AWS for M&E Blog
How to set up a resilient end-to-end live workflow using AWS Elemental products and services: Part 2
Part 1: Single-region reference architecture deployment walkthrough: The Fundamentals
Part 2: Single-region reference architecture deployment walkthrough: Advanced Workflows (This Post)
Part 3: Multi-regions reference architecture deployment walkthrough: Advanced Workflows
Part 4: High-Availability Advanced Workflows with Automatic Failover
Single-region reference architecture deployment walkthrough: Advanced Workflows
In the first part of this blog series, we covered the fundamentals of building resilient OTT live workflows with AWS Elemental Live, AWS Elemental MediaLive, and AWS Elemental MediaPackage combined with Amazon CloudFront. In this post, we’ll explore how you can extend resilience across the content contribution pipeline with AWS Elemental Conductor, AWS Elemental MediaConnect for video transport, MediaLive input switching, and HLS output locking in AWS Elemental Live.
Contribution failover orchestration with AWS Elemental Conductor
Our previous post described a resilient architecture with two AWS Elemental Live appliances handling contribution. Although this is designed to generate two active/active synced video streams to contribute to MediaLive, a hardware failure is still possible. In situations that call for a significant number of simultaneous streams and encoding appliances, such as 24/7 linear or event-based use cases, it becomes critical to automate the failover of the contribution layer. With Conductor, you can either adopt an N+1 redundancy approach (as shown on the diagram) in which a single backup encoder can replace one of your primary encoders in case of failure, or a N+M redundancy approach, which puts multiple backup encoders on standby, ready to failover any encoder from the primary pool. The choice between the two scenarios is largely driven by your redundancy requirements and the available budget. Finally, you can choose to deploy Conductorin high availability mode by running several instances of it in a cluster. This lets you overcome any hardware problems on a single Conductor Live appliance as well.
 Fig.1
Fig.1
In the scenario shown in figure 1, we have three AWS Elemental Live encoders to minimize the cost of the setup. You will need to configure a Redundancy Group in Conductor Live 3, with the two first encoders declared as Active Nodes and the third one declared as a Backup Node. In the Channels section, you will need to create one channel for the primary stream and one channel for the backup stream, each attached to a different encoder. If one of these encoders fails, Conductor will deploy the corresponding encoding configuration on the spare encoder and trigger the failover. If needed, you can follow a step-by-step configuration walkthrough in these two instructional videos:
Resilient contribution transport with AWS Elemental MediaConnect
Whether you ingest your contribution feeds into the AWS Cloud over the public internet or via an AWS Direct Connect link, you may wish to add a layer of reliability to your video transport.
AWS Elemental MediaConnect was launched on AWS during re:Invent 2018. It is a reliable, secure and flexible transport service for live video that allows you to build transformation and distribution workflows quickly and cost-effectively. Here we focus on the transformation workflow, in conjunction with AWS Elemental Live and AWS Elemental MediaLive. For the ingest, MediaConnect supports RTP, RTP with FEC, and Zixi protocols. (In the previous blog post, we used RTP with FEC on the output of AWS Elemental Live; we now switch to Zixi with MediaConnect as the Zixi protocol provides better packet recovery and bandwidth optimization than RTP/FEC, making it a better option for initial ingest over long distances. For setup, all you have to do is configure two MediaConnect flows (in different Availability Zones) in the AWS console and use the “Reliable TS” output group type in AWS Elemental Live. You will need to use the flows ARNs as target, your IAM user Access Key ID and Secret Access Key as the credentials, and “AWS Elemental MediaConnect” as the Delivery Protocol. Detailed configuration steps, including optional Encryption settings, are included in here.
 Fig 2.
Fig 2.
On the AWS Elemental MediaLive side, setup is as easy as replacing the previous RTP input with a new AWS Elemental MediaConnect flow as the input when creating the channel. Inside the AWS region, the MediaLive ingest endpoints will be automatically configured to match the same Availability Zones as the MediaConnect flows. The result will be a highly reliable ingest pipeline from your on-premises encoders to your MediaLive channel.
If you want to monitor the AWS version of the contribution feeds that you send over each MediaConnect flow, you can configure a new MediaConnect flow to push output in RTP, RTP/FEC, or Zixi protocol, and just declare the IP:port of your receiver. MediaConnect will then start to push the stream using the selected protocol. For software-only monitoring, you can use Zixi’s free MediaConnect Receiver with Zixi transport or VLC with RTP transport. If you need SDI monitoring on-premises, you can use a Zixi receiver with SDI output, such as a T-21 9261 decoder.
Disaster recovery with multiple contribution sites and AWS Elemental MediaLive input switching
MediaLive was recently extended to support multiple inputs, with a maximum of two push live inputs out of the twenty inputs supported. As each live input group actually supports one primary ingest endpoint and a secondary endpoint, this means a MediaLive channel can be fed with a total of four different live sources, with two of them active at a given moment as sources for the primary and secondary encoding pipelines. An input group switch can be scheduled through the AWS Command Line Interface (CLI) or the API, with a time target at least 15 seconds in the future. (The time reference passed is the absolute time when the switch is expected, not the timecode of the live sources.)

Fig 3.
This feature can be used seamlessly for maintenance purposes, for example, by switching to the secondary contribution source just before the primary one is due for upgrades. However, the input groups switch mechanism is not natively designed to provide a seamless failover between the two contribution sites if one goes offline, because it requires 15 seconds of scheduling delay. That said, it is entirely possible to use this mechanism for disaster recovery purposes, with a reasonable failover delay for such a use case, by combining AWS Lambda functions and Amazon CloudWatch alerts.
Accomplishing this requires creating a simple Lambda mechanism that lists MediaLive channels with two input groups and enables a manual switch between these input groups, with a persistence of the active input group in Amazon DynamoDB. Once the mechanism has been used manually once, any future input group switches can be triggered automatically by Lambda functions based on the CloudWatch alerts received when a UDP input goes down. When such an issue occurs, the following type of alert will be generated (important fields are highlight ted in yellow):
{“version”:”0″,
“id”:”56b0302c-5d0d-cdfd-a137-0d06d7023017″,
“detail-type”:”MediaLive Channel Alert”,
“source”:”aws.medialive”,
“account”:”123456789012″,
“time”:”2019-02-04T16:52:41Z”,
“region”:”eu-west-1″,
“resources”:[“arn:aws:medialive:eu-west-1: 123456789012:channel:7654321”],
“detail”:{“alarm_state”:”SET”,“alarm_id”:”746bb739cf029666bcddfe95e888070cd218a6ce”,
“alert_type”:”Stopped Receiving UDP Input”,
“pipeline”:”0″,
“channel_arn”:”arn:aws:medialive:eu-west-1: 123456789012:channel:7654321″,
“message”:”Stopped receiving network data on [rtp://localhost:5000]”}}
If the same alarm_id doesn’t appear again with an alarm_state CLEARED after a threshold of a few seconds, it means that the input for pipeline 0 is down, and you can store this information in DynamoDB. If you get the same confirmed alert for pipeline 1, then it means that you can schedule an input groups switch through Lambda. Lambda will call the MediaLive schedule API in order to failover to the contribution streams coming from your disaster recovery site and flag input group B as active in DynamoDB. If the same situation occurs with input group B, you will be able to failback to input group A if it is once again up and running.
Ground-to-cloud failover with AWS Elemental Live and AWS Elemental MediaPackage
If your produce all of your ABR renditions on-premises with AWS Elemental Live encoders and use MediaPackage to prepare and secure your final distribution formats on AWS, you can take advantage of “Output Locking” to achieve ground-to-cloud failover. By synchronizing your HLS ingest streams and using the MediaPackage input redundancy feature, you can seamlessly switch between your primary and backup HLS streams and produce non-interrupted output streams with frame-accurate input switching. Output Locking works much like MediaLive pipeline synching, but in an on-premises context. Here is the corresponding workflow.
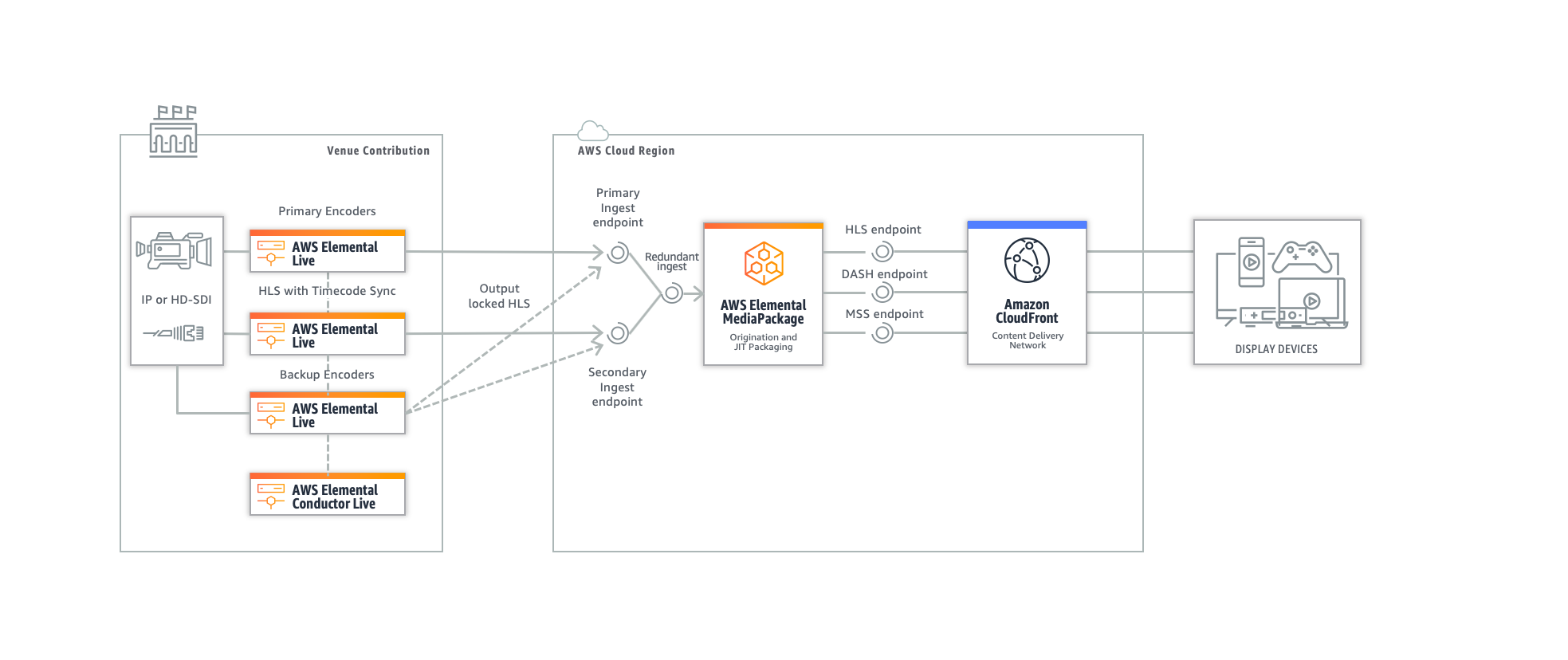 Fig 4.
Fig 4.
To configure this functionality, you create a HLS event as you typically would on your Live encoder and activate the Output Locking feature in the Global Processors section. Using a multicast communication channel between the encoders is mandatory if you want to synchronize streams on more than two encoders, exactly as you would if using a spare encoder managed by Conductor. Simply use a multicast address and whitelist the port in the encoder firewall.

More information about this setup is available here.
Once this is done, you can benefit from frame-accurate failover, as all the incoming HLS segments are aligned in terms of segmentation, timing and content on both MediaPackage inputs.
In the next blog post, we will explore even more demanding 24×7 or event-based streaming scenarios that call for greater workflow resilience and review how customers can use multiple AWS regions for encoding and origination.