Systems Manager – We use Parameter Store parameters to store match quality threshold configuration values
- AWS Lambda – We use two Lambda functions:
- One function preprocesses the quality match threshold configuration files and persists the data into Parameter Store
- One function automatically creates the asynchronous translation jobs
- Amazon Simple Queue Service – An Amazon SQS queue triggers the translation flow as a result of new files coming into the source bucket
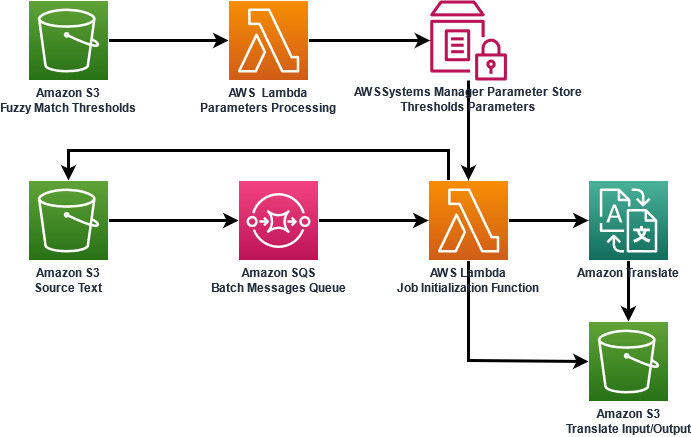
Figure 2: Solution Architecture
You first set up quality thresholds for your translation jobs by editing a configuration file and uploading it into the fuzzy match threshold configuration S3 bucket. The following is a sample configuration in CSV format. We chose CSV for simplicity, although you can use any format. Each line represents a threshold to be applied to either a specific translation job or as a default value to any job.
The specifications of the configuration file are as follows:
- Column 1 should be populated with the name of the XLIFF file—without extension—provided to the Amazon Translate job as input data.
- Column 2 should be populated with the quality match percentage threshold. For any score below this value, machine translation is used.
- For all XLIFF files whose name doesn’t match any name listed in the configuration file, the default threshold is used—the line with the keyword
defaultset in Column 1.
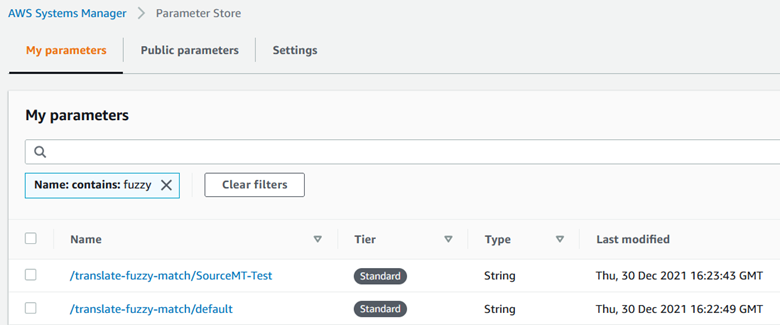
Figure 3: Auto-generated parameter in Systems Manager Parameter Store
When a new file is uploaded, Amazon S3 triggers the Lambda function in charge of processing the parameters. This function reads and stores the threshold parameters into Parameter Store for future usage. Using Parameter Store avoids performing redundant Amazon S3 GET requests each time a new translation job is initiated. The sample configuration file produces the parameter tags shown in the following screenshot.
The job initialization Lambda function uses these parameters to preprocess the data prior to invoking Amazon Translate. We use an English-to-Spanish translation XLIFF input file, as shown in the following code. It contains the initial text to be translated, broken down into what is referred to as segments, represented in the source tags.
The source text has been pre-matched with the translation memory beforehand. The data contains potential translation alternatives—represented as <alt-trans> tags—alongside a match quality attribute, expressed as a percentage. The business rule is as follows:
- Segments received with alternative translations and a match quality below the threshold are untouched or empty. This signals to Amazon Translate that they must be translated.
- Segments received with alternative translations with a match quality above the threshold are pre-populated with the suggested target text. Amazon Translate skips those segments.
Let’s assume the quality match threshold configured for this job is 80%. The first segment with 99% match quality isn’t machine translated, whereas the second segment is, because its match quality is below the defined threshold. In this configuration, Amazon Translate produces the following output:
In the second segment, Amazon Translate overwrites the target text initially suggested (Selección) with a higher quality translation: Visita de selección.
One possible extension to this use case could be to reuse the translated output and create our own translation memory. Amazon Translate supports customization of machine translation using translation memory thanks to the parallel data feature. Text segments previously machine translated due to their initial low-quality score could then be reused in new translation projects.
In the following sections, we walk you through the process of deploying and testing this solution. You use AWS CloudFormation scripts and data samples to launch an asynchronous translation job personalized with a configurable quality match threshold.
Prerequisites
For this walkthrough, you must have an AWS account. If you don’t have an account yet, you can create and activate one.
Launch AWS CloudFormation stack
- Choose Launch Stack:

- For Stack name, enter a name.
- For ConfigBucketName, enter the S3 bucket containing the threshold configuration files.
- For ParameterStoreRoot, enter the root path of the parameters created by the parameters processing Lambda function.
- For QueueName, enter the SQS queue that you create to post new file notifications from the source bucket to the job initialization Lambda function. This is the function that reads the configuration file.
- For SourceBucketName, enter the S3 bucket containing the XLIFF files to be translated. If you prefer to use a preexisting bucket, you need to change the value of the CreateSourceBucket parameter to No.
- For WorkingBucketName, enter the S3 bucket Amazon Translate uses for input and output data.
- Choose Next.

Figure 4: CloudFormation stack details
- Optionally on the Stack Options page, add key names and values for the tags you may want to assign to the resources about to be created.
- Choose Next.
- On the Review page, select I acknowledge that this template might cause AWS CloudFormation to create IAM resources.
- Review the other settings, then choose Create stack.
AWS CloudFormation takes several minutes to create the resources on your behalf. You can watch the progress on the Events tab on the AWS CloudFormation console. When the stack has been created, you can see a CREATE_COMPLETE message in the Status column on the Overview tab.
Test the solution
Let’s go through a simple example.
- Download the following sample data.
- Unzip the content.
There should be two files: an .xlf file in XLIFF format, and a threshold configuration file with .cfg as the extension. The following is an excerpt of the XLIFF file.
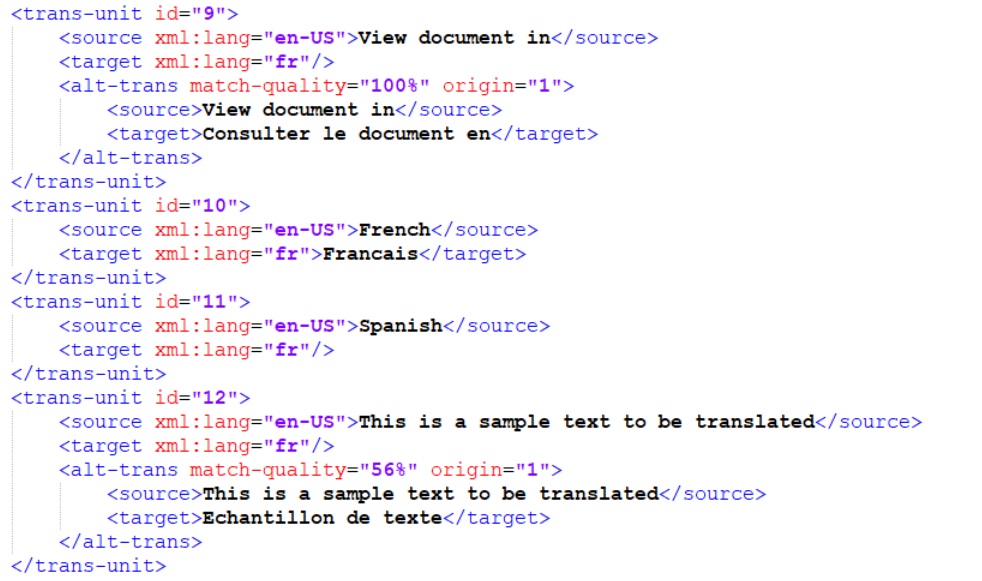
Figure 5: English to French sample file extract
- On the Amazon S3 console, upload the quality threshold configuration file into the configuration bucket you specified earlier.
The value set for test_En_to_Fr is 75%. You should be able to see the parameters on the Systems Manager console in the Parameter Store section.
- Still on the Amazon S3 console, upload the .xlf file into the S3 bucket you configured as source. Make sure the file is under a folder named
translate(for example,<my_bucket>/translate/test_En_to_Fr.xlf).
This starts the translation flow.
- Open the Amazon Translate console.
A new job should appear with a status of In Progress.

Figure 6: In progress translation jobs on Amazon Translate console
- Once the job is complete, click into the job’s link and consult the output. All segments should have been translated.
All segments should have been translated. In the translated XLIFF file, look for segments with additional attributes named lscustom:match-quality, as shown in the following screenshot. These custom attributes identify segments where suggested translation was retained based on score.

Figure 7: Custom attributes identifying segments where suggested translation was retained based on score
These were derived from the translation memory according to the quality threshold. All other segments were machine translated.
You have now deployed and tested an automated asynchronous translation job assistant that enforces configurable translation memory match quality thresholds. Great job!
Cleanup
If you deployed the solution into your account, don’t forget to delete the CloudFormation stack to avoid any unexpected cost. You need to empty the S3 buckets manually beforehand.
Conclusion
In this post, you learned how to customize your Amazon Translate translation jobs based on standard XLIFF fuzzy matching quality metrics. With this solution, you can greatly reduce the manual labor involved in reviewing machine translated text while also optimizing your usage of Amazon Translate. You can also extend the solution with data ingestion automation and workflow orchestration capabilities, as described in Speed Up Translation Jobs with a Fully Automated Translation System Assistant.
About the Authors
 Narcisse Zekpa is a Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their adoption of the AWS Cloud, by providing architectural guidelines, design innovative, and scalable solutions. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, and playing basketball.
Narcisse Zekpa is a Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their adoption of the AWS Cloud, by providing architectural guidelines, design innovative, and scalable solutions. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, and playing basketball.
 Dimitri Restaino is a Solutions Architect at AWS, based out of Brooklyn, New York. He works primarily with Healthcare and Financial Services companies in the North East, helping to design innovative and creative solutions to best serve their customers. Coming from a software development background, he is excited by the new possibilities that serverless technology can bring to the world. Outside of work, he loves to hike and explore the NYC food scene.
Dimitri Restaino is a Solutions Architect at AWS, based out of Brooklyn, New York. He works primarily with Healthcare and Financial Services companies in the North East, helping to design innovative and creative solutions to best serve their customers. Coming from a software development background, he is excited by the new possibilities that serverless technology can bring to the world. Outside of work, he loves to hike and explore the NYC food scene.