Artificial Intelligence
Scaling medical content review at Flo Health using Amazon Bedrock (Part 1)
This blog post is based on work co-developed with Flo Health.
Healthcare science is rapidly advancing. Maintaining accurate and up-to-date medical content directly impacts people’s lives, health decisions, and well-being. When someone searches for health information, they are often at their most vulnerable, making accuracy not just important, but potentially life-saving.
Flo Health creates thousands of medical articles every year, providing millions of users worldwide with medically credible information on women’s health. Verifying the accuracy and relevance of this vast content library is a significant challenge. Medical knowledge evolves continuously, and manual review of each article is not only time-consuming but also prone to human error. This is why the team at Flo Health, the company behind the leading women’s health app Flo, is using generative AI to facilitate medical content accuracy at scale. Through a partnership with AWS Generative AI Innovation Center, Flo Health is developing an innovative approach, further called, “Medical Automated Content Review and Revision Optimization Solution” (MACROS) to verify and maintain the accuracy of its extensive health information library. This AI-powered solution is capable of:
- Efficiently processing large volumes of medical content based on credible scientific sources.
- Identifying potential inaccuracies or outdated information based on credible scientific resources.
- Proposing updates based on the latest medical research and guidelines, as well as incorporating user feedback.
The system powered by Amazon Bedrock enables Flo Health to conduct medical content reviews and revision assessments at scale, ensuring up-to-date accuracy and supporting more informed healthcare decision-making. This system performs detailed content analysis, providing comprehensive insights on medical standards and guidelines adherence for Flo’s medical experts to review. It is also designed for seamless integration with Flo’s existing tech infrastructure, facilitating automatic updates where appropriate.
This two-part series explores Flo Health’s journey with generative AI for medical content verification. Part 1 examines our proof of concept (PoC), including the initial solution, capabilities, and early results. Part 2 covers focusing on scaling challenges and real-world implementation. Each article stands alone while collectively showing how AI transforms medical content management at scale.
Proof of Concept goals and success criteria
Before diving into the technical solution, we established clear objectives for our PoC medical content review system:
Key Objectives:
- Validate the feasibility of using generative AI for medical content verification
- Determine accuracy levels compared to manual review
- Assess processing time and cost improvements
Success Metrics:
- Accuracy: Content piece recall of 90%
- Efficiency: Reduce detection time from hours to minutes per guideline
- Cost Reduction: Reduce expert review workload
- Quality: Maintain Flo’s editorial standards and medical accuracy
- Speed: 10x faster than manual review process
To verify the solution meets Flo Health’s high standards for medical content, Flo Health’s medical experts and content teams were working closely with AWS technical specialists through regular review sessions, providing critical feedback and medical expertise to continuously enhance the AI model’s performance and accuracy. The result is MACROS, our custom-built solution for AI-assisted medical content verification.
Solution overview
In this section, we outline how the MACROS solution uses Amazon Bedrock and other AWS services to automate medical content review and revisions.
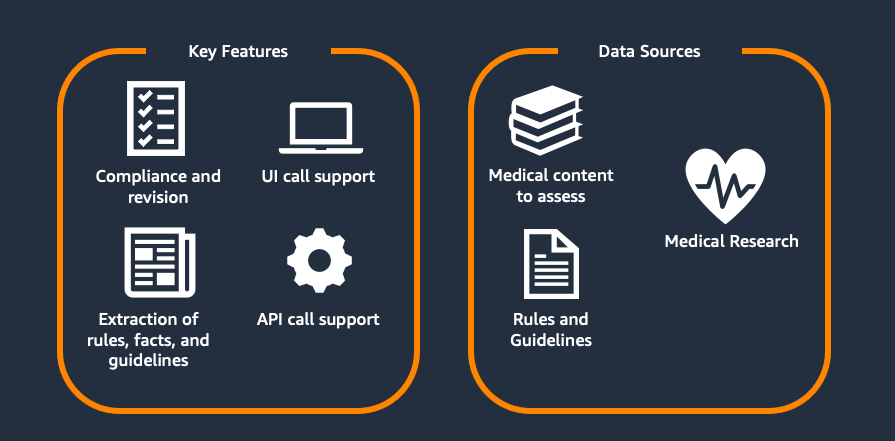
Figure 1. Medical Automated Content Review and Revision Optimization Solution Overview
As shown in Figure 1, the developed solution supports two major processes:
- Content Review and Revision: Enables the medical standards and style adherence of existing medical articles at scale given the pre-specified custom rules and guidelines and proposes a revision that conforms to the new medical standards as well as Flo’s style and tone guidelines.
- Rule Optimization: MACROS accelerates the process of extracting the new (medical) guidelines from the (medical) research, pre-processing them into the format needed for content review, as well as optimizing their quality.
Both steps can be conducted through the user interface (UI) as well as the direct API call. The UI support enables medical experts to directly see the content review statistics, interact with changes, and do manual adjustments. The API call support is intended for the integration into pipeline for periodic assessment.
Architecture
Figure 2 depicts the architecture of MACROS. It consists of two major parts: backend and frontend.
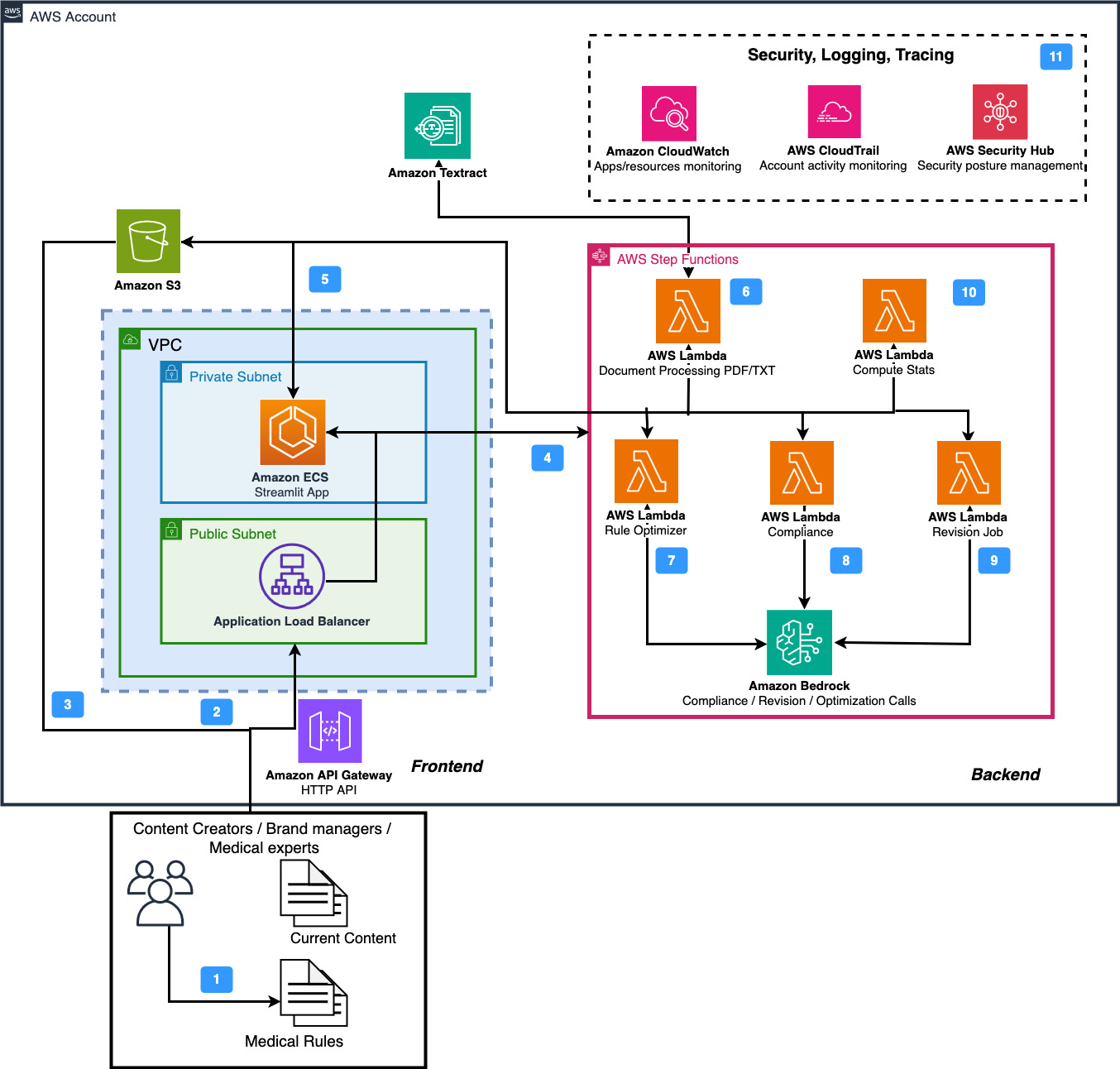
Figure 2. MACROS architecture
In the following, the flow of major app components is presented:
1. Users begin by gathering and preparing content that must meet medical standards and rules.
2. In the second step, the data is provided as PDF, TXT files or text through the Streamlit UI that is hosted in Amazon Elastic Container Service (ECS). The authentication for file upload happens through Amazon API Gateway
3. Alternatively, custom Flo Health JSON files can be directly uploaded to the Amazon Simple Storage Service (S3) bucket of the solution stack.
4. The ECS hosted frontend has AWS IAM permissions to orchestrate tasks using AWS Step Functions.
5. Further, the ECS container has access to the S3 for listing, downloading and uploading files either via pre-signed URL or boto3.
6. Optionally, if the input file is uploaded via the UI, the solution invokes AWS Step Functions service that starts the pre-processing functionality within hosted by an AWS Lambda function. This Lambda has access to Amazon Textract for extracting text from PDF files. The files are stored in S3 and also returned to the UI.
7-9. Hosted on AWS Lambda, Rule Optimizer, Content Review and Revision functions are orchestrated via AWS Step Function. They have access to Amazon Bedrock for generative AI capabilities to perform rule extraction from unstructured data, content review and revision, respectively. Furthermore, they have access to S3 via boto3 SDK to store the results.
10. The Compute Stats AWS Lambda function has access to S3 and can read and combine the results of individual revision and review runs.
11. The solution leverages Amazon CloudWatch for system monitoring and log management. For production deployments dealing with critical medical content, the monitoring capabilities could be extended with custom metrics and alarms to provide more granular insights into system performance and content processing patterns.
Future enhancements
While our current architecture utilizes AWS Step Functions for workflow orchestration, we’re exploring the potential of Amazon Bedrock Flows for future iterations. Bedrock Flows offers promising capabilities for streamlining AI-driven workflows, potentially simplifying our architecture and enhancing integration with other Bedrock services. This alternative could provide more seamless management of our AI processes, especially as we scale and evolve our solution.
Content review and revision
At the core of MACROS lies its Content Review and Revision functionality with Amazon Bedrock foundation models. The Content Review and Revision block consists of five major components: 1) The optional Filtering stage 2) Chunking 3) Review 4) Revision and 5) Post-processing, depicted in Figure 3.
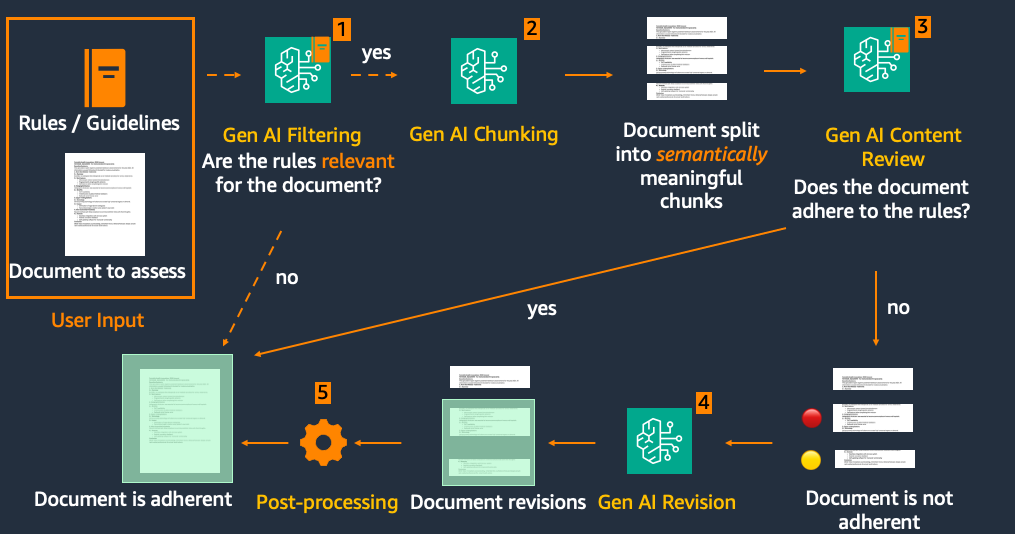
Figure 3. Content review and revision pipeline
Here’s how MACROS processes the uploaded medical content:
- Filtering (Optional): The journey begins with an optional filtering step. This smart feature checks whether the set of rules is relevant for the article, potentially saving time and resources on unnecessary processing.
- Chunking: The source text is then split into paragraphs. This crucial step facilitates good quality assessment and helps prevent unintended revisions to unrelated text. Chunking can be conducted using heuristics, such as punctuation or regular expression-based splits, as well as using large language models (LLM) to identify semantically complete chunks of text.
- Review: Each paragraph or section undergoes a thorough review against the relevant rules and guidelines.
- Revision: Only the paragraphs flagged as non-adherent move forward to the revision stage, streamlining the process and maintaining the integrity of adherent content. The AI suggests updates to bring non-adherent paragraphs in line with the latest guidelines and Flo’s style requirements.
- Post-processing: Finally, the revised paragraphs are seamlessly integrated back into the original text, resulting in an updated, adherent document.
The Filtering step can be conducted using an additional LLM via Amazon Bedrock call that assesses each section separately with the following prompt structure:
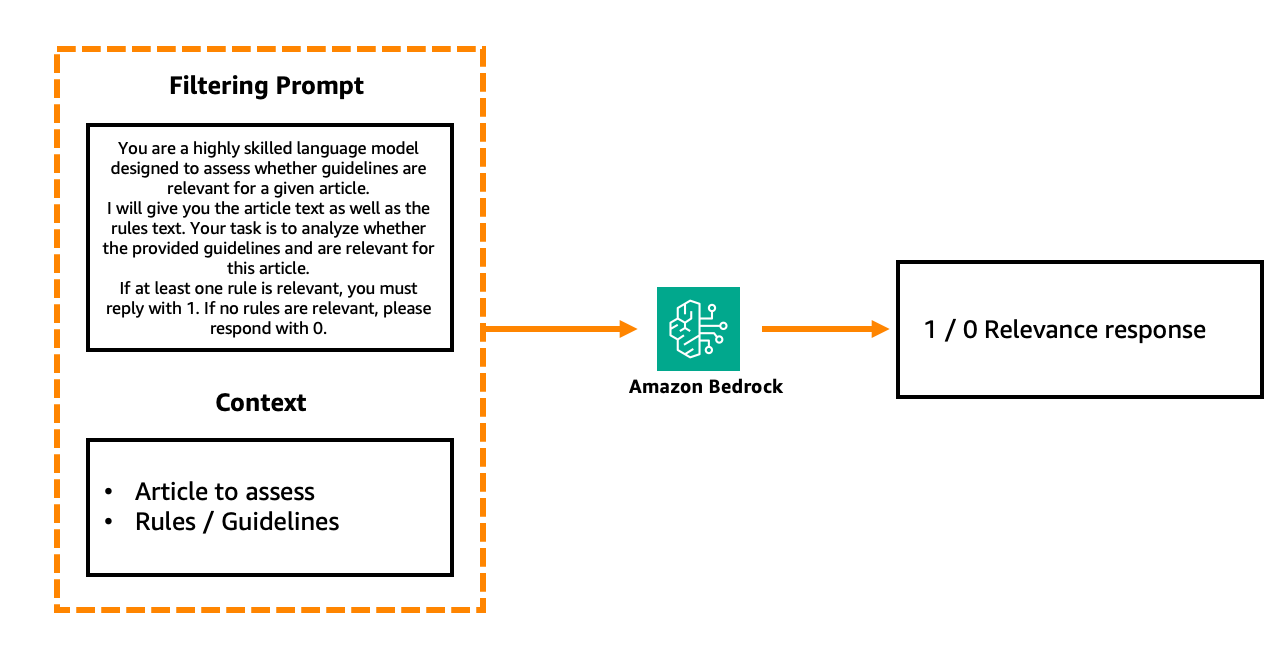
Figure 4. Simplified LLM-based filtering step
Further, non-LLM approaches can be feasible to support the Filtering step:
- Encoding the rules and the articles into dense embedding vectors and calculating similarity between them. By setting the similarity threshold we can identify which rule set is considered to be relevant for the input document.
- Similarly, the direct keyword-level overlap between the document and the rule can be identified using BLEU or ROUGE metrics.
Content review, as already mentioned, is conducted on a text section basis against group of rules and leads to response in XML format, such as:
Here, 1 indicates adherence and 0 – non-adherence of the text to the specified rules. Using XML format helps to achieve reliable parsing of the output.
This Review step iterates over the sections in the text to make sure that the LLM pays attention to each section separately, which led to more robust results in our experimentation. To facilitate higher non-adherent section detection accuracy, the user can also use the Multi-call mode, where instead of one Amazon Bedrock call assessing adherence of the article against all rules, we have one independent call per rule.
The Revision step receives the output of the Review (non-adherent sections and the reasons for non-adherence), as well as the instruction to create the revision in a similar tone. It then suggests revisions of the non-adherent sentences in a style similar to the original text. Finally, the Post-processing step combines the original text with new revisions, making sure that no other sections are changed.
Different steps of the flow require different levels of LLM model complexity. While simpler tasks like chunking can be done efficiently with a relatively small model like Claude Haiku models family, more complex reasoning tasks like content review and revision require larger models like Claude Sonnet or Opus models family to facilitate accurate analysis and high-quality content generation. This tiered approach to model selection optimizes both performance and cost-efficiency of the solution.
Operating modes
The Content Review and Revision feature operates in two UI modes: Detailed Document Processing and Multi Document Processing, each catering to different scales of content management. The Detailed Document Processing mode offers a granular approach to content assessment and is depicted in Figure 5. Users can upload documents in various formats (PDF, TXT, JSON or paste text directly) and specify the guidelines against which the content should be evaluated.

Figure 5. Detailed Document Processing example
Users can choose from predefined rule sets, here, Vitamin D, Breast Health, and Premenstrual Syndrome and Dysphoric Disorder (PMS and PMDD), or input custom guidelines. These custom guidelines can include rules such as “The title of the article must be medically accurate” as well as adherent and non-adherent to the rule examples of content.
The rulesets make sure that the assessment aligns with specific medical standards and Flo’s unique style guide. The interface allows for on-the-fly adjustments, making it ideal for thorough, individual document reviews. For larger-scale operations, the Multi Document Processing mode should be used. This mode is designed to handle numerous custom JSON files simultaneously, mimicking how Flo would integrate MACROS into their content management system.
Extracting rules and guidelines from unstructured data
Actionable and well-prepared guidelines are not always immediately available. Sometimes they are given in unstructured files or need to be found. Using the Rule Optimizer feature, we can extract and refine actionable guidelines from multiple complex documents.
Rule Optimizer processes raw PDF documents to extract text, which is then chunked into meaningful sections based on document headers. This segmented content is processed through Amazon Bedrock using specialized system prompts, with two distinct modes: Style/tonality and Medical mode.
Style/tonality mode focuses on extracting the guidelines on how the text should be written, its style, what formats and words can or cannot be used.
Rule Optimizer assigns a priority for each rule: high, medium, and low. The priority level indicates the rule’s importance, guiding the order of content review and focusing attention on critical areas first. Rule Optimizer includes a manual editing interface where users can refine rule text, adjust classifications, and manage priorities. Therefore, if users need to update a given rule, the changes are stored for future use in Amazon S3.
The Medical mode is designed to process medical documents and is adapted to a more scientific language. It allows grouping of extracted rules into three classes:
- Medical condition guidelines
- Treatment specific guidelines
- Changes to advice and trends in health
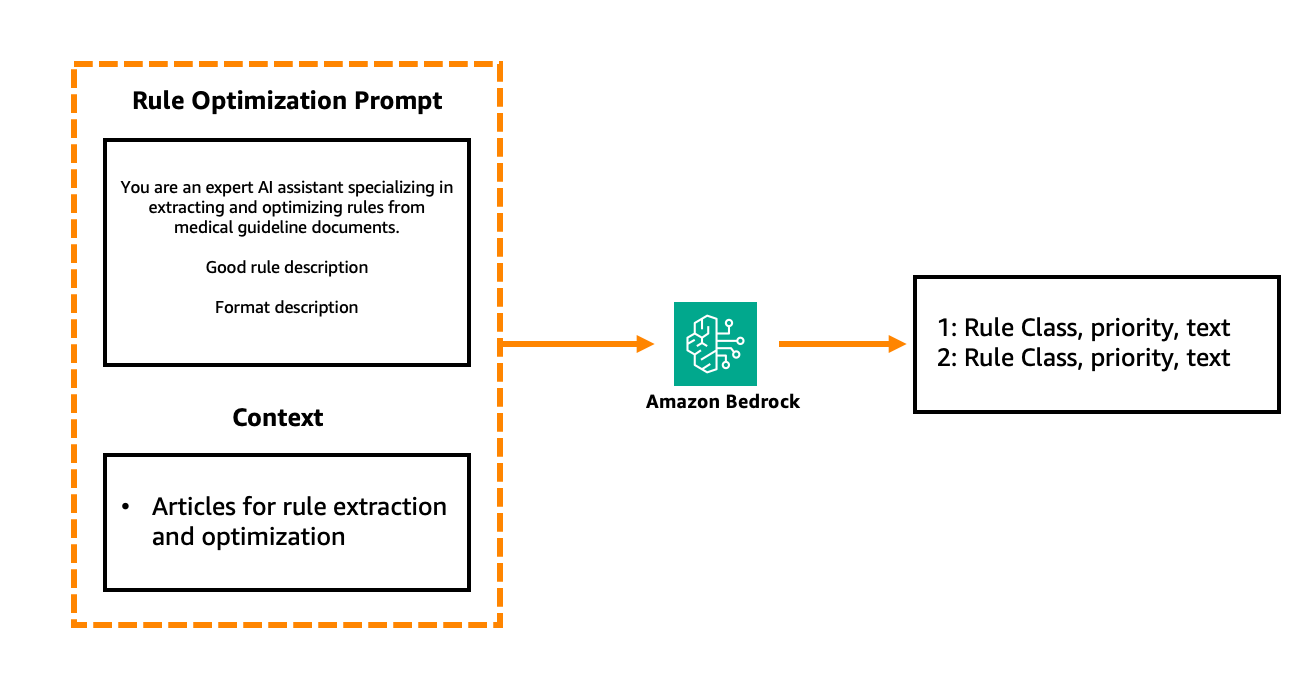
Figure 6. Simplified medical rule optimization prompt
Figure 6 provides an example of a medical rule optimization prompt, consisting of three main components: role setting – medical AI expert, description of what makes a good rule, and finally the expected output. We identify the sufficiently good quality for a rule if it is:
- Clear, unambiguous, and actionable
- Relevant, consistent, and concise (max two sentences)
- Written in active voice
- Avoids unnecessary jargon
Implementation considerations and challenges
During our PoC development, we identified several crucial considerations that would benefit others implementing similar solutions:
- Data preparation: This emerged as a fundamental challenge. We learned the importance of standardizing input formats for both medical content and guidelines while maintaining consistent document structures. Creating diverse test sets across different medical topics proved essential for comprehensive validation.
- Cost management: Monitoring and optimizing cost quickly became a key priority. We implemented token usage tracking and optimized prompt design and batch processing to balance performance and efficiency.
- Regulatory and ethical compliance: Given the sensitive nature of medical content, strict regulatory and ethical safeguards were critical. We established robust documentation practices for AI decisions, implemented strict version control for medical guidelines and continuous human medical expert oversight for the AI-generated suggestions. Regional healthcare regulations were carefully considered throughout implementation.
- Integration and scaling: We recommend starting with a standalone testing environment while planning for future content management system (CMS) integration through well-designed API endpoints. Building with modularity in mind proved valuable for future enhancements. Throughout the process, we faced common challenges such as maintaining context in long medical articles, balancing processing speed with accuracy, and facilitating consistent tone across AI-suggested revisions.
- Model optimization: The diverse model selection capability of Amazon Bedrock proved particularly valuable. Through its platform, we can choose optimal models for specific tasks, achieve cost efficiency without sacrificing accuracy, and smoothly upgrade to newer models – all while maintaining our existing architecture.
Preliminary Results
Our Proof of Concept delivered strong results across the critical success metrics, demonstrating the potential of AI-assisted medical content review. The solution exceeded target processing speed improvements while maintaining 80% accuracy and over 90% recall in identifying content requiring updates. Most notably, the AI-powered system applied medical guidelines more consistently than manual reviews and significantly reduced the time burden on medical experts.
Key Takeaways
During implementation, we uncovered several insights critical for optimizing AI performance in medical content analysis. Content chunking was essential for accurate assessment across long documents, and expert validation of parsing rules helped medical experts to maintain clinical precision.Most importantly, the project confirmed that human-AI collaboration – not full automation – is key to successful implementation. Regular expert feedback and clear performance metrics guided system refinements and incremental improvements. While the system significantly streamlines the review process, it works best as an augmentation tool, with medical experts remaining essential for final validation, creating a more efficient hybrid approach to medical content management.
Conclusion and next steps
This first part of our series demonstrates how generative AI can make the medical content review process faster, more efficient, and scalable while maintaining high accuracy. Stay tuned for Part 2 of this series, where we cover the production journey, deep diving into challenges and scaling strategies.Are you ready to move your AI initiatives into production?
- Learn more about the AWS Generative AI Innovation Center and contact your AWS Account Manager to be connected to our expert guidance and support.
- Visit the Amazon Bedrock documentation to learn more about available foundation models and their capabilities
- Join our AWS Builder community to connect with others on a similar AI journey.
About the authors
 Liza (Elizaveta) Zinovyeva, Ph.D., is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
Liza (Elizaveta) Zinovyeva, Ph.D., is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
 Callum Macpherson is a Data Scientist at the AWS Generative AI Innovation Center, where cutting-edge AI meets real-world business transformation. Callum partners directly with AWS customers to design, build, and scale generative AI solutions that unlock new opportunities, accelerate innovation, and deliver measurable impact across industries.
Callum Macpherson is a Data Scientist at the AWS Generative AI Innovation Center, where cutting-edge AI meets real-world business transformation. Callum partners directly with AWS customers to design, build, and scale generative AI solutions that unlock new opportunities, accelerate innovation, and deliver measurable impact across industries.
 Arefeh Ghahvechi is a Senior AI Strategist at the AWS GenAI Innovation Center, specializing in helping customers realize rapid value from generative AI technologies by bridging innovation and implementation. She identifies high-impact AI opportunities while building the organizational capabilities needed for scaled adoption across enterprises and national initiatives.
Arefeh Ghahvechi is a Senior AI Strategist at the AWS GenAI Innovation Center, specializing in helping customers realize rapid value from generative AI technologies by bridging innovation and implementation. She identifies high-impact AI opportunities while building the organizational capabilities needed for scaled adoption across enterprises and national initiatives.
 Nuno Castro is a Sr. Applied Science Manager. He’s has 19 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 11 years.
Nuno Castro is a Sr. Applied Science Manager. He’s has 19 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 11 years.
![]() Dmitrii Ryzhov is a Senior Account Manager at Amazon Web Services (AWS), helping digital-native companies unlock business potential through AI, generative AI, and cloud technologies. He works closely with customers to identify high-impact business initiatives and accelerate execution by orchestrating strategic AWS support, including access to the right expertise, resources, and innovation programs.
Dmitrii Ryzhov is a Senior Account Manager at Amazon Web Services (AWS), helping digital-native companies unlock business potential through AI, generative AI, and cloud technologies. He works closely with customers to identify high-impact business initiatives and accelerate execution by orchestrating strategic AWS support, including access to the right expertise, resources, and innovation programs.
 Nikita Kozodoi, PhD, is a Senior Applied Scientist at the AWS Generative AI Innovation Center working on the frontier of AI research and business. Nikita builds and deploys generative AI and ML solutions that solve real-world problems and drive business impact for AWS customers across industries.
Nikita Kozodoi, PhD, is a Senior Applied Scientist at the AWS Generative AI Innovation Center working on the frontier of AI research and business. Nikita builds and deploys generative AI and ML solutions that solve real-world problems and drive business impact for AWS customers across industries.
 Aiham Taleb, PhD, is a Senior Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.
Aiham Taleb, PhD, is a Senior Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.