使用 Amazon Aurora 创建高可用性数据库集群




数据库

数据库管理员、开发人员


在本教程中,您将学习如何配置 Amazon Aurora 集群以创建高可用性数据库。高可用性数据库由跨多个可用区复制的计算节点组成,以提高读取可扩展性和故障转移保护。
Amazon Aurora 是一款关系型数据库服务,可提供兼容 MySQL 和 PostgreSQL 的版本,能够以极低的成本提供企业级数据库的性能和可用性。在大多数生产环境负载下,您都应当优先考虑高可用性的数据库。
默认情况下,Amazon Aurora 集群只有一个执行读/写操作的主计算实例。通过向集群添加一个或多个 Aurora 副本,您的数据库集群可以获得读取可扩展性和高可用性。如果集群中的主实例发生故障,Aurora 会自动将一个现有的副本提升为新的主实例。
一般而言,您应该在与主实例不同的可用区内创建 Aurora 副本。这样,在主可用区出现基础设施故障时,您的数据库可以快速切换至另一个可用区的副本上。
在存储层,Aurora 始终通过在三个可用区内以六种方式复制数据来保护您的数据。但是,如果未将 Aurora 副本添加到集群,当检测到故障时,您必须等待 Aurora 为您创建新的替代主实例,这可能需要更长时间。
本教程将使用与 MySQL 兼容的 Amazon Aurora 版本,但对于 PostgreSQL 版本,您可以遵循类似的流程。您将通过 Amazon RDS 管理控制台创建 Aurora 集群,添加 Aurora 副本,进行故障转移测试,然后终止教程环境。
本教程不适用于免费套餐,只要您按照教程中的步骤进行操作并在本教程结束时终止资源,所需费用将不超过 1 美元。
步骤 1 – 注册 AWS 账户
- 要按照本教程进行操作,您需要一个 AWS 账户。点击 Sign up for AWS(注册 AWS 账户)。
- 已经有账户?登录您的账户
步骤 2 – 进入 Amazon RDS 控制台
Amazon Aurora 是一款专为云环境打造的关系型数据库,与 MySQL 和 PostgreSQL 兼容。该数据库是 Amazon Relational Database Service (Amazon RDS) 的引擎。在此步骤中,您将进入 Amazon RDS 控制台。
打开 AWS 管理控制台,使本分步指南保持打开状态,以便一边操作一边参照本教程。页面加载后,输入您的用户名和密码即可开始使用。选择 Services(服务)> RDS 进入 RDS 管理控制台。

步骤 3 – 创建 Amazon Aurora 集群
在此步骤中,您将创建一个由 Aurora 数据库实例组成的 Amazon Aurora 集群。
a. 在 Amazon RDS 控制台的右上角,选择要在其中创建数据库实例的 Region(区域),然后点击 Create database(创建数据库)。

b. 在选择引擎页面上,点击 Standard Create(标准创建)。对于 Engine type(引擎类型),选择 Amazon Aurora。然后选择所需的 Edition(版本)。


d. 接下来配置数据库。对于容量类型和数据库引擎版本,保留默认设置。在 DB instance class(数据库实例类)中,需要选择数据库实例的计算和内存容量。Amazon Aurora 根据实例类型按小时收费,在本教程中,请选择 db.t2.small(1 vCPU、2 GiB RAM)以保持较低的成本。
在 Multi-AZ deployment(多可用区部署)下,选择 No(否)。虽然 Amazon Aurora 默认提供多可用区部署,但本教程将指导您如何在您选择的可用区内创建副本。

e. Amazon RDS 提供多种高级配置选项。在本教程中,只需禁用 Delete Protection(删除保护)选项并保留其余的默认配置即可。最后,点击 Create database(创建数据库)。数据库实例创建完成所需的时间取决于数据库实例类型,有时可能需要几分钟时间。

f. 新建的 Aurora DB 实例会显示在 RDS 控制台的 Databases(数据库)列表中。在数据库实例准备就绪且状态变为 Available(可用)之前,会一直处于 Creating(正在创建)状态。如果状态在几分钟后仍没有变化,请刷新页面。
步骤 4 – 创建 Aurora 副本以实现高可用性
默认情况下,每个 Amazon Aurora 实例都具有强大的数据保护功能。在 AWS 区域内的不同可用区中添加读取副本,可提高计算可用性。单个区域内的数据库集群支持在不同可用区中创建最多 15 个 Aurora 副本。
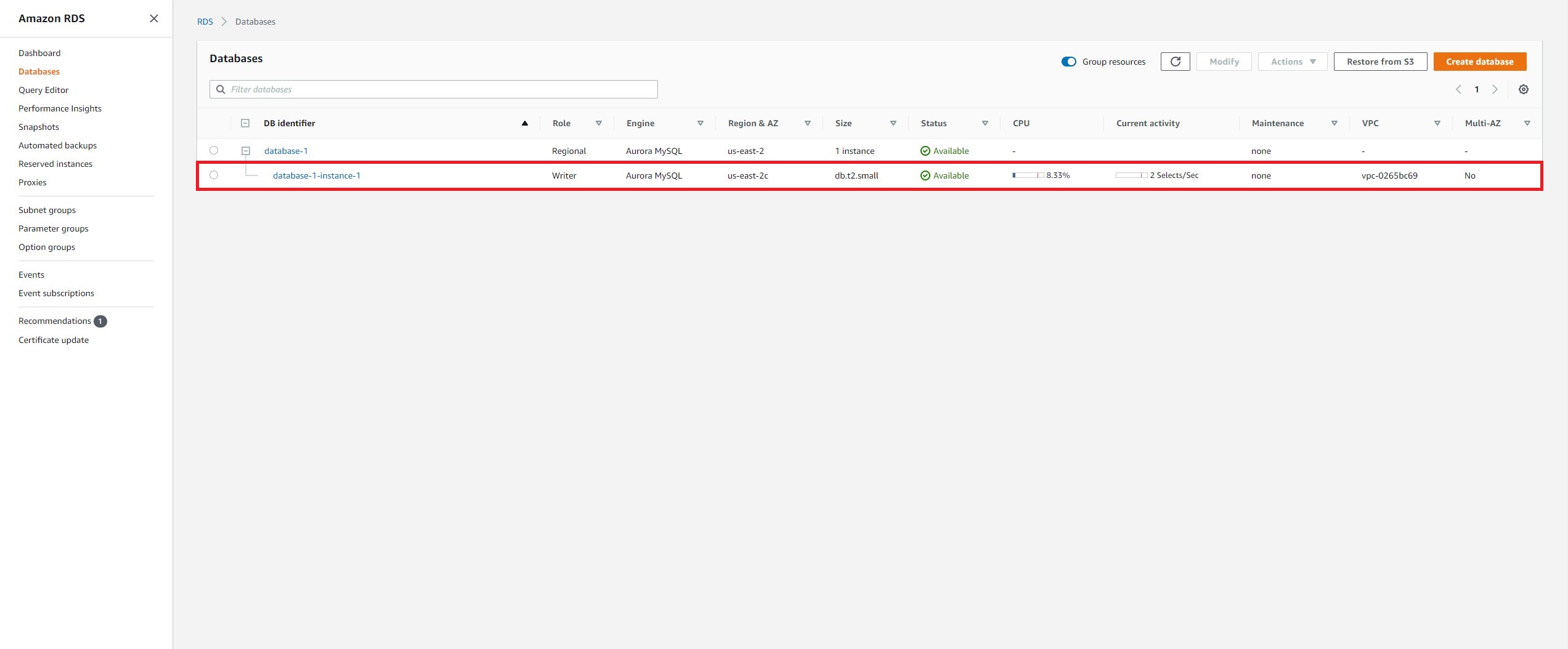
a. 在 Amazon RDS 控制台中,Aurora 集群中的主(写入器)实例会显示在 Databases(数据库)中。选择实例名称,并记下 Networking(网络)下的可用区。


c. 选择一个不同于主数据库实例的 Availability zone(可用区)。对于 Instance specifications(实例规格),选择一个与主实例相似的实例类型(在本例中,选择 db.t2.small),这样在发生故障转移时,数据库性能将不会受到影响。在 Settings(设置)下,为 Aurora 只读副本数据库实例输入一个唯一的名称。
选择 Add reader(添加读取器)。

d. 在数据库列表中,可以看到正在创建角色为 Reader(读取器)的新副本。向右滚动,直到看到 Multi-AZ(多可用区)属性,可以发现 2 Zones(2 个区),这表明集群分布在两个可用区(在计算层)。
您已经在计算层成功实现了高可用性。接下来,我们将进行数据库故障转移测试。

步骤 5 – 设置数据库集群用于测试故障转移
要提升高可用性,可以使用 Aurora 副本作为故障转移目标。如果主实例发生故障,一个 Aurora 副本会被提升为新的主实例。副本既可用于提高读取的可扩展性,也可用于提升可用性。在此步骤中,您将设置 Aurora 副本用于故障转移的优先级顺序。
a. 点击读取器数据库实例旁边的单选按钮,然后点击 Modify(修改)。

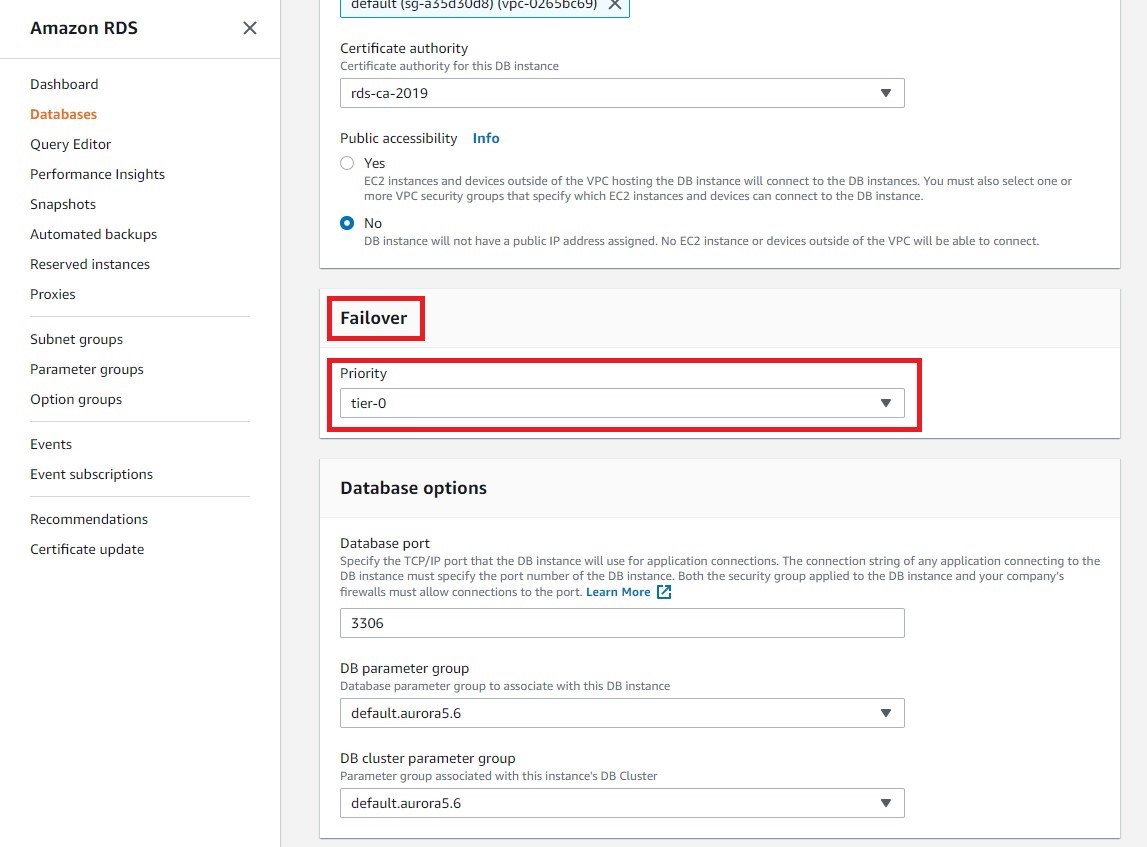
b. 在执行故障转移时,Amazon RDS 会将具有最高优先级(从第 0 层开始)的副本提升为新的主实例。由于我们目前只有一个副本,这里我们将该副本设置为最高优先级即可。在 Failover(故障转移)下,选择 Tier-0。
如果同一优先级层中的两个或多个副本的优先级存在冲突,Amazon RDS 将提升与主实例大小相同的副本。
点击 Continue(继续),然后点击 Modify DB instance(修改数据库实例)。
步骤 6 – 测试数据库故障转移
a. 选中目标实例旁的单选按钮。然后选择 Actions(操作)> Failover(故障转移)。此操作会将副本升级为新的主(或写入器)实例,而旧的主(或写入器)实例将成为新的读取副本。


c. 故障转移完成所需的时间取决于故障转移时的数据库活动量,但通常不超过 60 秒。您可以通过 Log & events(日志和事件)> Recent events(最近事件)监控故障转移过程。
如果是通过端点连接数据库,故障转移对应用程序来说是无感知的。因为集群和读取器端点在连接中是作为数据库 DNS 提供给应用程序,所以实例连接将不受影响,并在故障转移完成后自动切换至新的数据库实例。

步骤 7 – 终止资源
在此步骤中,您将终止 Aurora 数据库集群环境。
重要说明:终止当前未使用的资源可降低成本,这是一种最佳做法。
a. 选择要终止的 Amazon Aurora 集群名称,并单击集群名称以显示所有集群实例的列表。点击读取器角色数据库实例旁的单选按钮,然后选择 Actions (操作)> Delete(删除)。

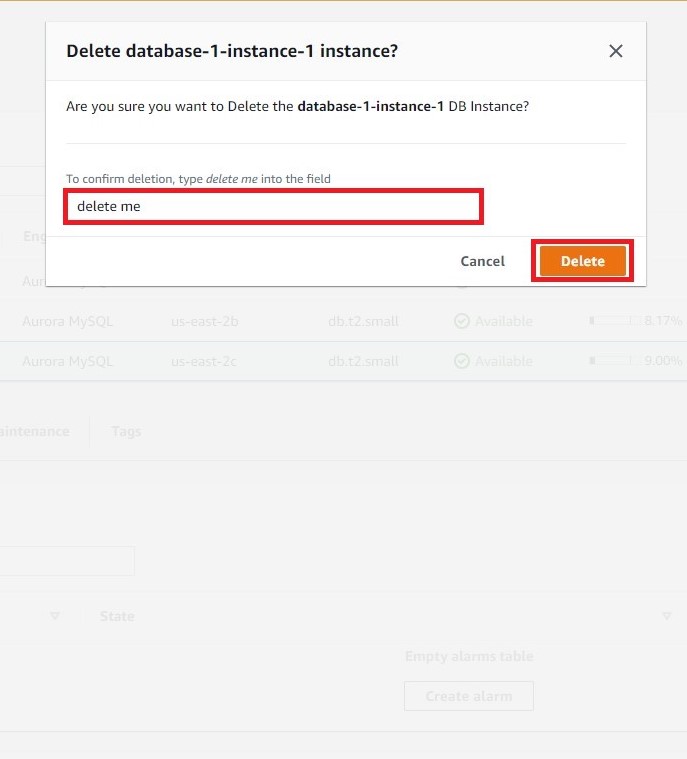
c. 对写入器数据库实例重复步骤 7a-b。对于本教程,请勿选择 Create final snapshot(创建最终快照),而是选择 acknowledgement(确认)一项。输入 delete me,然后点击 Delete(删除)。此步骤将删除 Aurora 集群,包括存储和所有自动数据库备份。








