亚马逊AWS官方博客
使用 ElastiCache 和 MemoryDB 解锁 JSON 工作负载
应用程序开发人员喜欢 Redis,因为它拥有庞大且充满活力的开源社区,提供超快的内存性能,并且具有对开发人员友好但功能强大的 API,可为多种数据结构提供原生支持。这些特性使 Redis 非常适合用于构建和运行高性能、可扩展的 Web 应用程序。
在 AWS,我们提供两种基于 Redis 的服务完全托管服务:Amazon ElastiCache for Redis(用于缓存和临时存储数据)和 Amazon MemoryDB for Redis(用作需要更高级别数据持久性的应用程序的内存主数据库)。我们的客户使用这些服务来提高各种用例的性能,从移动支付到游戏排行榜、物联网 (IoT) 分析、乘车共享和实时广告投放。他们之所以选择我们,是因为我们一如既往的卓越运营稳定性和超高性价比,例如增强 IO、多流 TCP 和数据分层。
今天,我们很高兴地宣布,通过在 ElastiCache 和 MemoryDB 中提供对 JavaScript 对象表示法 (JSON) 的原生支持,我们将帮助 Redis 应用程序开发人员释放更大的力量。JSON 是一种几乎无处不在的数据编码和交换方式,现在在 ElastiCache 和 MemoryDB 中存储和访问 JSON 文档变得更加简单。此次发布简化了我们专门构建的文档数据库 Amazon DocumentDB(兼容 MongoDB)的 ElastiCache 缓存,以及在 MemoryDB 中使用持久 JSON。所有 ElastiCache 和 MemoryDB 区域均提供 JSON 支持,无需额外付费。要开始使用,只需使用 Redis 6.2 或更高版本创建一个新集群,即可获得新的 JSON 数据类型和相关命令。
本文的其余部分将介绍我们的 JSON 支持如何在技术层面上发挥作用,并提供一些示例,说明如何在 Redis 中编写 JSON 文档、在 Redis 中高效获取或设置 JSON 文档的某些部分,以及如何使用 Goessner 风格的 JSONPath 查询语言搜索 JSON 文档的内容。
ElastiCache 和 MemoryDB 中的 JSON
尽管 JSON 是用于交换结构化数据的标准序列化格式(RFC 8259、ECMA 404),但 ElastiCache 和 MemoryDB 中的 JSON 支持所提供的不仅仅是 JSON 编码数据的简单存储和检索。它通过提供强大的搜索和筛选功能,简化了存储复杂数据结构的应用程序的开发。如下一部分所示,许多应用程序对复杂数据结构的操作都可以在一个 JSON 命令中轻松自然地表达,而这在以前却需要大量开发时间以及多次昂贵的网络往返。这大大提高了开发人员的工作效率和系统改进,并降低了运营成本。
新的 Redis JSON 数据类型提供六种类型的值,四种基本类型(null、布尔、数字和字符串)和两种复合类型(对象和数组)。复合类型将字符串或密集整数键映射到值。但是,与其他 Redis 复合类型不同,JSON 复合类型包含任意组合的六种值类型中的任何一种,包括其他 JSON 复合类型,即递归。自由混合这些值类型的能力提供了一种表示几乎任何结构化数据的自然方式。
客户端应用程序使用序列化格式与服务进行通信。但是,数据在内部使用树状二进制格式存储,以实现高效的遍历和操作。树状格式允许对子树执行操作,就像对整个 JSON 键进行操作一样高效。在下面的描述中,术语“元素”通常用于表示任何 JSON 值,包括当值只是字符串或数字之类的基本类型时,或者是其他值的复合类型时。
JSON 数据类型已完全集成到 Redis 访问控制列表 (ACL) 功能中。所有 JSON 命令都正确执行任何键空间或命令限制或权限。就像现有的每数据类型类别(@string、@hash 等)一样,添加了一个新类别 @json,以简化对 JSON 命令和数据的访问管理。
大多数 JSON 命令不仅接受键,还接受一个或多个路径。路径是一个表达式,用于标识要对其执行命令的键中的 JSON 文档的一个或多个元素。路径的语法和语义与最初的 Goessner JSONPath 提案非常接近。有关 JSONPath 的更多信息,请参阅我们的文档。
Redis 和 JSON 的应用
为了说明 JSON 数据和 JSON 路径的强大功能,让我们来看一个数据结构(例如员工列表),看看如何对一些简单的操作进行编码。
我们将员工列表表示为一个对象数组,每个员工一个对象。我们的示例数据如下所示:
通过类似“ID”字段的属性获取雇员对象很简单:
选择属性没有理由不能有多个响应。此处查询返回位于 F2 楼的所有员工的员工记录:
但是,您不必获取整个员工记录,您可以选择像 ID 这样的字段来返回。此查询返回所有女性员工的 ID:
尽管 JSON 没有专用的时间戳基本类型,但您可以使用字符串来表示它们。此查询返回自 2020 年 1 月 1 日起雇用的所有员工:
查询筛选器不限于单个字段,您可以组合多个筛选器。此查询查找自 2020 年 1 月 1 日起雇用的所有男性员工:
这些示例仅简要介绍了 JSON 数据类型的可能性。
Redis 和 JSON 性能
选择上面的数据集是为了便于理解路径和筛选器表达式的功能示例。我们需要一个更大的数据集来了解 JSON 路径和筛选器的性能。用于对 JSON 性能进行基准测试的常用数据集之一位于文件 update-center.json 中(参见此处)。此文件的大小为 521KB。
以下每项性能测试都是通过在十 (10) 个客户端系统 (c5n.xlarge) 上运行 redis-benchmark 生成的,其中每个客户端系统使用十 (10) 个并行连接,共有 100 个并行连接。每个测试都是在 ElastiCache for Redis 的单节点 r6g 集群上运行的。对报告的每个实例大小重复一次测试。所有系统都在同一个可用区中。报告的结果是 100 个连接的每秒请求数 (rps) 之和的平均值。
作为基准,我们测试了获取整个 JSON 文档的性能。
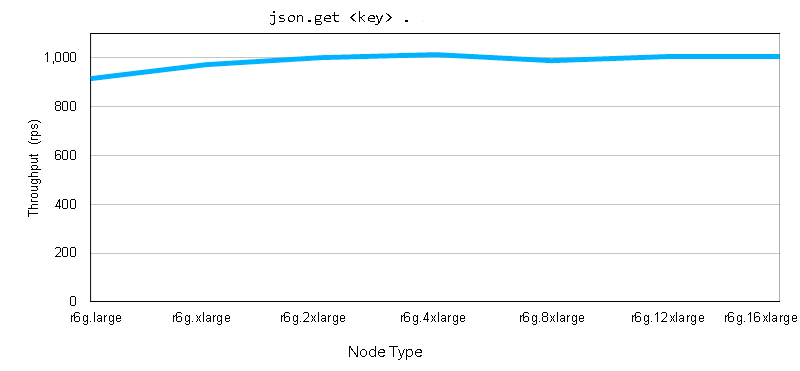
建立基线后,我们运行了一个测试,该测试提取了由路径标识的单个字符串。通常,选择特定元素的路径组件在 O(1) 时间内执行。这意味着性能与传输选定数据的网络成本直接相关,与 Redis 键中的 JSON 数据总量无关。这里选定的数据字符串很小,因此产生了相应的高吞吐量。

下一个测试基于最后一个示例。JSON 文档的单个字符串由路径标识并更新为新值。与读取情况一样,路径的成本是 O(1),与小字符串大小结合时会产生高吞吐量。

下一个示例测试使用筛选器时的查询性能。由于数据主要作为对象进行组织,因此必须使用递归搜索运算符 (..)。对于正在搜索的数据量,此运算符为 O(N)。在这里,plugin 对象包含 654 个成员,每个成员都有 15-20 个成员,这导致筛选器操作被应用超过 1 万次,从而对性能产生相应的影响。
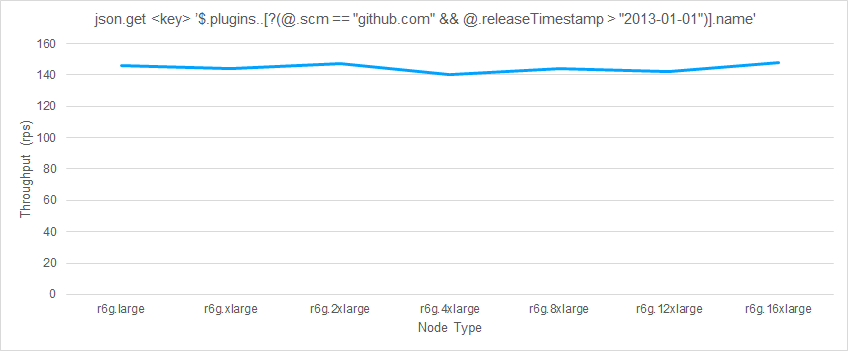
这是上一个示例的写入/设置性能。

在使用筛选器时,您可以通过修改 JSON 文档的组成来优化查询性能。具体来说,当将 plugin 对象转换为数组并使用数组搜索时,筛选器将仅应用于 654 个成员,而不是递归地应用于每个元素中的 15-20 个成员(即 1 万次)。这个简短的 Python 程序用于将 update-center.json 文件的 plugin 对象转换为数组。该程序的输出用于以下测试:
重复上述相同的查询(修改为使用数组搜索而不是递归搜索)会使吞吐量提高大约 25 倍。


选择这一系列特殊示例测试不仅是为了说明 JSON 路径和筛选器的强大功能,而且是为了说明对所使用数据的内容和结构的敏感性。由于您的整体性能取决于 JSON 数据的形状和正在执行的查询的性质,因此我们建议使用结构和内容尽可能模仿生产环境的数据集进行测试。
总结
在 ElastiCache 和 MemoryDB 中添加 JSON 支持简化了应用程序的开发并提高了性能和可靠性。使用新的 JSON 数据类型可以简化或消除使用其他内置 Redis 数据类型所需的复杂且容易出错的转换。简化或消除这些转换不仅可以加快应用程序开发,还可以提高应用程序的可靠性。您可以通过使用服务器端处理功能来消除需要多个数据库请求的情况,从而获得更高的性能。
要开始使用,请在 ElastiCache 控制台或 MemoryDB 控制台中创建一个新集群,然后查看我们文档(ElastiCache、MemoryDB)中的其他示例和命令参考。
关于作者
 Allen Samuels 是 Amazon Web Services 的首席工程师。他热衷于
Allen Samuels 是 Amazon Web Services 的首席工程师。他热衷于
分布式高性能系统。Allen 不是在环游世界、玩复式桥牌,就是在加利福尼亚州圣荷西的家中。
 Joe Travaglini 领导 Amazon ElastiCache 和 Amazon MemoryDB 的产品管理,过去 6 年一直在 AWS 担任产品职务。在加入 Amazon 之前,他曾在 Sqrrl 担任产品总监,Sqrrl 是一家网络安全分析初创公司,后被 AWS 收购。除了帮助客户充分利用云之外,Joe 还喜欢与家人共度时光、为波士顿运动队加油以及作为业余/家庭厨师练习厨艺。
Joe Travaglini 领导 Amazon ElastiCache 和 Amazon MemoryDB 的产品管理,过去 6 年一直在 AWS 担任产品职务。在加入 Amazon 之前,他曾在 Sqrrl 担任产品总监,Sqrrl 是一家网络安全分析初创公司,后被 AWS 收购。除了帮助客户充分利用云之外,Joe 还喜欢与家人共度时光、为波士顿运动队加油以及作为业余/家庭厨师练习厨艺。
 Joe Hu 是 AWS 内存数据库团队的一名软件开发工程师,他居住在波士顿。他热衷于构建大规模的分布式云服务。他职业生涯的大部分时间都涉及数据库内部、列存储、复制、备份和还原以及分布式查询处理领域。闲暇时,Joe 积极在当地俱乐部打乒乓球,偶尔还会参加地区锦标赛。
Joe Hu 是 AWS 内存数据库团队的一名软件开发工程师,他居住在波士顿。他热衷于构建大规模的分布式云服务。他职业生涯的大部分时间都涉及数据库内部、列存储、复制、备份和还原以及分布式查询处理领域。闲暇时,Joe 积极在当地俱乐部打乒乓球,偶尔还会参加地区锦标赛。