Artificial Intelligence
Powering a search engine with Amazon SageMaker
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
This is a guest post by Evan Harris, Manager of Machine Learning at Ibotta. In their own words, “Ibotta is transforming the shopping experience by making it easy for consumers to earn cash back on everyday purchases through a single smartphone app. The company partners with leading brands and retailers to offer offers on groceries, electronics, clothing, gifts, home and office supplies, restaurant dining, and more.”
The technical divisions within high-growth, mid-stage companies are prone to a unique set of challenges. High on the list for many such companies is building quality applications quickly and effectively.
On the machine learning (ML) team at Ibotta—a mobile app that offers cash back on everyday purchases for millions of users—we have done a good deal of thinking and experimentation on this topic. I would like to share how we leverage AWS to achieve core functionality, such as search with Amazon SageMaker.
In this post, I discuss the architecture of Ibotta’s search engine and how we use Amazon SageMaker with other AWS services to integrate real-time ML into the search experience of our mobile application. I hope that this post can shorten your search for a feasible solution to the comparable challenges in your organization, no matter the organization size.
Creating a streamlined mobile app experience, complete with a comprehensive and user-friendly search flow, is crucial for our business. Customers searching for deals before shopping must find useful content quickly or they’re liable to give up.
With a dedicated team of search relevancy engineers, ML engineers, designers, and mobile developers, we use as much modern technology as possible to rapidly develop and test new, creative improvements to our search relevancy. We prioritize the use of ML to inject data-driven intelligence into our search engine, pushing us beyond traditional information retrieval techniques.
Foundational search infrastructure
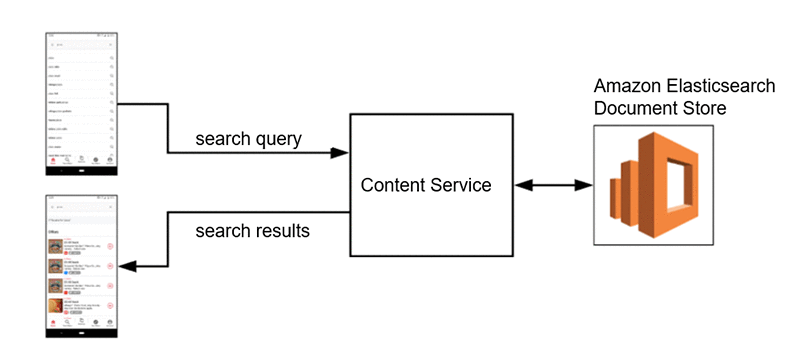
Our core infrastructure for search at Ibotta rests on our app’s array of microservices. Indexed documents live in Amazon OpenSearch Service, which contains all of the content available to the mobile client at a given point in time. An internal content service talks to this document store on request and provides additional rules-based filtering functionality to ensure that only content available to the user making the request is returned.
The content service can receive input search queries and respond with relevant content, taking other contextual considerations into account. The service uses textbook lucene-style search relevancy techniques to retrieve appropriate content in the OpenSearch document store.
ML-enhanced search infrastructure
The foundational search infrastructure leaves substantial room for improvement. Ibotta’s search problem space has unique challenges, particularly revolving content. One week, there might be an offer for certain brands in the app and another week they are gone. This is driven by the retailers with whom we partner, as they often want to promote an item only for a limited time.
Additionally, some brands and product categories are not available in the app at all, as we have yet to work with those retailers. We still want to show related content to users when their search queries don’t match exact content in the app. For example, a search for a non-carried brand of coffee should return other coffee brands that match across important attributes (flavor, size, price, etc.).
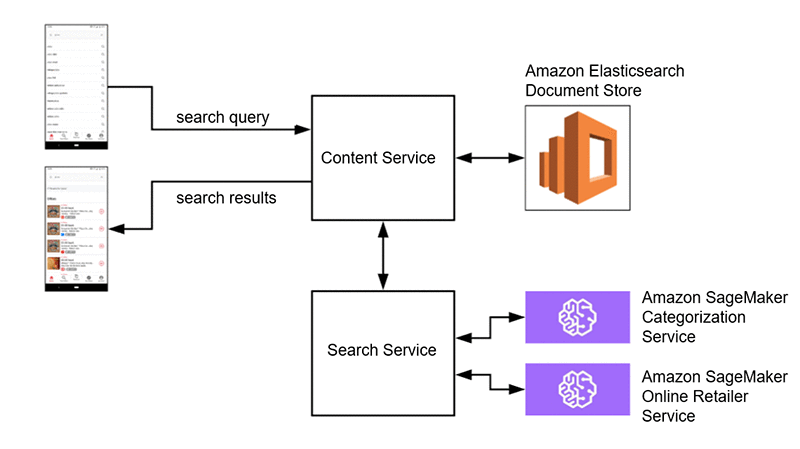
The solution here is query expansion. This is a common search technique that takes the user’s search query and adds context to it before querying the data store. In one case, we can add value by categorizing the search query in real time, enhancing the content retrieval and sorting algorithm. In other cases, after categorization, we’d like to look up and sort online retailers that specialize in the predicted category and return those as suggestions to the user.
To make these category inferences on-demand in real time, we use Amazon SageMaker. We can easily train models and deploy them as fully managed REST APIs to which internal microservices can make requests. An example request and response looks something like the following code:
| Request | Response |
We use BlazingText, an algorithm built in to Amazon SageMaker. The supervised version of BlazingText is a powerful, flexible, and easy to use text classification model. Out of the box, we get scalable distributed training, Bayesian hyperparameter optimization, and real-time inference endpoint deployment. We’ve spent substantial time training and deploying our own text classification models for other use cases. We found a lot to like using the built-in Amazon SageMaker model and managed training and deployment service.
In one view, below is the architecture of our ML-enhanced search services architecture. As you’ll see, the querying and retrieval mechanism described above (and captured here as well) is complemented by SageMaker, which provides two distinct value-adds. First, it enables us to categorize the search query to deliver more relevant results, and second, it enables us to provide online retailers whose offerings are relevant to the query.
An additional ML value-add is our UPC barcode scan feature. Users can scan barcodes of consumer products with our app. If purchasing that UPC satisfies an offer, we return exact matches. If there isn’t an exact match, we use an unsupervised text similarity algorithm to find related offers to suggest to the user. If they can get cash back with our app, perhaps they will consider an alternative to the product that they scanned.
With the UPC feature, we know upfront the universe of UPCs for which we potentially have a similarity suggestion. Predictions can be made offline and written to an online data store, from which our services can make low-latency requests in real time. We use a combination of Amazon S3, AWS Lambda, Apache Airflow, and Amazon DynamoDB for this process. We see that addition to our architecture in the following diagram, in which the UPC input becomes a search query against which we execute.
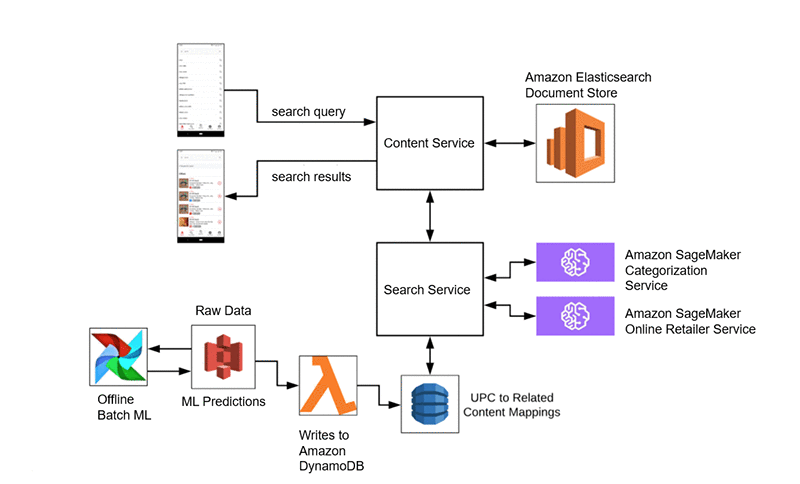
We then get a mix of on-demand and batch ML models used as needed to enhance our search experience. With a broad services toolset, we are able to select the right tool for the job. Our production environment consists of fully managed AWS services, including offline data storage, online data storage, data transfer, and ML services.
Building to scale
When technologists talk about building to scale, they are often referring to horizontal scalability—perhaps something like Amazon S3 for storage or managed Kubernetes for compute. With these services, horizontal scaling is effectively infinite.
However, it’s often also useful to talk about scalability in terms of our ability to add new functionality to our services without overcomplicating any individual service or code base. Using microservices built on top of AWS, we are able to add or upgrade features while imposing minimal risk to the existing ecosystem.
We are also able to compartmentalize ownership, particularly allowing ML engineers to own their own services end-to-end. As long as the API contract doesn’t change, the ML team can iterate on their models independent of any contact with the owners of dependent services. Amazon SageMaker enables developers with basic Python skills and ML knowledge to support production microservices that integrate directly into our stack.
This sets us up for future iterations of our search service architecture that don’t require substantial cross functional efforts:
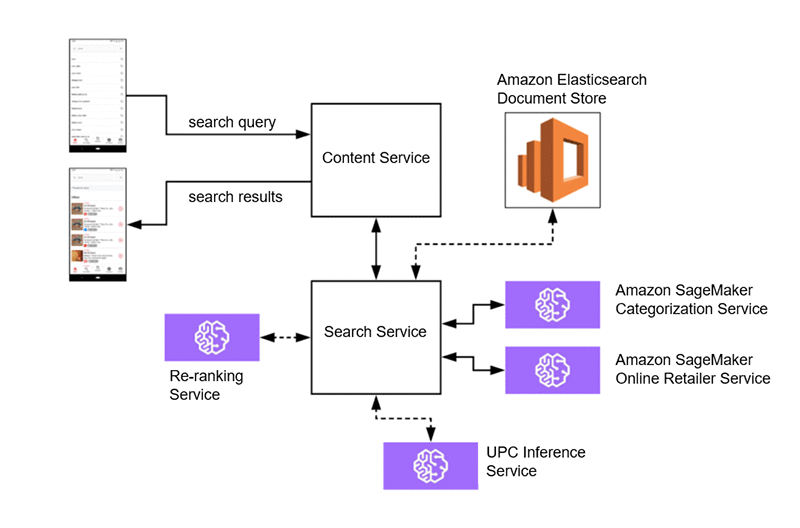
In this setup, perhaps we migrate our UPC prediction pipeline to an Amazon SageMaker service capable of more advanced feature extraction and inference from UPCs to predict related content. We can also migrate our OpenSearch document store to sit directly behind the search service for more specialized search-oriented document indexing. Then we solely rely on the content service for rules-based user level filtering.
Finally, an exciting ML use case is learning to rank. After the search service retrieves a candidate set of content, we can use an Amazon SageMaker service to dynamically re-rank content in real time. This can factor in known features about content, personalization, as well as trends and seasonality.
Thanks to AWS, we have architecture that sets us up for success. We compartmentalize project work with simple integration points and ownership is clear and straightforward. ML teams can build simple services that integrate directly with our backend platform, all on top of managed infrastructure.
Conclusion
We study how the tech giants like Airbnb, Etsy, Linkedin, Wayfair, and Pinterest operate their search engines and strive to do the same at Ibotta. We regularly think about how our engineering team is comparatively fractional in size. Yet we are well-equipped to deliver similar experiences with the setup we have: our own microservices on top of AWS. The AWS services that we rely on enable us to do rapid iteration and testing that would otherwise be out of reach or impossibly slow to implement. With AWS as our preferred AI/ML provider and the underpinning of our tech stack, we’re excited about what’s next.