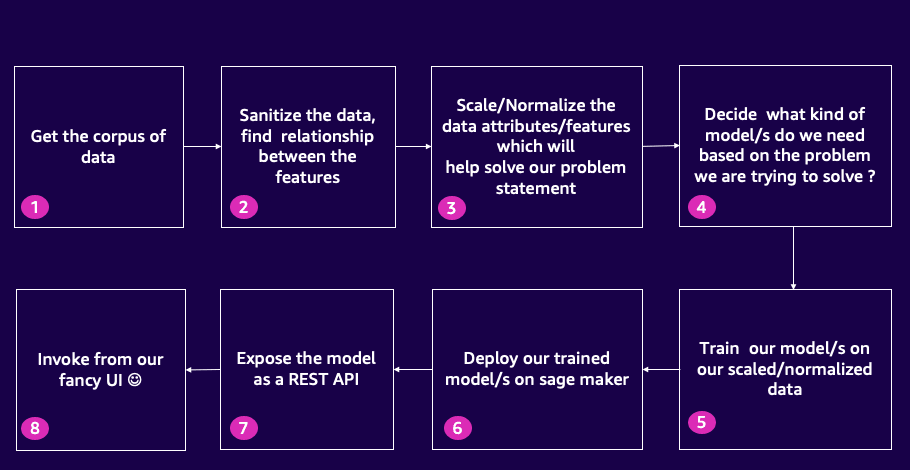
利用亚马逊云科技为电影流媒体平台克隆创建推荐引擎




可使用免费套餐资源


本教程中使用的示例代码来自 GitHub

开发者在开发过程会意识到,仅仅构建机器学习模型是不够的。他们需要将模型集成到全栈应用程序中才能创造实际价值。但在某些项目中,如推荐引擎,构建和集成过程将很复杂。例如,下面的实验中我们需要构建一个名为 MyFLix 的流媒体平台,该平台需要为用户提供个性化的内容推荐。为了演示如何将机器学习模型集成到全栈应用程序中,我们将构建一个推荐引擎,并将其集成到 MyFlix 中。让我们开始吧!
学习内容
- 如何使用 jupyter 笔记本和 python 代码来清洁原始数据和实现数据可视化。
- 如何查找数据集内各种特征之间的关系,并将相关特征转换为数值特征。
- 如何缩放原始数据中的数值特征,使所有特征处于相同尺度,方便比较。
- 如何在 SageMaker 上构建、训练和部署自定义的原生机器学习模型。
- 如何使用基于开源 Chalice 框架的 Amazon API Gateway 和 Amazon Lambda 通过 REST API 公开已部署的模型。
- 如何将 REST API 与前端用户界面 (UI) 集成(此处所说的 UI 是指 MyFlix 流媒体平台克隆。您也可以根据在本教程的知识介绍通过机器学习模型构建自己的全栈应用程序)。
构建内容
在试验中,我们将为 MyFlix 流媒体平台克隆构建推荐引擎。首先,我们从原始电影数据中分析、清洁和选择特征值,为流媒体平台克隆创建强大的推荐引擎奠定基础。接下来,我们会构建一个自定义缩放模型,用于准确比较已整理的电影数据特征。然后,我们将利用这些缩放值来训练和构建用于电影推荐的 k 均值聚类算法。此外,我们还将学习如何在 SageMaker 上部署模型,使效率最大化。最后,我们将为用于实时预测的机器学习模型构建前端 API。我们将学习如何用开源 Chalice 框架(https://github.com/aws/chalice)作为一键式构建和部署工具来构建 API。您甚至可以通过 Chalice 将 API 公开为 Lambda,并轻松地创建开箱即用的 API Gateway 端点!最后,我们将学习如何将机器学习模型与前端结合起来。您可以根据本教程将自己的全栈应用程序与 API 和机器学习模型集成。
构建内容:可视化呈现
使用示例代码快速入门
1. 我们将使用 Amazon CLI 和 CloudFormation 嵌套堆栈来创建本教程试验所需的基础设施资源。我们可以下载此 CloudFormation 模板,使用这个模板创建所需资源。在 Amazon CLI 执行命令来部署 CloudFormation 嵌套堆栈。下载 CloudFormation 模板后,目录结构如下所示:
-rw-r--r-- 1 XXXXX XXXX 6582 Jul 5 22:07 customresource-stack.yaml
-rw-r--r-- 1 XXXXX XXXX 269 Jul 7 21:23 glue-stack.yaml
-rw-r--r-- 1 XXXXX XXXX 3091 Jul 4 02:24 instance-stack.yaml
-rw-r--r-- 1 XXXXX XXXX 2550 Jul 7 13:11 main-stack.yaml
-rw-r--r-- 1 XXXXX XXXX 2141 Jul 5 14:45 sagemaker-stack.yaml
-rw-r--r-- 1 XXXXX XXXX 6877 Jul 7 00:57 vpc-stack.yaml2. 以下命令用于将 CloudFormation 模板打包到 main-stack.yaml 中,并将打包后的模板文件 packaged.yaml 存入 us-east-1 区域中名为 placeholder-cloudformation-s3-bucket-to-store-infrastructure-template 的 S3 存储桶。实际操作时,请在账户中创建自己的 S3 存储桶,并将示例命令中的 placeholder-cloudformation-s3-bucket-to-store-infrastructure-template 替换为您的存储桶名称。
aws cloudformation package --template-file main-stack.yaml --output-template packaged.yaml --s3-bucket placeholder-cloudformation-s3-bucket-to-store-infrastructure-template --region us-east-13. 接下来执行 aws cloudformation deploy 命令,部署 package.yaml 中定义的 CloudFormation 模板。您可以在命令中包含 --parameter-overrides 选项并添加参数键值对,替换 main-stack.yaml 中 S3BucketName、SageMakerDomainName、GitHubRepo、VpcStackName、VpcRegion、ImageId 和 KeyName 的默认值。示例:
aws cloudformation deploy \
--stack-name buildonaws \
--template-file <Absolute path>/packaged.yaml \
--parameter-overrides S3BucketName=myfamousbucket \
SageMakerDomainName=buildonaws \
GitHubRepo=https://github.com/build-on-aws/recommendation-engine-full-stack \
VpcStackName=MyBuildOnAWSVPC \
VpcRegion=us-east-1 \
ImageId=ami-06ca3ca175f37dd66 \
KeyName=my-key \
--capabilities CAPABILITY_NAMED_IAM --region us-east-14. 将示例值(myfamousbucket、buildonaws、MyBuildOnAWSVPC、us-east-1、ami-06ca3ca175f37dd66、my-key)替换为所需的默认值。其中,ami-06ca3ca175f37dd66 是指一个可用于 us-east-1 区域 EC2 实例的 Amazon Linux 2023 机器镜像 (AMI)。请根据要部署此堆栈的区域,选择 Amazon Linux 2023 对应的 Amazon 机器镜像,用于创建一个 EC2 实例。此 EC2 实例用于将 Jupyter 笔记本、预训练模型和原始数据填充到 S3 存储桶。填充这些数据到 S3 存储桶后,将关闭该 EC2 实例。
5. 接下来,登录亚马逊云科技管理控制台,完成设置,并验证所需的基础设施资源是否创建成功。查看创建的所有基础设施资源。然后,进入已创建的 S3 存储桶(我新创建的 S3 存储桶名为 myfamousbucket)。
6. 查看 S3 存储桶中的文件夹结构。文件夹结构应该如下所示:
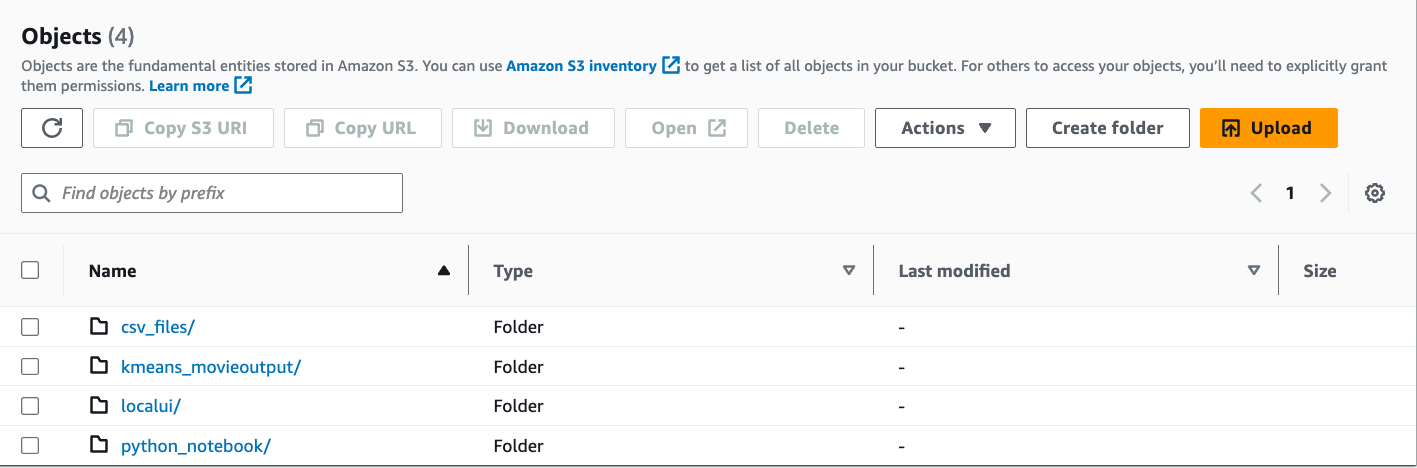
7. 访问 SageMaker Studio 的集成开发环境 URL。您在第 3 步部署的名为 buildonaws 的 CloudFormation 堆栈的 Outputs 中获得该 URL。CloudFormation 堆栈输出密钥的名称为 SageMakerDomainJupyterURLOutput。单击 URL 打开 SageMaker Studio。我们将使用 SageMaker Studio 分析原始电影数据、执行可视化,并为电影数据集生成正确的特征集。
8. 进入 SageMaker Studio 用户界面后,
- 选择 File(文件)> New Terminal(新终端)
- 在终端上执行以下命令,从 S3 存储桶下载 python 笔记本。注意:请务必将命令中的 myfamousbucket S3 存储桶名称替换为您的 S3 存储桶名称。
aws s3 cp s3://myfamousbucket/python_notebook/AWSWomenInEngineering2023_V3.ipynb .9. 双击 Jupyter Notebook,启动内核。此过程大约需要 5 分钟。Jupyter 笔记本的开头有一个目录,各单元格也有正在执行的步骤的详细说明。此实验中,我们会将笔记本中的一些重要单元格单独列出,以便查看 Jupyter 笔记本中的设置概览。
- 数据准备过程中,我们先从 S3 下载数据集,然后构建一个 Pandas 数据帧,用于分析单元格 #5 中的数据。Pandas 数据帧中的初始数据结构如下所示:

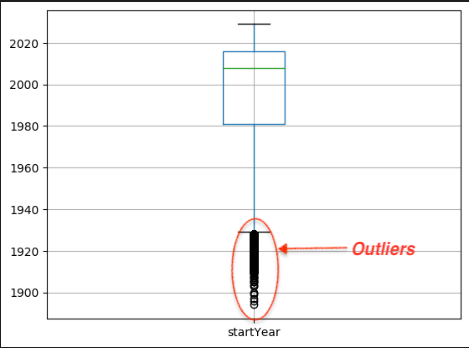
- 为了确定电影发行年份的分布情况,我们在单元格 #10 中绘制了一个箱形图;为了确定发行年份的四分位距,我们在单元格 #11 中绘制了一个箱形图。四分位距(IQR)是用于数据准备和分析的统计度量,帮助我们了解数据分布。这有助于我们识别和分析数据集中数据的可变性。IQR 可用于识别数据集中的异常值。异常值是指明显超出大多数其他数据点范围的数据点。您可以计算 IQR 并指定阈值,从而识别观测值中的潜在异常值。在单元格 #11 中,您会看到 IQR 和异常值的可视化呈现,这些异常值在后续单元格中会被过滤掉:
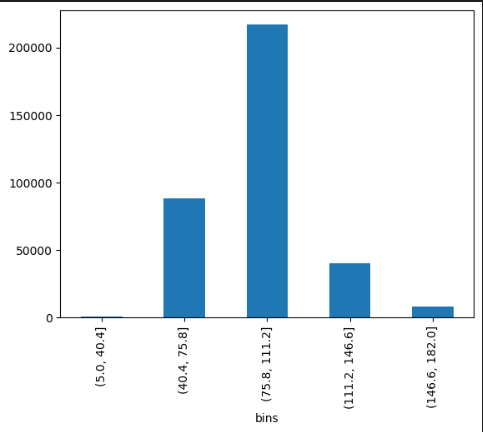
- 接下来,在单元格 #14 中,您会看到 Binning(数据分箱)可视化技术的应用。应用分箱技术,为不同的时长范围创建特定的箱或类别。例如,可以将时长超过 3 小时的电影识别为异常值。这类电影不属于大多数数据集的范围,而属于极值。在确定异常值后,从数据集中删除时长超过 3 小时的电影。这样一来,我们就消除了这些极值对分析的影响,并创建了一个具有更窄时长范围的数据集。这样的数据集更具代表性。去除异常值后,电影时长的分布更加对称、更符合钟形曲线。
- 在单元格 #16 中,数据集中的 genres(流派)列将转换为独热编码列。此过程包括按逗号拆分流派、创建唯一的流派标签,以及在数据集中根据流派标签添加列。随后,根据每部电影所属流派,在新增的流派列中赋值 1 或 0。独热编码列转换使我们能根据电影是否属于某一流派轻松进行分析和建模。完成独热编码后,Pandas 数据帧如下所示:

- 完成其他过滤、清理以及删除不必要的特征之后,在单元格 #31 中,我们看到最终的数值特征列表。可以使用这些特征构建机器学习模型。

10. 原始电影数据集的最终特征显示 startYear、runtimeMinutes、averageRating 和 numVotes 等特征的量级不同。在构建电影推荐算法时,必须将这些特征缩放到相同的范围,以确保公平的比较,防止某一特征严重影响算法计算。我们可以使用 scikit-learn 库中的自定义缩放模型来对特征进行规范化,并使它们缩放到相似的尺度。这种规范化有助于避免偏差,并保证所有特征对推荐计算的同等影响,从而产生更准确、更可靠的电影推荐。在单元格 #33 和单元格 #34 中,我们借助 sckitlearn 库构建了自定义缩放算法,并对 model.joblib 进行序列化并将其保存到本地。此外,我们还将 model.joblib 的副本保存到 S3 存储桶中,供以后使用。最后,在单元格 #36 中,您可以观察到,数值特征经缩放后尺度是相同的:

12 接下来,在单元格 #38 中,使用了上一步中生成的模型确定电影推荐系统的适当聚类簇数量。此代码片段旨在创建一个可视化 elbow graph(肘形图),帮助我们根据 distortion(失真值)指标确定最佳聚类簇数量:
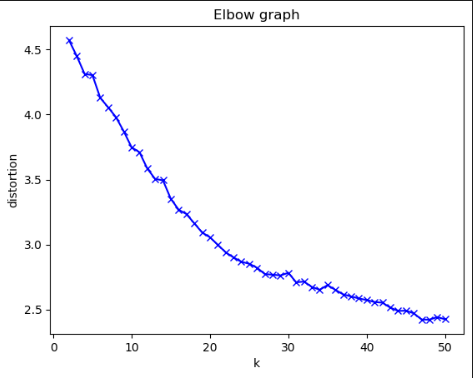
13. 接下来,在单元格 #40 中,使用最佳聚类簇数量(在本例中,我根据上面的图表选择了 26 个),在 SageMaker 上部署 Kmeans 模型,用于实时推算。
14. 在单元格 #43 和 #44 中,添加了聚类编号,增强了原始电影数据集。下图展示的是有聚类编号的增强数据集。我们之后构建的 REST API 将使用此增强数据集来检索给定聚类编号的电影集合:

15. 最后,处理其他几个单元格,将这些增强后的信息存储在 Glue 数据库中。增强后的信息以 parquet 文件格式存储在 S3 存储桶的 clusteredfinaldata 文件夹中。此步骤在单元格 #51 中完成。
16. 目前,尽管 KMeans 模型已部署为 SageMaker 端点,但自定义缩放模型仍仅适用于本地 SageMaker Studio 环境的一个序列化文件 model.joblib。下一步,在 SageMaker 的原生 SKLearn 容器中部署自定义缩放模型。您可以将 SageMaker 的原生容器作为在 SageMaker 上实施自建模型(BYOM)的一种方法。以下是在 SageMaker 的 SKLearn 容器上部署自定义缩放模型的过程图示。方法是创建包含 model.joblib 和 inference.py 文件的压缩 tar.gz 文件,提供这些构件来创建 SageMaker 模型端点和端点配置:

17. 有很多自动执行部署的方法,但我们将使用 GitHub 存储库中的 SageMaker 迁移工具包来简化此过程。继续下一步。
将自定义缩放模型部署为 SageMaker 端点
正如上一步所示,我们的自定义缩放模型仍然只在本地的 SageMaker Studio 环境中可用。下面,我们将在 SageMaker 的原生 SKLearn 容器中部署该自定义缩放模型。在 SageMaker 上实施自建模型(BYOM)的方法之一是利用 SageMaker 的原生容器。因此,我们将利用 SageMaker 迁移工具包,并将自定义缩放模型部署为 SageMaker 端点。
1. 请使用已部署 CloudFormation 模板的亚马逊云科技账户登录控制台,并选择您部署堆栈的 亚马逊云科技区域。从 CloudFormation Outputs(CloudFormation 输出)选项卡中复制名为 SageMakerUserProfileRoleOutput 的 SageMaker IAM 角色的 ARN。我们将使用该角色来设置 SageMaker 迁移工具包,因为该角色具有创建和部署 SageMaker 模型、端点配置和端点所需的权限。IAM 角色的 ARN 格式如下:arn:aws:iam::XXXXXXXXX:role/SageMakerUserProfileRole-BuildOnAWS。
2. 现在,让我们通过亚马逊云科技控制台打开 AWS Cloud9,部署自定义缩放模型 model.joblib。Cloud9 是亚马逊云科技提供的基于浏览器的集成开发环境。使用 Cloud9,代码开发将变得非常简单。登录 AWS Cloud9 环境后,选择 Window(窗口)-> New Terminal(新终端)打开一个新终端。然后,执行以下命令,使用主分支克隆存储库:
git clone https://github.com/build-on-aws/recommendation-engine-full-stack
sudo yum install git-lfs
cd recommendation-engine-full-stack
git lfs fetch origin main
git lfs pull origin3. 在克隆 github 存储库后,Cloud9 集成开发环境如下所示:
4. 运行以下命令在 Cloud9 控制台中安装迁移工具包。安装迁移工具包后,我们便可以以 SageMaker 的原生 SKLearn 容器兼容的格式打包自定义缩放模型 model.joblib 和用于推理的 inference.py:
cd sagemaker-migration-toolkit
pip install wheel
python setup.py bdist_wheel
pip install dist/sagemaker_migration_toolkit-0.0.1-py3-none-any.whl5. 执行以下命令配置 SageMaker 迁移工具包。按照步骤指引操作,并输入 SageMaker IAM 角色 ARN。
sagemaker_migration-configure --module-name sagemaker_migration.configurecd testing/sklearn/
aws s3 cp s3://<S3 bucket from Cloudformation output where all data is stored>/model.joblib ./7. 我们分析一下 testing/sklearn 文件夹中的 inference.py 脚本。inference.py 文件中包含用于加载和反序列化 model.joblib 的 model_fn。input_fn 是我们已经修改过的方法,它用于接收 application/json 格式的内容,并将其转换为 Pandas 数据帧格式,然后再将数据发送到 predict_fn,后者将数据帧加载到自定义缩放模型中。数据规范化后,会通过 output_fn 以 JSON 字符串形式返回。包含 testing/sklearn 文件夹中 inference.py 文件里突出显示的函数。
8. 在 Cloud9 终端上执行以下命令。将 us-east-1 替换为您的堆栈所在区域。
export AWS_DEFAULT_REGION=us-east-19. 在 testing/sklearn 文件夹中,执行 python test.py,部署自定义缩放模型的 SageMaker 端点。
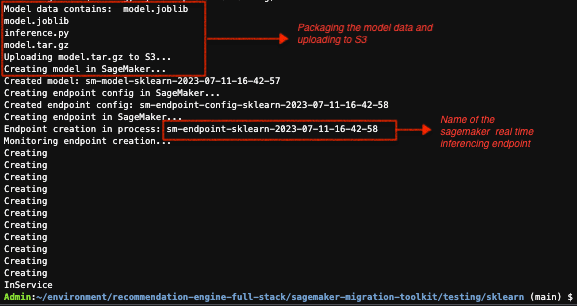
python test.py部署自定义缩放端点后,Cloud9 控制台上的输出如下所示:
10. (可选)部署后,测试自定义端点。复制 SageMaker 端点名称,粘贴到下面的命令中。执行该命令,替换 localtest.sh 文件中 SAGEMAKER-ENDPOINT 的值。
sed -i s@SAGEMAKER-ENDPOINT@sm-endpoint-sklearn-xxxx-xx-xx-xx-xx-xx@g localtest.sh11. 执行以下命令,然后检查响应内容是否来自 prediction_response.json 文件:
sh localtest.sh如果您发送如下所示的带有电影属性的请求:
aws sagemaker-runtime invoke-endpoint \
--endpoint-name ${ENDPOINT_NAME} \
--body '{"startYear":[2015], "runtimeMinutes":[150],"Thriller":[1],"Music":[0],"Documentary":[0],
"Film-Noir":[0],"War":[0],"History":[0],"Animation":[0],"Biography":[0],
"Horror":[0],"Adventure":[0],"Sport":[0],"Musical":[0],
"Mystery":[0],"Action":[0],"Comedy":[0],"Sci-Fi":[1],
"Crime":[0],"Romance":[0],"Fantasy":[0],"Western":[0],
"Drama":[0],"Family":[0],
"averageRating":[7],"numVotes":[50]}' \
--content-type 'application/json' 则您会收到 prediction_response.json 文件中的如下内容。这些值代表的是转换为数值并缩放到同一尺度的电影属性:
{"Output":"[[0.7641384601593018, 2.2621326446533203, 2.6349685192108154, -0.19743624329566956, -0.27217793464660645, -0.10682649910449982, -0.17017419636249542, -0.20378568768501282, -0.18412098288536072, -0.2402506023645401, -0.29970091581344604, -0.3280450105667114, -0.14215995371341705, -0.14177125692367554, -0.27615731954574585, -0.42369410395622253, -0.7180797457695007, 5.349470615386963, -0.43502309918403625, -0.46801629662513733, -0.22049188613891602, -0.1328728199005127, -1.1882809400558472, -0.21341808140277863, 0.5960079431533813, -0.24598699808120728]]"}12. 自定义缩放模型的部署完成。回到亚马逊云科技控制台,您可以在 SageMaker 控制台中看到自定义缩放模型和 K Means 聚类算法的 2 个实时推理端点已显示在端点列表中,如下所示:
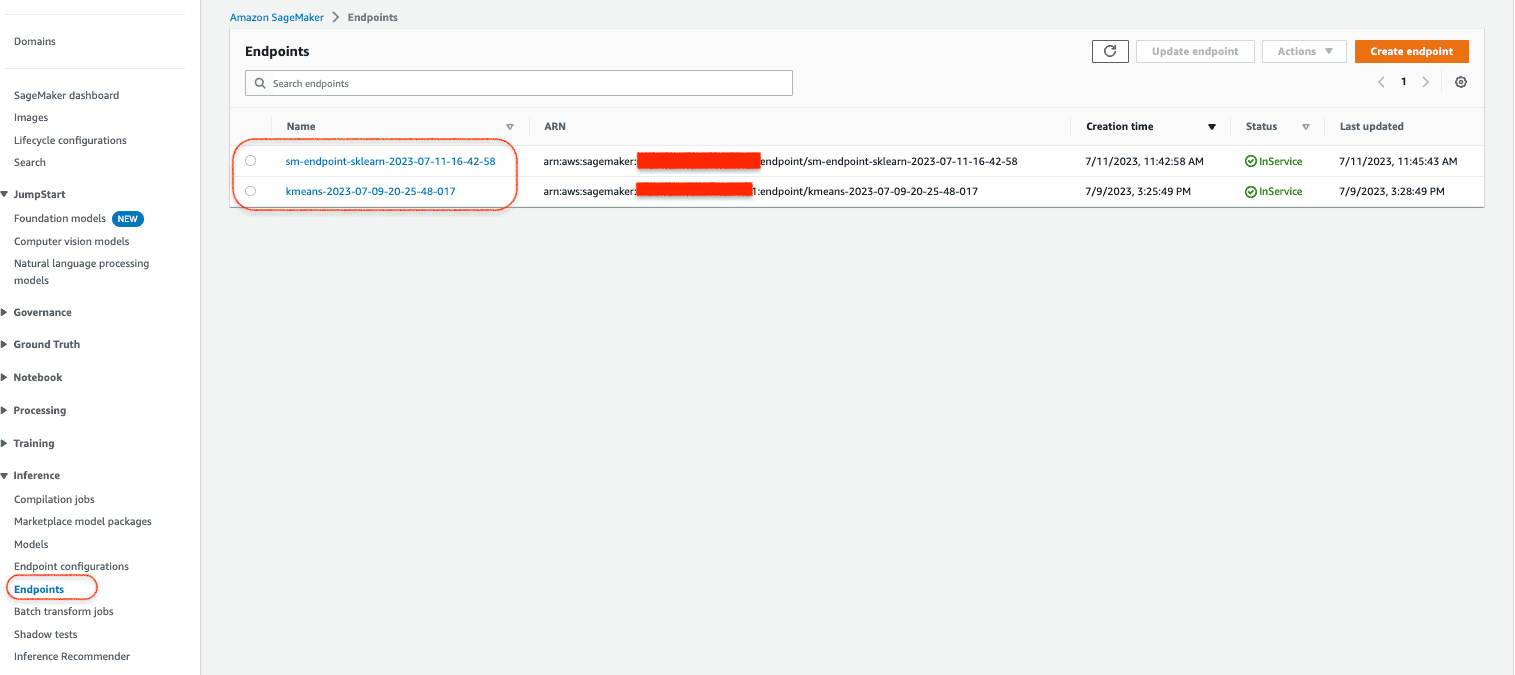
部署 SageMaker 模型端点前端的 REST API
1. 使用 Chalice 框架创建 API。Chalice 有助于轻松创建 Lambda 和 API Gateway。使用同一个 Cloud9 环境设置 Chalice、构建调用 SageMaker 模型端点的 REST API。我们将构建的第一个 REST API 是 Cluster REST API,用于调用自定义缩放 SageMaker 端点和 Kmeans 聚类端点,并返回用于返回电影列表的聚类编号。登录我们之前所用的 Cloud9 IDE。在 Cloud9 终端上执行以下命令,进入 Cloud9 环境的根目录:
cd ~/environment2. 单击齿轮图标查看 Cloud9 IDE 中的隐藏文件。然后勾选 Show Environment Root(显示环境根目录)和 Show Hidden Files(显示隐藏文件)。这样,在安装 Chalice 框架后,您就可以看到 .chalice 文件夹。Cloud9 控制台如下所示:
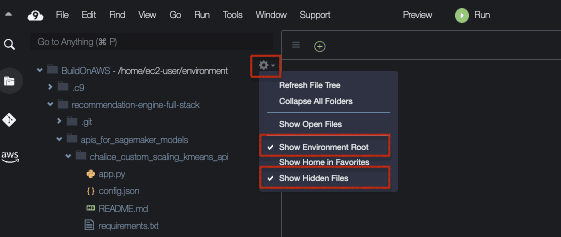
3. 运行一下命令安装 Chalice:
pip install chalice
chalice new-project sagemaker-apigateway-lambda-chalice4. 创建具有所需访问策略的角色 Cloud9_LambdaExecutionRole。此角色将作为 Lambda 执行角色添加到 .chalice 文件夹内的 config.json 中。添加角色后,config.json 应该如下所示。请将以下代码片段中的 iam_role_arn 替换为您的角色 ARN 值:
{
"version": "2.0",
"automatic_layer": true,
"manage_iam_role": false,
"iam_role_arn": "arn:aws:iam::XXXX:role/Cloud9_LambdaExecutionRole",
"app_name": "sagemaker-apigateway-lambda-chalice",
"stages": {
"dev": {
"api_gateway_stage": "api"
}
}
}5. 在 Cloud9 终端上执行以下命令。请将区域值替换您的实际区域代码:
export AWS_DEFAULT_REGION=us-east-16. 将 requirements.txt 和 app.py 文件从 recommendation-engine-full-stack/apis_for_sagemaker_models chalice_custom_scaling_kmeans_api 文件夹复制到 Chalice 项目 sagemaker-apigateway-lambda-chalice 的根目录。我们来介绍一下 app.py 文件。app.py 文件从前端接收电影属性的 JSON 请求,并调用部署在 SageMaker 上的自定义缩放模型和 kmeans 聚类模型的端点。示例设置如下:
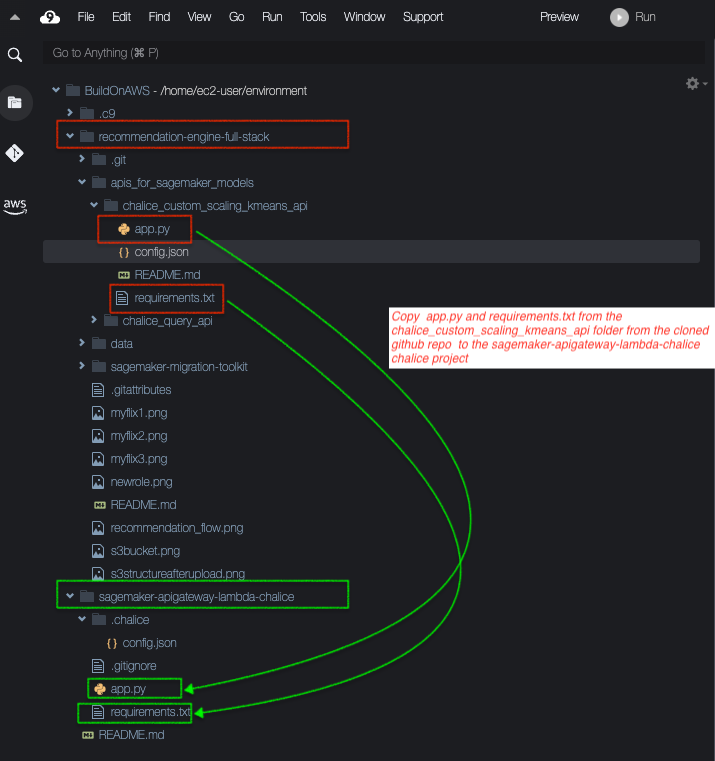
在 Chalice 项目 sagemaker-apigateway-lambda-chalice 里 app.py 代码的这一部分中,请将 SageMaker 端点名称、自定义缩放模型和 kmeans 模型都替换为实际值,如下所示:
.....
......
.....
res = sagemaker.invoke_endpoint(
EndpointName='sm-endpoint-sklearn-xxxx-xx-xx-xx-xx-xx',
Body=result,
ContentType='application/json',
Accept='application/json'
)
......
.....
.....
responsekmeans = sagemaker.invoke_endpoint(EndpointName="kmeans-xxxxxx", ContentType="text/csv", Body=payload)
.....
....7. 在 sagemaker-apigateway-lambda-chalice 文件夹根目录中执行一下命令:
chalice deploy8. 部署 Lambda 函数和 API Gateway REST API 端点后,您将在 Cloud9 控制台获得 REST API URL,其格式如 https://xxxxxxx.execute-api.region.amazonaws.com/api/。
此 REST API 将根据传递给它的电影属性返回聚类编号。我们需要在 UI 代码中替换此 REST API 端点。您可以在亚马逊云科技控制台查看 Lambda 函数和 Chalice 创建的 API Gateway REST API 端点。
9. 在 Cloud 9 终端中执行以下命令测试已部署的 API:
curl -X POST https://xxxxxxx.execute-api.us-east-2.amazonaws.com/api/ -H 'Content-Type: application/json' -d @- <<BODY
{
"startYear":"2015","runtimeMinutes":"100","Thriller":"1","Music":"0",
"Documentary":"0","Film-Noir":"0","War":"0","History":"0","Animation":"0",
"Biography":"0","Horror":"0","Adventure":"0","Sport":"0","News":"0","Musical":"0",
"Mystery":"0","Action":"0","Comedy":"0","Sci-Fi":"1","Crime":"0","Romance":"0",
"Fantasy":"0","Western":"0","Drama":"0","Family":"0","averageRating":"7","numVotes":"50"
}
BODY成功执行上述请求后,您将获得一个聚类编号。Cloud9 终端收到响应如下所示:

10. 此步骤是可选操作。如果计算机上已安装 Postman,则可以使用 Postman 进行测试。Postman POST payload 示例如下:
{"startYear":"2015","runtimeMinutes":"100","Thriller":"1","Music":"0","Documentary":"0","Film-Noir":"0","War":"0","History":"0","Animation":"0","Biography":"0","Horror":"0","Adventure":"1","Sport":"0","News":"0","Musical":"0","Mystery":"0","Action":"1","Comedy":"0","Sci-Fi":"1","Crime":"1","Romance":"0","Fantasy":"0","Western":"0","Drama":"0","Family":"0","averageRating":"7","numVotes":"50"
}11. 接下来,我们为第二个 REST API 创建第二个 Chalice 项目。该 API 将聚类编号作为输入,然后从保存在 Glue 数据库中的增强数据中返回属于该聚类的电影列表。在 Cloud 9 终端上执行 cd ~/environment 命令,进入 Cloud9 环境的根目录。然后,执行以下命令创建一个新的 Chalice 项目:
chalice new-project query-athena-boto3- 将克隆的 GitHub 存储库文件夹 recommendation-engine-full-stack/apis_for_sagemaker_models/chalice_query_api 中的 requirements.txt 和 app.py 添加到 Chalice 项目 query-athena-boto3 的根目录下。
- 将 iam_role_arn 替换为实际值,更新此项目的 config.json 中的角色。config.json 内容应如下所示:
{
"version": "2.0",
"app_name": "query-athena-boto3",
"iam_role_arn": "arn:aws:iam::xxxxxxxx:role/Cloud9_LambdaExecutionRole",
"manage_iam_role": false,
"stages": {
"dev": {
"api_gateway_stage": "api"
}
}
}- 执行以下命令:
cd query-athena-boto3/
sed -i s@BUCKET_NAME@<Replace with your bucket name>@g app.py
chalice deploy12. 接下来,执行 curl 命令,测试已部署的 API Gateway REST API 端点。将 https://yyyyyyy.execute-api.us-east-2.amazonaws.com/api/ 替换为实际部署的 URL。示例中,聚类编号是 1。
curl -X POST https://yyyyyyy.execute-api.us-east-2.amazonaws.com/api/ -H 'Content-Type: application/json' -d '{"cluster":"1.0"}' 13. 接下来,执行最后一步,将这 2 个 API Gateway REST API 端点集成到 UI 代码中。
将 API 与 UI 集成
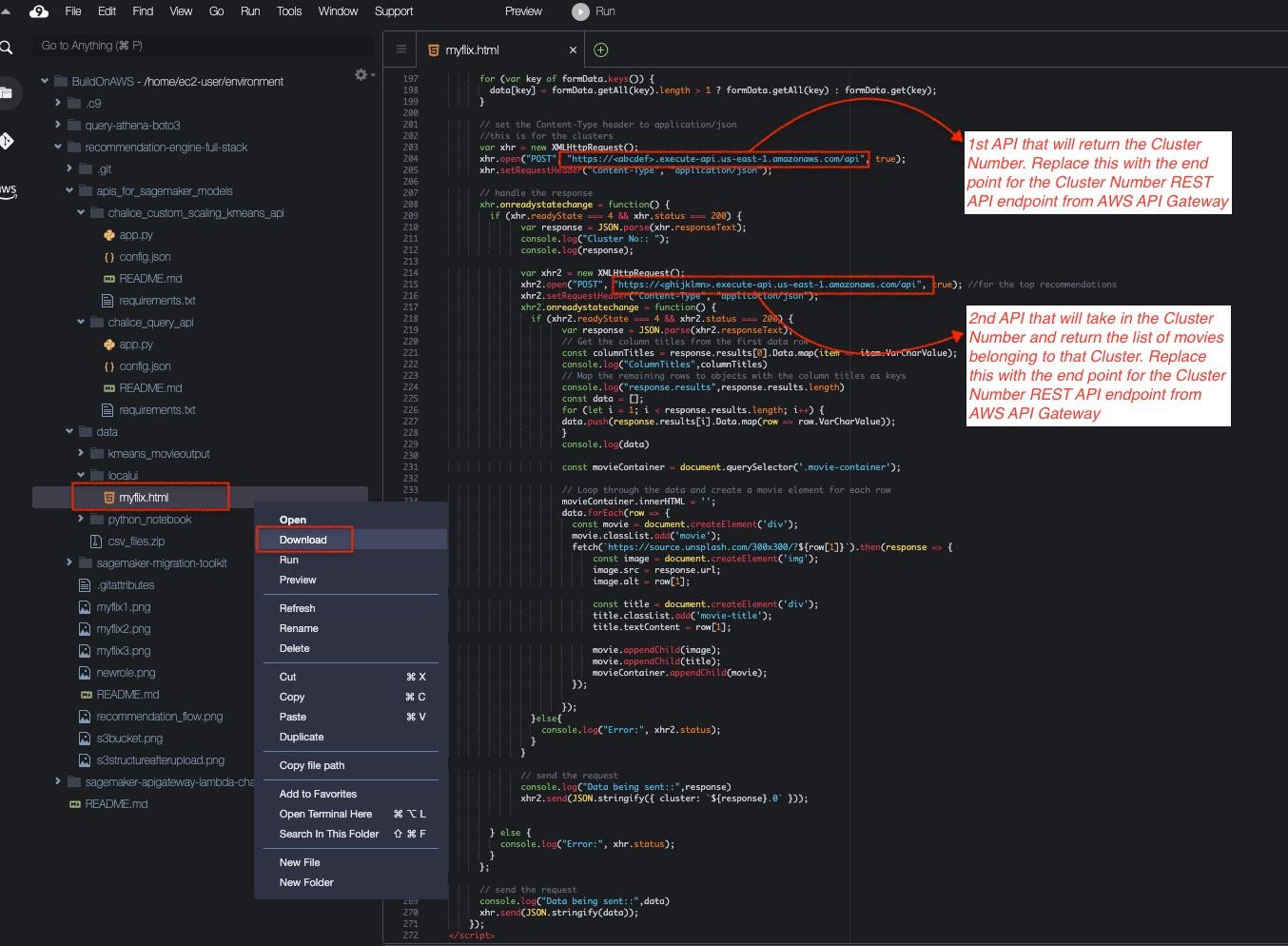
1. 从 Cloud9 控制台将 html 文件下载到本地计算机,然后进入克隆的 GitHub 存储库文件夹,将聚类和推荐端点 API URL 替换为实际的 API URL,然后在 UI 中查看最终结果。下图展示了下载 UI 代码文件的方法,以及该文件中所需更改的 REST API 端点 URL。
配置完成后,在浏览器上访问该应用。UI 如下所示:输入开始年份、时长分钟数、评级、投票数和流派等条件:

清理资源
- 回到 Cloud9 控制台,前往 Chalice 项目 sagemaker-apigateway-lambda-chalice 的根目录,执行 chalice delete,删除第一个 REST API 的 Lambda 和 API Gateway。
- 在 Cloud9 控制台,前往 Chalice 项目 query-athena-boto3 的根目录,执行 chalice delete,删除第二个 REST API 的 Lambda 和 API Gateway。
- 进入亚马逊云科技控制台,前往 SageMaker Service(SageMaker 服务)-> Inference(推理)-> Endpoints(端点),删除实验中创建的两个 SageMaker 模型端点。
- 删除 Cloud9 环境。
- 删除 S3 存储桶中根据 CloudFormation 模板创建的内容。完成这一步后,才可以在删除 CloudFormation 堆栈时删除 S3 存储桶。
- 从 Amazon CloudFormation 控制台中删除 main-stack.yaml。它是整个嵌套堆栈的父级堆栈,这样可以删除其他所有已部署资源。
以下是有关本教程试验操作的 3 个视频
视频 1 演示数据准备、数据分析和可视化的基本步骤,它们是特征工程的一部分,能够帮我们得出有助于训练和构建机器学习模型的特征列表。
视频 2 演示如何训练、构建和部署自定义缩放模型,以及 SageMaker 上的 K means 聚类模型。
视频 3 演示如何在 Lambda 和 API Gateway 的帮助下为机器学习模型创建 REST API,并将 API 与 UI 集成在一起。
随着您继续您的学习之旅,建议您更深入地研究我们今天使用的工具,例如 Lambda、API Gateway、Chalice 和 SageMaker。这些强大的工具非常有助于您实现数据科学和机器学习项目。以下是帮助您掌握这些工具的一些后续步骤:
- Lambda:通过学习使用 Amazon Lambda,掌握无服务器计算和事件驱动型编程,构建可扩展应用程序。
- API Gateway:通过学习使用 API Gateway,了解 RESTful API 设计,理解如何在规模化场景下保护、部署和监控 API。
- Chalice:Chalice 简化了亚马逊云科技上的无服务器应用程序开发。深入了解其文档并探索更多使用场景。
- SageMaker:学习了解 SageMaker 提供的其他算法,探索优化模型性能的超参数调优技术。此外,学习如何将 SageMaker 与其他亚马逊云科技服务(如 Amazon Glue)集成,实现数据准备。







