亚马逊AWS官方博客
使用 AWS Glue DataBrew 和 Amazon QuickSight 简化半结构化嵌套 JSON 数据分析
解决方案概览
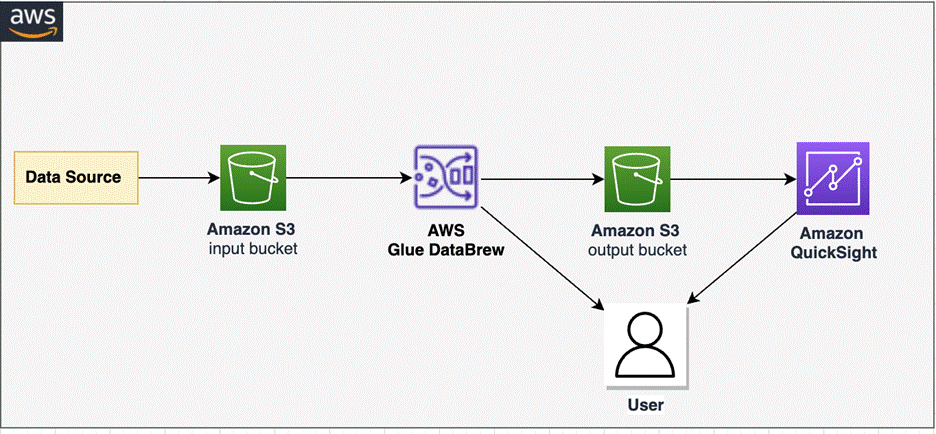
为了实施我们的解决方案,我们创建了一个 DataBrew 项目和 DataBrew 作业来取消嵌套数据。我们在 DataBrew 中剖析未嵌套的数据,然后在 QuickSight 中分析数据。下图展示了我们的解决方案架构。
先决条件
在开始操作之前,请务必满足以下先决条件:
- 一个 AWS 账户
- 基本了解 Amazon Simple Storage Service(Amazon S3)
- 基本了解 QuickSight 以便创建控制面板
- 创建 DataBrew 数据集、项目和作业、S3 存储桶和 QuickSight 控制面板所需的权限
- DataBrew 可使用的 AWS Identity and Access Management(IAM)角色,或用于创建新的 IAM 角色的权限(请参阅添加和删除 IAM 身份权限以了解更多信息)
准备数据
为了说明支持嵌套 JSON 文件的数据分析的 DataBrew 功能,我们使用了公开可用的客户订单详细信息嵌套 JSON 数据集示例。
完成以下步骤以准备数据:
- 登录 AWS 管理控制台。
- 在 Amazon S3 控制台上浏览到公开可用的数据集。
- 选择第一个数据集(
customer_1.json),然后选择 Download(下载)以将文件保存在本地计算机上。 - 重复此步骤以下载所有三个 JSON 文件。

您可以使用任意文本编辑器查看本地计算机上的示例数据,如以下屏幕截图所示。

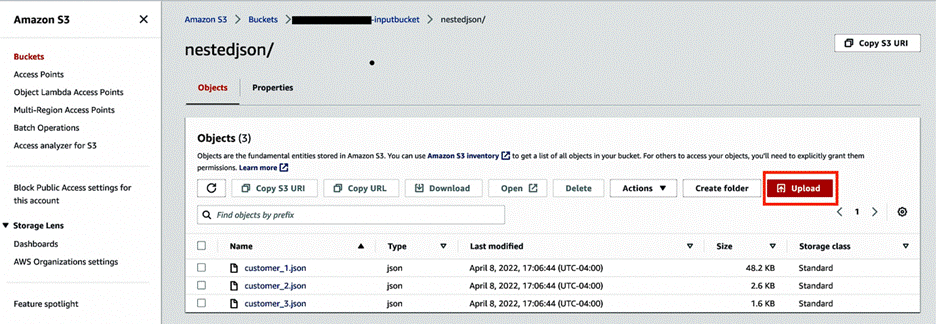
- 使用子文件夹
nestedjson和outputjson创建输入和输出 S3 存储桶以捕获数据。 - 选择 Upload(上传)并将三个 JSON 文件上传到
nestedjson文件夹。
创建 DataBrew 项目
要创建 Amazon S3 连接,请完成以下步骤:
- 在 DataBrew 控制台上的导航窗格中,选择 Projects(项目)。
- 选择 Create project(创建项目)。
- 对于 Project name(项目名称),输入
Glue-DataBew-NestedJSON-Blog。

- 选择 New dataset(新数据集)。
- 对于 Dataset name(数据集名称),输入
Glue-DataBew-NestedJSON-Dataset。 - 对于 Enter your source from S3(输入来自 S3 的源),输入
nestedjson文件夹的路径。 - 选择 Select the entire folder(选择整个文件夹)以选择所有文件。
- 在 Additional configurations(其他配置)下,选择 JSON 作为文件类型,然后选择 JSON document(JSON 文档)。

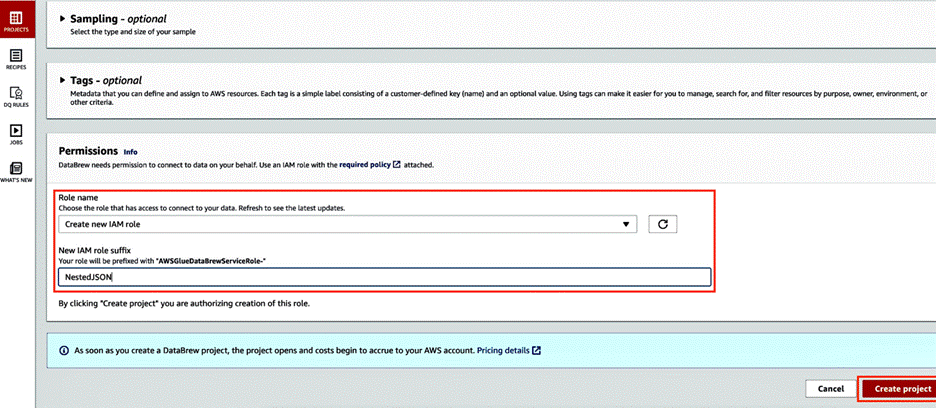
- 在 Permissions(权限)部分中,选择 Choose existing IAM role(选择现有 IAM 角色)(如果您有可用的 IAM 角色),或选择 Create new IAM role(创建新的 IAM 角色)。
- 选择 Create project(创建项目)。
- 跳过预览步骤,并等待项目准备就绪。
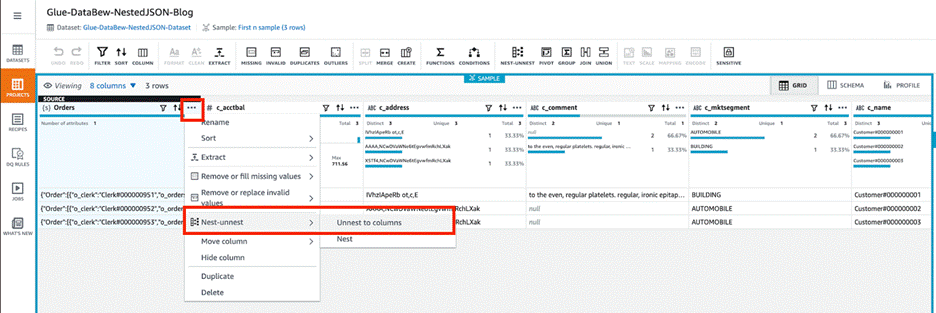
如以下屏幕截图所示,三个 JSON 文件已上传到 S3 存储桶,因此加载了三个客户订单详细信息行。

订单列包含嵌套文件。我们可以使用 DataBrew 来取消嵌套或嵌套转换来扁平化列和行。 - 选择菜单图标(三个点),然后选择 Nest-unnest。
- 根据嵌套情况,选择 Unnest to columns(取消嵌套到列)或 Unnest to rows(取消嵌套到行)。在本博文中,我们选择 Unnest to columns(取消嵌套到列)来扁平化示例 JSON 文件。
重复此步骤,直到获得所有嵌套的 json 数据的扁平化 json,这将创建 AWS Glue Databrew 配方,如下所示。

- 选择 Apply(应用)。
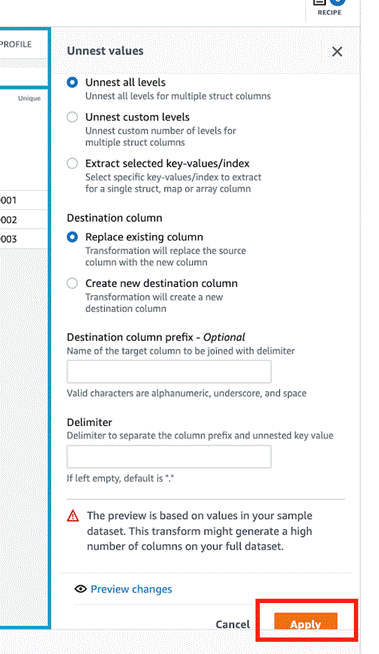
DataBrew 使用更新后的列值自动创建所需的配方步骤。 - 选择 Create job(创建作业)。
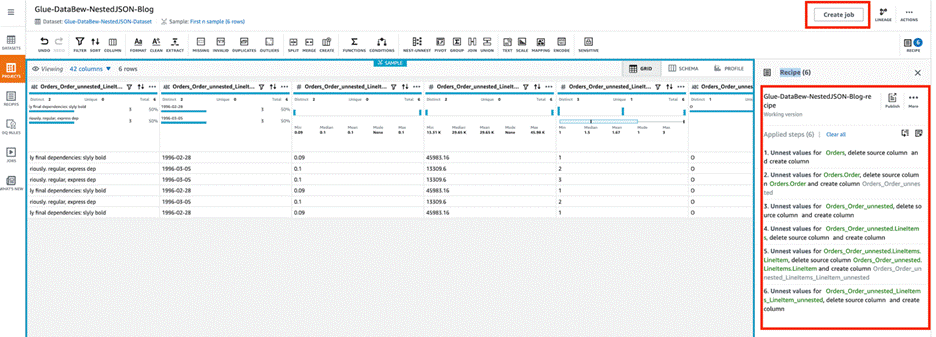
- 对于 Job name(作业名称),输入
Glue-DataBew-NestedJSON-job。 - 对于 S3 location(S3 位置),输入
outputjson文件夹的路径。

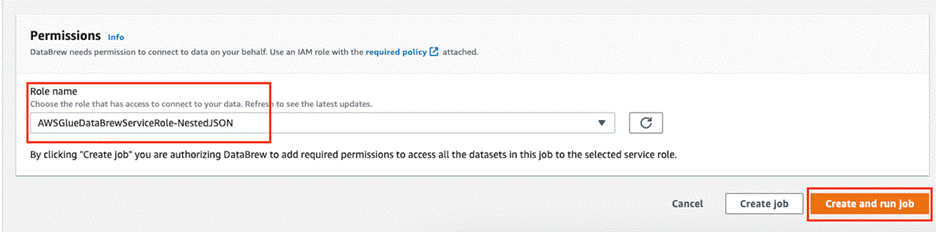
- 在 Permissions(权限)部分中,对于 Role name(角色名称),选择之前创建的角色。
- 选择 Create and run job(创建并运行作业)。
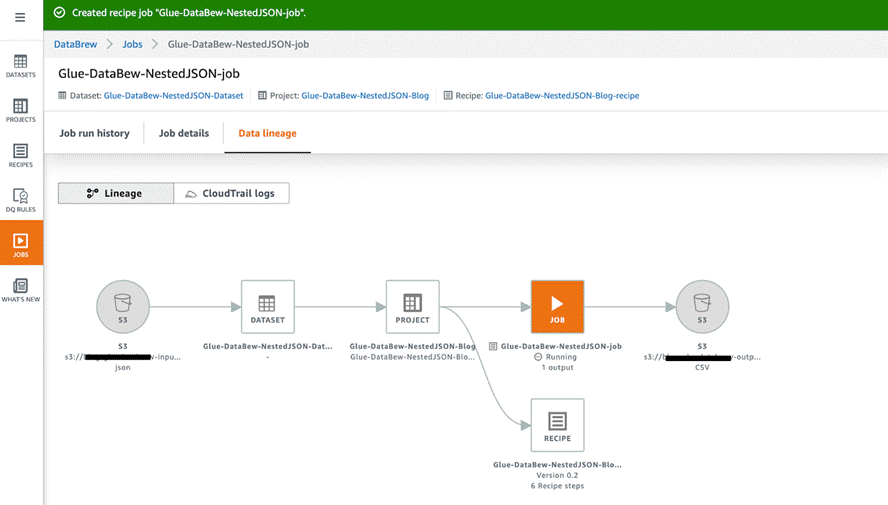
在 Jobs(作业)页面上,您可以选择作业以查看其运行历史记录、详细信息和数据世系。
使用 DataBrew 剖析元数据
在 S3 输出存储桶中具有扁平化文件后,您可以使用 DataBrew 对扁平化文件进行数据分析和剖析。请完成以下步骤:
- 在 Datasets(数据集)页面上,选择 Connect new dataset(连接新数据集)。
- 提供您的数据集详细信息并选择 Create dataset(创建数据集)。

- 选择新添加的数据来源,然后选择 Data profile overview(数据剖析概览)选项卡。

- 输入作业名称和 S3 路径以保存输出。
- 选择 Create and run job(创建并运行作业)。
作业大约需要两分钟才能完成,并且将显示所有更新后的信息。您可以在 Data profile overview(数据剖析概览)和 Column statistics(列统计数据)选项卡上进一步浏览数据。

在 QuickSight 中可视化数据
在 S3 输出存储桶中获得 DataBrew 所生成的输出文件后,您可以使用 QuickSight 查询 JSON 数据。QuickSight 是一款专为云构建的可扩展、无服务器、可嵌入、基于机器学习的商业智能(BI)服务。借助 QuickSight,您可以轻松创建和发布包含基于机器学习的见解的交互式人工智能控制面板。可以从任意设备访问 QuickSight 控制面板,并将其无缝嵌入到您的应用程序、门户和网站中。
启动 QuickSight
在控制台上,在搜索栏中输入 quicksight 并选择 QuickSight。

您将看到 QuickSight 欢迎页面。如果您尚未注册 QuickSight,则可能需要完成注册向导。有关更多信息,请参阅注册 Amazon QuickSight 订阅。
在您完成注册后,QuickSight 会显示一个“欢迎向导”。 您可以查看这个简短教程,也可以将其关闭。

授予 Amazon S3 访问权限
要授予 Amazon S3 访问权限,请完成以下步骤:
- 在 QuickSight 控制台上,选择您的用户名,再选择 Manage QuickSight(管理 QuickSight),然后选择 Security & permissions(安全性和权限)。
- 选择 Add or remove(添加或删除)。
- 在列表中找到 Amazon S3。选择下列选项之一:
- 如果该复选框已清除,请选择 Amazon S3。
- 如果该复选框已选中,请选择 Details(详细信息),然后选择 Select S3 buckets(选择 S3 存储桶)。
- 从 QuickSight 中选择要访问的存储桶,然后选择 Select(选择)。
- 选择 Update(更新)。
- 如果您在此过程的第一步中更改了区域,请将它更改回要使用的区域。
创建数据集
现在,您已启动并运行 QuickSight,可以创建数据集了。请完成以下步骤:
- 在 QuickSight 控制台上的导航窗格中,选择 Datasets(数据集)。

- 选择 New dataset(新数据集)。

QuickSight 支持多个数据来源。有关完整列表,请参阅支持的数据来源。 - 对于您的数据来源,请选择 S3。

S3 导入需要数据来源名称和清单文件。 - 在您的计算机上,在文本编辑器中使用以下结构创建一个名为
BlogGlueDataBrew.manifest的清单文件(提供输出存储桶的名称):该清单文件指向您之前作为 DataBrew 项目的一部分创建的文件夹。有关更多信息,请参阅 Amazon S3 清单文件的支持格式。
- 选择 Upload(上传)并导航到该清单文件以将其上传。
- 选择 Connect(连接)以将数据上传到 SPICE,它是内置于 QuickSight 中的内存数据库,可实现快速性能。

- 选择 Visualize(可视化)。
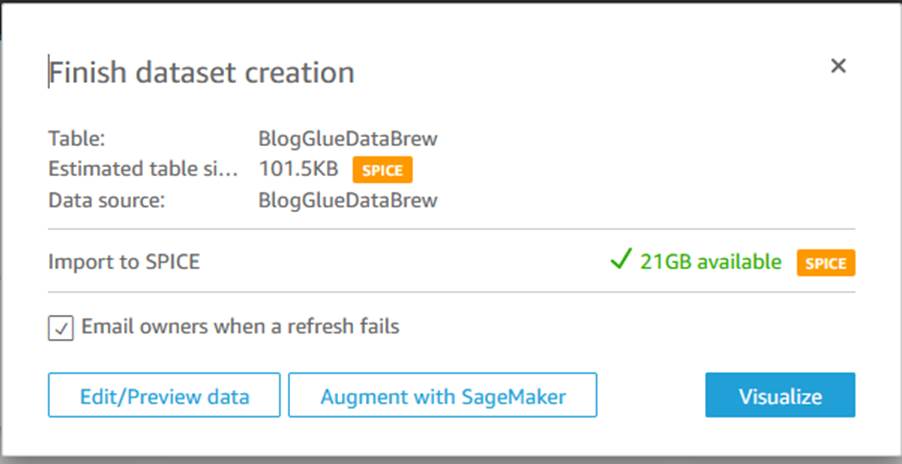
现在,您可以通过添加不同的字段来创建视觉效果。
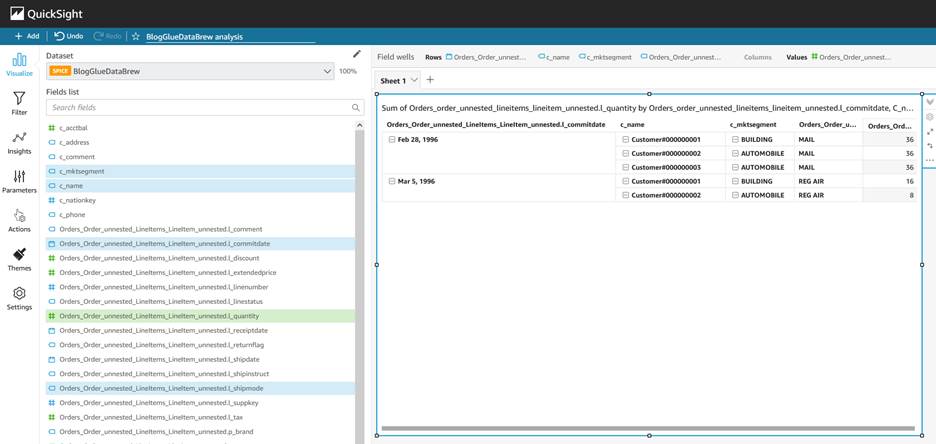
要详细了解如何在 QuickSight 中创作控制面板,请查看 QuickSight 创作研讨会。
清理
完成以下步骤可避免将来产生费用:
- 在 DataBrew 控制台上的导航窗格中,选择 Projects(项目)。
- 选择您创建的项目,然后在 Actions(操作)菜单上,选择 Delete(删除)。
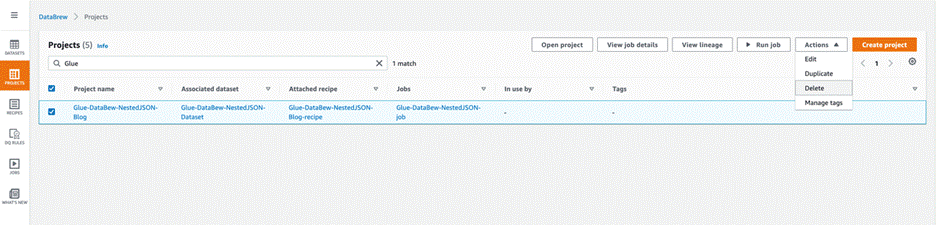
- 在导航窗格中,选择 Jobs(作业)。
- 选择您创建的作业,然后在 Actions(操作)菜单上,选择 Delete(删除)。
- 在导航窗格中,选择 Recipes(配方)。
- 选择您创建的配方,然后在 Actions(操作)菜单上,选择 Delete(删除)。
- 在 QuickSight 控制面板上,在应用程序栏上选择您的用户名,然后选择 Manage QuickSight(管理 QuickSight)。
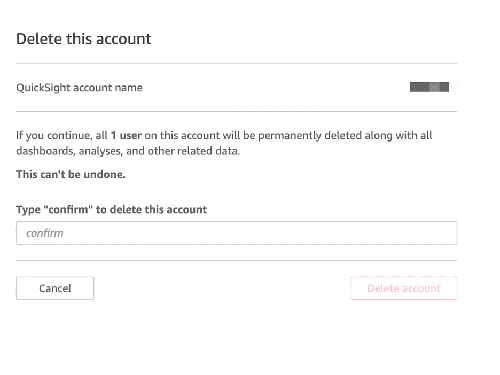
- 选择 Account settings(账户设置),然后选择 Delete account(删除账户)。
- 选择 Delete account(删除账户)。

- 输入
confirm(确认)并选择 Delete account(删除账户)。
结论
本博文说明了如何配置 DataBrew 以处理嵌套的 JSON 对象,以及如何使用 QuickSight 进行数据可视化。我们已使用 Glue DataBrew 取消嵌套 JSON 文件并剖析数据,然后使用 QuickSight 创建控制面板和可视化来进行深入分析。
当您需要在不编写代码的情况下取消嵌套复杂的半结构化 JSON 文件时,可以将此解决方案用于您自己的使用案例。
关于作者
 Sriharsh Adari 是 Amazon Web Services(AWS)的高级解决方案架构师,他帮助客户从业务成果向后工作,以便在 AWS 上开发创新性解决方案。多年来,他已帮助多个客户实施跨垂直行业的数据平台转型。他的核心专业领域包括技术战略、数据分析和数据科学。业余时间,他喜欢做运动、看电视节目和打手鼓。
Sriharsh Adari 是 Amazon Web Services(AWS)的高级解决方案架构师,他帮助客户从业务成果向后工作,以便在 AWS 上开发创新性解决方案。多年来,他已帮助多个客户实施跨垂直行业的数据平台转型。他的核心专业领域包括技术战略、数据分析和数据科学。业余时间,他喜欢做运动、看电视节目和打手鼓。
 Rahul Sonawane 是 AWS 的首席分析解决方案架构师,他的专长领域是人工智能/机器学习和分析。
Rahul Sonawane 是 AWS 的首席分析解决方案架构师,他的专长领域是人工智能/机器学习和分析。
 Amogh Gaikwad 是 Amazon Web Services 的解决方案开发人员。他帮助全球客户构建和部署人工智能/机器学习解决方案。他的工作主要集中在计算机视觉和 NLP 使用案例上,并帮助客户优化其人工智能/机器学习工作负载以实现可持续性。Amogh 获得了计算机科学硕士学位,专注于机器学习。
Amogh Gaikwad 是 Amazon Web Services 的解决方案开发人员。他帮助全球客户构建和部署人工智能/机器学习解决方案。他的工作主要集中在计算机视觉和 NLP 使用案例上,并帮助客户优化其人工智能/机器学习工作负载以实现可持续性。Amogh 获得了计算机科学硕士学位,专注于机器学习。