AWS Germany – Amazon Web Services in Deutschland
Einsatz von Cloud- und KI-Technologien auf AWS zur Verbesserung des Ausfallmanagement in Stromnetzen
Großstörungen im urbanen Stromnetz folgen einem vorhersehbaren Muster: Physische Reparaturen brauchen Zeit – die Zeit bis zum belastbaren Lagebild und zur sicheren Wiederherstellung lässt sich jedoch deutlich verkürzen. Viele Netzbetreiber setzen bereits Outage Management Systeme (OMS) und Fault Location, Isolation, and Service Restoration (FLISR) ein. Dennoch stoßen On-Premises-Architekturen bei Lastspitzen häufig an Grenzen – genau dann, wenn Stabilität und Performance am wichtigsten sind.
Dieser Beitrag zeigt, wie eine Cloud-Ergänzungsschicht („Surge Layer“) auf Amazon Web Services (AWS) bestehende OMS/FLISR-Lösungen in Ausnahmesituationen entlasten kann, ohne Schutz- und Leittechnik in die Cloud zu verlagern. Die physische Wiederherstellung kritischer Leitungen kann Tage dauern. Umso wichtiger ist es, die digitalen Schritte davor – Lagebild, sichere Isolation, Schalt- und Wiederherstellungsplanung sowie Koordination – auch unter Peak-Last stabil und schnell zu halten.
Ein AWS-basierter Surge Layer ergänzt OMS/FLISR dafür mit skalierbarer Ereignisverarbeitung, hochverfügbaren Workflows und einem „as-operated“-Netzmodell als Datenprodukt. Der Erfolg ist messbar über Time-to-Lagebild, Time-to-Switching-Plan, Backlog-Reduktion und konsistente Stakeholder-Kommunikation. Das zeigt sich in weniger ungeplanten Kundenminuten, geringeren Einsatz- und Koordinationskosten sowie verlässlicher Kommunikation gegenüber kritischen Kunden und Stakeholdern.
OT bleibt deterministisch, die Cloud skaliert die Entscheidungs- und Prozesskette
Ein bewährtes Architekturprinzip ist die Trennung zwischen Kontrolle und Kontext. Die deterministische Welt bleibt dort, wo sie hingehört: Schutzgeräte, Stationsautomatisierung und Leitsysteme führen Schalthandlungen aus und setzen Sicherheitslogiken durch. Die Cloud ergänzt diese Welt um skalierbaren Kontext: Sie nimmt Ereignisse auf, korreliert sie, berechnet Auswirkungen, bewertet Alternativen und orchestriert die Prozesskette, die in großflächigen Störungen sonst manuell und fehleranfällig wird. Dieses Muster – oft als „Surge Layer“ beschrieben – ist deshalb so attraktiv, weil es bestehende OMS/FLISR-Lösungen nicht ersetzt, sondern entlastet und ihnen zuarbeitet, genau dann, wenn Lastspitzen auftreten.
Drei kritische Fähigkeiten
1. Ereignisverarbeitung unter Last
Impact: Geringeres Alarm-Backlog plus schneller zu einem konsistenten Lagebild – Basis für frühere, sichere Umschaltungen und verlässlichere Kommunikation.
Bei großflächigen Kabelstörungen treffen in Minuten Schutzmeldungen, Schaltzustände, SCADA-Alarme, Störungsprotokolle, Tickets, Kundenkontakte und Statusmeldungen ein. Wenn diese Signale ungefiltert über enge Kopplungspunkte ins OMS/DMS laufen, entstehen Alarm-Stürme, Backlogs und widersprüchliche Lagebilder. Deshalb braucht es eine Entkopplungsschicht nahe den Integrationspunkten im Leitstellen-/Rechenzentrumsumfeld. Der Export folgt dem etablierten Zonen-/Segmentierungsprinzip (Purdue-Denke): Publizierte SCADA/Historian-Daten werden über ein OT-Security/Inspection-Segment (DMZ-ähnlich) kontrolliert bereitgestellt (Outbound-only, allow-listed, auditierbar). Die zentrale Netzwerksegmentierung und Policy-Steuerung lässt sich dabei über AWS Cloud WAN abbilden; die erzwungene Inspection z. B. über AWS Network Firewall. Der Übergang in AWS erfolgt über private, nachvollziehbare Pfade – typischerweise AWS Direct Connect (mit Site-to-Site VPN als Fallback) – und für Service-Zugriffe zusätzlich über AWS PrivateLink/VPC Endpoints, sodass kein OT-Traffic über das öffentliche Internet laufen muss. Mehr zum Thema OT/IT Integration gibt es in diesem Whitepaper.
In AWS absorbiert ein Streaming-Backbone wie Amazon Kinesis Data Streams (oder Amazon MSK) die Lastspitzen. Korrelationsservices auf AWS Lambda oder Amazon ECS deduplizieren und korrelieren daraus kontextangereicherte Incidents, die als strukturierte Objekte an OMS/FLISR und nachgelagerte Workflows gehen. Ergebnis: OMS/FLISR bekommen priorisierte Incident-Objekte statt Meldungsflut – und kommen schneller von Alarmen zu sicheren Maßnahmen.
2. Operative Verfügbarkeit
Impact: Das Lagebild und die Prozesskette bleiben verfügbar, selbst wenn Teile der lokalen IT/Kommunikation degradieren – entscheidend für Krisensteuerung.
In Störlagen sind nicht nur Netzelemente betroffen; oft geraten auch Kommunikation, Zugang zu Standorten oder lokale IT-Ressourcen unter Druck. Eine Verarbeitungskette, die über mehrere Availability Zones redundant betrieben wird, sorgt dafür, dass Lagebild-Pipeline, Ticket-Orchestrierung und Kommunikationsschnittstellen weiterlaufen, selbst wenn einzelne Komponenten degradieren. Entscheidend ist das Design: asynchrone Kopplung über Streams und Queues statt synchroner Punkt-zu-Punkt-Abhängigkeiten, idempotente Verarbeitung mit klaren Event-IDs und eine Orchestrierung, die Fehlerszenarien explizit abbildet. AWS Step Functions hilft dabei, Wiederholungen, Timeouts und kompensierende Schritte kontrolliert zu modellieren, sodass Workflows auch unter Störbedingungen stabil bleiben.
3. Netzmodell als Datenprodukt
Impact: Schnellere Schalt- bzw. Wiederherstellungsplanung, weil ‘as-operated’ statt ‘as-designed’ genutzt wird.
Viele FLISR-Algorithmen sind robust – aber nur so gut wie das „as-operated“-Netzmodell, das aktuelle Schaltzustände, offene Ringe, Rückspeisungen und korrekte Zuordnungen zwischen Kunden, Abgängen und Assets widerspiegelt. Unter Stress fällt sofort auf, wo „as-designed“ und „as-operated“ auseinanderlaufen. Eine Cloud-Ergänzung kann das Netzmodell als eigenständiges Datenprodukt betreiben, das laufend aktualisiert wird und in Sekunden abfragbar ist. Ein Graph-Ansatz – als Ergänzung zum GIS – passt gut, weil zentrale Fragen Traversals sind: „Welche Kunden hängen hinter diesem Schalterzustand?“ oder „Welche Wege sind aktuell geschlossen?“. Amazon Neptune eignet sich als verwaltete Graphdatenbank, um Schaltgeräte, Stationen, Kabelabschnitte und elektrische Verbindungen inklusive Zuständen zu modellieren. Asset-Stammdaten, GIS-Attribute und Historie lassen sich parallel in einem Data Lake auf S3 verwalten, katalogisiert mit AWS Glue und abgesichert mit Lake Formation. Zeitreihen aus Messwerten können in Amazon Timestream oder – je nach Abfrageprofil – in alternativen Datenspeichern liegen. Der Nutzen ist konkret: Topologie- und Betroffenheitsrechnungen werden zu einem hochperformanten Service, der auch dann skaliert, wenn viele Nutzer und Systeme gleichzeitig darauf zugreifen.
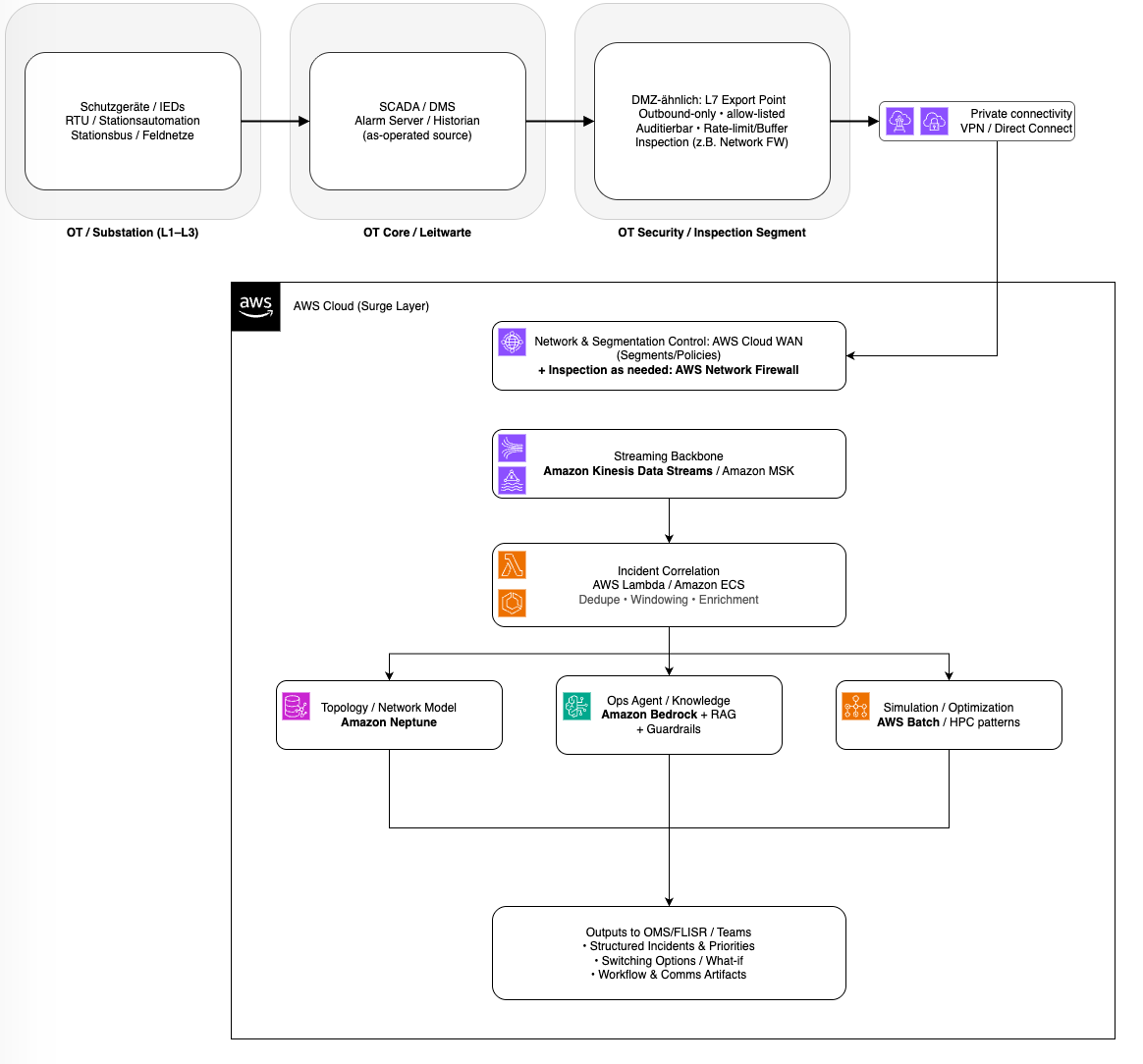
Grafik: OT/IT-Datenpfad für OMS/FLISR: L7-Export über OT-DMZ in ein skalierbares Cloud-Surge-Layer
Zusätzliche Werttreiber
Graphen zur Bottleneck-Analyse (Priorisierung von Härtung/Invest): Urbane Netze haben Trassen und Querungen, die strukturell besonders kritisch sind. Mit Graphmetriken lassen sich Single Points of Failure, Cut-Sets und Pfaddiversität bestimmen und priorisieren, ergänzt durch Zentralitätsmetriken, die zeigen, welche Netzelemente überproportional viele Versorgungswege „tragen“. Das ersetzt keine baulichen Maßnahmen, liefert aber belastbare, wiederholbare Entscheidungsgrundlagen für Redundanzplanung, Trassenhärtung und Instandhaltungspriorisierung – und zwar nicht als einmalige Studie, sondern als regelmäßiger Job nach Netzänderungen.
HPC für FLISR-Varianten (mehr geprüfte Optionen in Minuten): Für FLISR in der Wiederherstellungsphase wird Rechenzeit schnell zum limitierenden Faktor, sobald man Unsicherheiten und Varianten ernst nimmt: mehrere plausible Fehlerlokationen, unterschiedliche Lastannahmen, thermische Grenzen, Spannungsbänder und N-1/N-k-Bedingungen. Dann möchte man viele Hypothesen parallel testen und robuste Optionen mit Sensitivitäten liefern. Cloud-HPC ist dafür ein operativer Beschleuniger. Mit AWS Batch lassen sich containerisierte Lastfluss- und Optimierungsjobs parallel ausführen und automatisch skalieren. Für klassische HPC-Cluster-Setups kann AWS ParallelCluster genutzt werden, um etwa Slurm-basierte Umgebungen reproduzierbar aufzubauen. Für datenintensive Simulationen bietet Amazon FSx for Lustre hohe Durchsatzraten und eine S3-Integration für saubere Daten- und Ergebnisverwaltung.
Operations Copilot (weniger manuelle Lagebild-/Doku-Arbeit): Parallel dazu entsteht in Großstörungen eine hohe „Textlast“: Field-Notes, Tickets, interne Lageupdates, Standardanweisungen und Prüfprotokolle. Generative KI ist hier am stärksten, wenn sie Informationsarbeit reduziert und Wissen auffindbar macht, nicht wenn sie Entscheidungen ersetzt. Amazon Bedrock bietet eine einheitliche API für Foundation Models und eignet sich, um einen Operations-Copilot zu implementieren, der über Retrieval-Augmented Generation Antworten aus freigegebenen Betriebsdokumenten erzeugt, Zusammenfassungen erstellt oder Tickets normalisiert. Mit Bedrock Guardrails lassen sich zusätzlich Regeln für Inhalte und Ausgabeformate durchsetzen, um das System konsequent „assistierend“ zu halten.
Sicherheit, Compliance und Souveränität: Schließlich müssen Sicherheit, Nachweisbarkeit und Souveränität sauber gelöst sein. In der Umsetzung bedeutet das typischerweise strikte Segmentierung und kontrollierte Übergänge (z. B. VPN oder AWS Direct Connect), Least-Privilege-Berechtigungen in AWS IAM, zentrale Schlüsselverwaltung über AWS KMS, Audit Trails über AWS CloudTrail sowie kontinuierliches Security Monitoring. Wenn zusätzlich Anforderungen an Datenresidenz und operative Autonomie bestehen, kann die AWS European Sovereign Cloud (ESC) für Teile des Surge-Layers eine passende Zielumgebung sein, insbesondere für Betriebsdaten, Incident-Artefakte und KI-gestützte Wissensfunktionen.
Fazit
Urbane Netzausfälle zeigen, dass bei Ausfällen kritischer Leitungen die physische Wiederherstellung naturgemäß Zeit braucht – aber die digitale Prozesskette darüber entscheidet, wie schnell und wie sicher wieder versorgt werden kann. Wenn OMS und FLISR bereits im Einsatz sind, liefert die Cloud den größten Mehrwert nicht durch neue Kernfunktionen, sondern durch eine robuste, skalierbare Ausführungsebene für die Dinge, die in großflächigen Störungen zu Flaschenhälsen werden: Ereignisaufnahme und -korrelation unter Peak-Last, schnelle Topologie- und Betroffenheitsrechnungen, parallele Simulation/Optimierung sowie auditierbare Workflows und Wissensassistenz. Das reduziert die Zeit bis zu sicheren, netzverträglichen Entscheidungen – und macht die Organisation insgesamt resilienter.
Über die Autoren
 |
Sascha Janssen is a Principal Solutions Architect at AWS supporting Energy & Utility customers in building secure, scalable platforms for critical infrastructure. His focus is on distributed architectures, data-intensive systems, and trust models that enable regulated enterprises to operate complex, multi-stakeholder environments with confidence. |
 |
Sherif Elmeshad leads the Solutions Architecture team for Power & Utilities in Germany at AWS. Drawing on his experience in the energy sector, he helps utilities and energy companies navigate complex challenges with the energy transition and operational excellence. His focus is on architecting solutions that enable digital transformation and drive innovation in the evolving energy landscape. |