Preparación de datos de entrenamiento para machine learning con un mínimo de código
TUTORIAL
Información general
Lo que logrará
En esta guía, aprenderá a hacer lo siguiente:
- Visualizar y analizar datos para entender relaciones clave.
- Aplicar transformaciones para limpiar datos y generar nuevas características.
- Generar automáticamente cuadernos para un flujo de trabajo de preparación de datos repetible.
Requisitos previos
Antes de comenzar este tutorial, necesitará lo siguiente:
- Una cuenta de AWS: si aún no tiene una cuenta, siga la guía de introducción a la Configuración de su entorno de AWS para obtener una descripción general rápida.
Experiencia en AWS
Principiante
Tiempo de realización
30 minutos
Costo de realización
Consulte los precios de Amazon SageMaker para estimar el costo de este tutorial.
Requisitos
Debe iniciar sesión en una cuenta de AWS.
Servicios utilizados
Amazon SageMaker Data Wrangler
Última actualización
1 de julio de 2022
Implementación
Paso 1: configurar el dominio de Amazon SageMaker Studio
Con Amazon SageMaker, puede implementar un modelo de forma visual a través de la consola o mediante programación con el uso de SageMaker Studio o cuadernos de SageMaker. En este tutorial, implementará el modelo por programación mediante un cuaderno de SageMaker Studio, que requiere un dominio de SageMaker Studio.
Una cuenta de AWS solo puede tener un dominio de SageMaker Studio por región. Si ya tiene un dominio de SageMaker Studio en la región Este de EE. UU. (Norte de Virginia), siga la guía de configuración de SageMaker Studio para adjuntar las políticas de AWS IAM requeridas a su cuenta de SageMaker Studio; luego omita el paso 1 y continúe directamente con el paso 2.
Si no tiene un dominio de SageMaker Studio existente, continúe con el paso 1 a fin de ejecutar una plantilla de AWS CloudFormation que cree un dominio de SageMaker Studio y agregue los permisos necesarios para el resto de este tutorial.
Elija el enlace de la pila de AWS CloudFormation. Este enlace abre la consola de AWS CloudFormation y crea su dominio de SageMaker Studio y un usuario denominado studio-user. También agrega los permisos necesarios a su cuenta de SageMaker Studio. En la consola de CloudFormation, confirme que Este de EE. UU. (Norte de Virginia) sea la región que se muestra en la esquina superior derecha. El nombre de la pila debe ser CFN-SM-IM-Lambda-Catalog y no debe cambiarse. Esta pila tarda unos 10 minutos en crear todos los recursos.
Esta pila asume que ya tiene una VPC pública configurada en su cuenta. Si no tiene una VPC pública, consulte VPC con una única subred pública para obtener información sobre cómo crear una VPC pública.

Seleccione I acknowledge that AWS CloudFormation might create IAM resources (Acepto que AWS CloudFormation podría crear recursos de IAM) y luego elija Create stack (Crear pila).

En el panel de CloudFormation, elija Stacks (Pilas). La pila tarda unos 10 minutos en crearse. Cuando se crea la pila, su estado cambia de CREATE_IN_PROGRESS a CREATE_COMPLETE.

Paso 2: crear un nuevo flujo de Sagemaker Data Wrangler
Sagemaker Data Wrangler acepta datos de una amplia variedad de fuentes, incluso de Amazon S3, Amazon Athena, Amazon Redshift, Snowflake y Databricks. En este paso, creará un nuevo flujo de Sagemaker Data Wrangler mediante el uso del conjunto de datos de riesgos de crédito alemán de UCI, almacenado en Amazon S3. Este conjunto de datos contiene información demográfica y financiera sobre individuos junto a una etiqueta que indica el nivel de riesgo de crédito del individuo.
Ingrese SageMaker Studio en la barra de búsqueda de la consola y luego seleccione SageMaker Studio.

Elija US East (N. Virginia) (Este de EE. UU. [Norte de Virginia]) de la lista desplegable Region (Región) en la esquina superior derecha de la consola de SageMaker. En Launch app (Lanzar aplicación), seleccione Studio para abrir SageMaker Studio con el perfil studio-user.

Abra la interfaz de SageMaker Studio. En la barra de navegación, seleccione File (Archivo), New (Nuevo), Data Wrangler Flow (Flujo de Data Wrangler).

En la pestaña Import (Importar) debajo de Import data (Importar datos), seleccione Amazon S3.
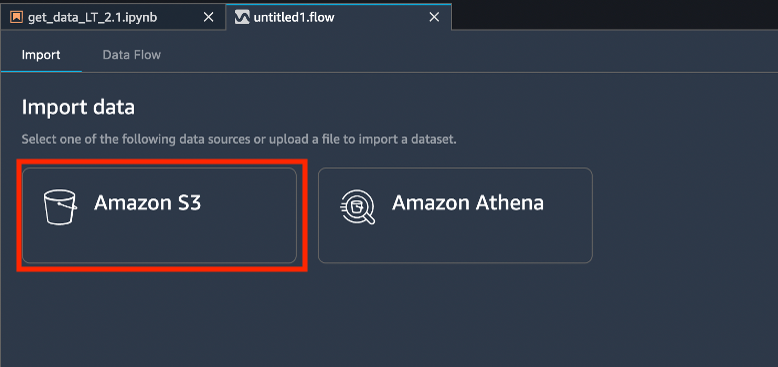
En el campo S3 URI path (Ruta de URI de S3), ingrese s3://sagemaker-sample-files/datasets/tabular/uci_statlog_german_credit_data/german_credit_data.csv y seleccione Go (Ir). En Object name (Nombre de objeto), haga clic en german_credit_data.csv y luego seleccione Import (Importar).

Paso 3: perfilar los datos
En este paso, utilizará SageMaker Data Wrangler para evaluar la calidad del conjunto de datos de entrenamiento. Puede usar la característica Quick Model (Modelo rápido) para estimar aproximadamente la calidad de predicción esperada y el poder predictivo de las características en su conjunto de datos.
En la pestaña Data Flow (Flujo de datos), en el diagrama de flujo de datos, seleccione el ícono +, Add analysis (Agregar análisis).
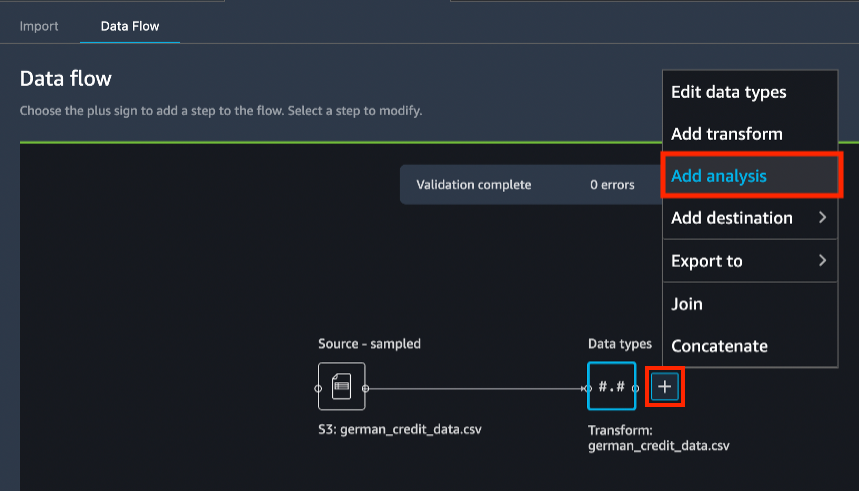
Debajo del panel Create analysis (Crear análisis), en Analysis type (Tipo de análisis), seleccione Histogram (Histograma).
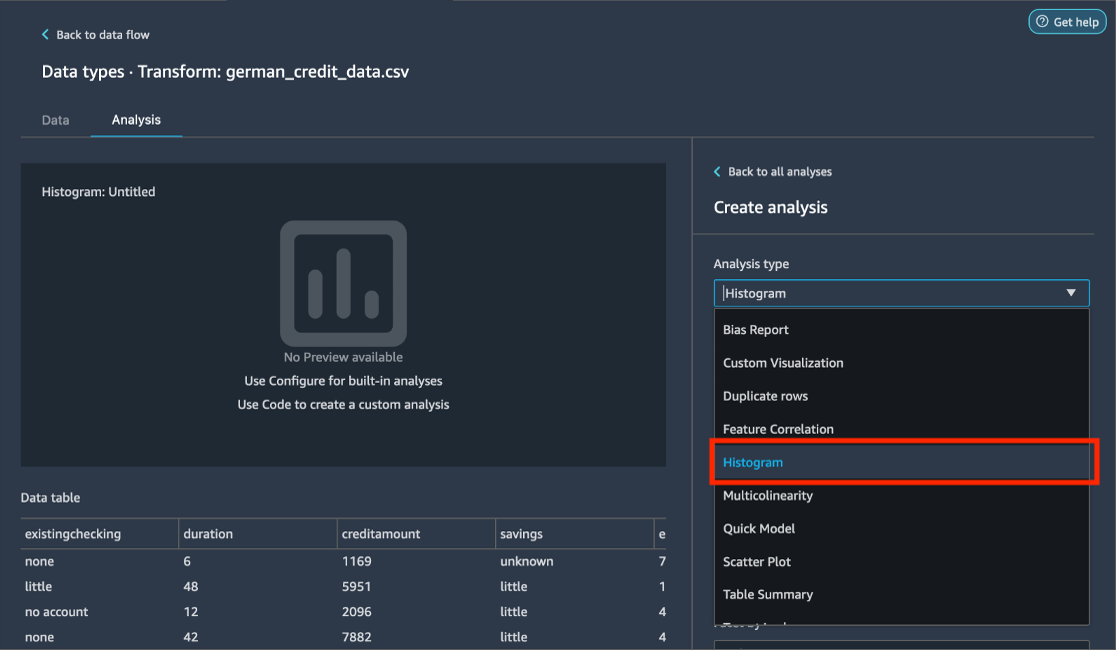
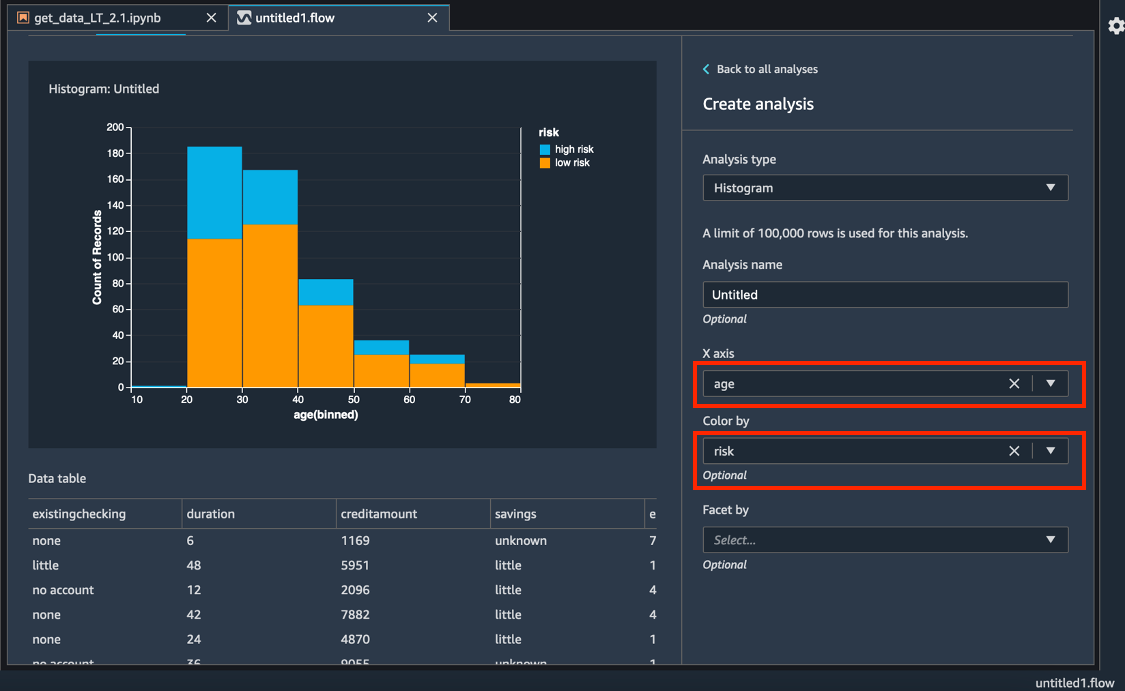
En X axis (Eje X), seleccione age (edad).
En Color by (Colorear por), seleccione risk (riesgo).
Elija Preview (Vista previa) para generar un histograma del campo credit risk (riesgo de crédito) codificado por colores según el rango de age (edad).
Elija Save (Guardar) para guardar éste análisis en el flujo.
A fin de entender que tan bien adaptado está el conjunto de datos para entrenar un modelo que predice la variable de destino risk (riesgo), ejecute el análisis Quick Model (Modelo rápido). En la pestaña Analysis (Análisis), elija Create new analysis (Crear nuevo análisis).
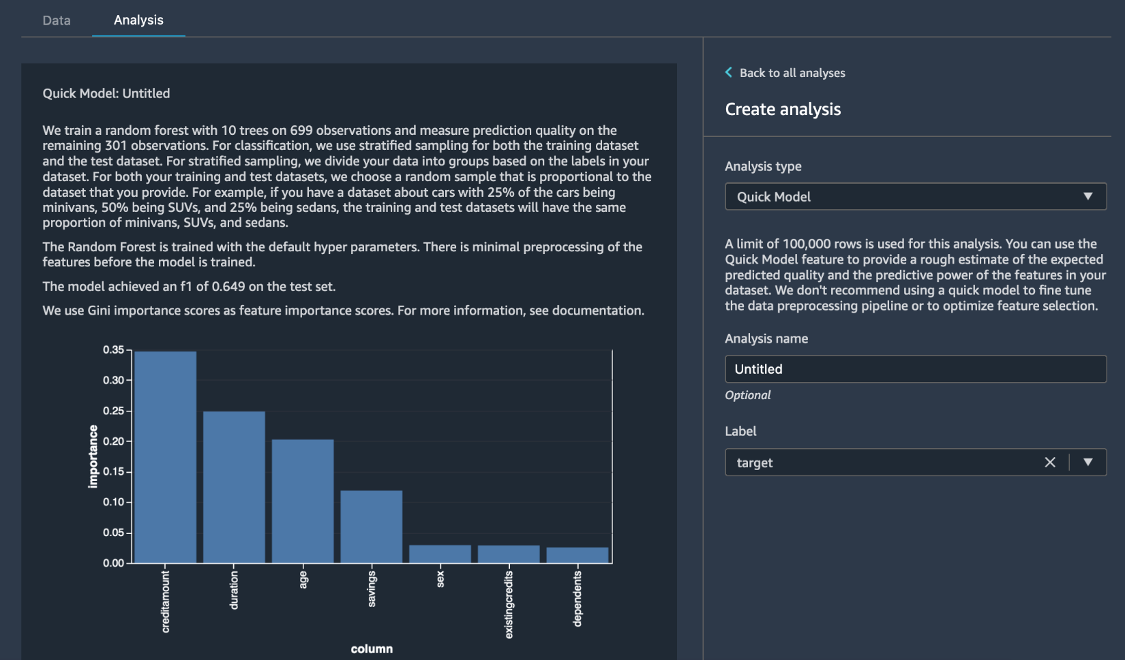
Debajo del panel Create analysis (Crear análisis), en Analysis type (Tipo de análisis), elija Quick Model (Modelo rápido). En Label (Etiqueta), seleccione risk (riesgo) y, a continuación, elija Preview (Vista previa). El panel de Quick Model (Modelo rápido) muestra una breve descripción del modelo utilizado y algunas estadísticas básicas, incluido el valor F1 y la importancia de las características, para ayudarlo a evaluar la calidad del conjunto de datos. Elija Save (Guardar).
Paso 4: agregar transformaciones al flujo de datos
SageMaker Data Wrangler simplifica el procesamiento de datos al proporcionar una interfaz visual con la cual es posible agregar una amplia variedad de transformaciones prediseñadas. También puede escribir una transformación personalizada mediante el uso de SageMaker Data Wrangler. En este paso, aplanará los datos de cadenas complejas, codificará categorías, cambiará el nombre de las columnas y eliminará las columnas innecesarias con el editor visual. Luego, dividirá la columna status_sex en dos nuevas columnas, marital_status y sex.
Para navegar al diagrama de flujo de datos, seleccione Data flow (Flujo de datos).

En el diagrama de flujo de datos, seleccione el ícono +, Add transform (Agregar transformación).

Debajo del panel ALL STEPS (Todos los pasos), seleccione Add step (Agregar paso).

Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Search and edit (Buscar y editar), que es una transformación utilizada para manipular datos de cadenas.

Debajo del panel SEARCH AND EDIT (Buscar y editar), en Transform (Transformar), seleccione Split string by delimiter (Dividir cadena por delimitador). En Input columns (Columnas de entrada), seleccione status_sex. En el cuadro Delimiter (Delimitador), ingrese el símbolo :. En Output column (Columna de salida), ingrese vec. Seleccione Preview (Vista previa) y luego Add (Agregar).
Esta transformación crea una nueva columna llamada vec al final del marco de datos al dividir la columna status_sex. La columna status_sex contiene cadenas delimitadas por dos puntos, y la nueva columna vec contiene vectores delimitados por comas.

Para dividir la columna vec y crear dos nuevas columnas, sex_split_0 y sex_split_1:
Debajo de ALL STEPS (Todos los pasos), seleccione + Add step (+ Agregar paso).
Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Manage vectors (Administrar vectores).
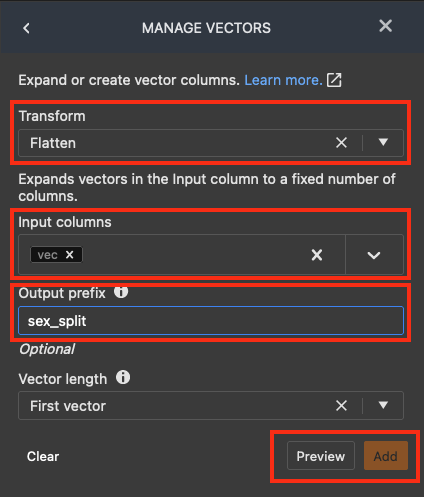
Debajo del panel MANAGE VECTORS (Administrar vectores), en Transform (Transformar) seleccione Flatten (Aplanar). En Input columns (Columnas de entrada), seleccione vec. En output_prefix, ingrese sex_split.
Seleccione Preview (Vista previa) y luego Add (Agregar).
Para cambiar el nombre de las columnas creadas a partir de la transformación de división:
Debajo del panel ALL STEPS (Todos los pasos), seleccione + Add step (+ Agregar paso).
Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Manage columns (Administrar vectores).
Debajo del panel MANAGE COLUMNS (Administrar columnas), en Transform (Transformar), seleccione Rename column (Cambiar el nombre de la columna). En Input column (Columna de entrada), seleccione sex_split_0. En el cuadro New name (Nuevo nombre), ingrese sex.
Seleccione Preview (Vista previa) y luego Add (Agregar).
Repita este procedimiento para cambiar el nombre de sex_split_1 a marital_status.

Paso 5: agregar codificación categórica
En este paso, va a crear un destino de modelado y codificar variables categóricas. La codificación categórica transforma las categorías de tipos de datos de cadenas en etiquetas numéricas. Es una tarea de preprocesamiento común porque las etiquetas numéricas se pueden usar en una amplia variedad de tipos de modelos.
En el conjunto de datos, la clasificación de riesgo de crédito está representada por las cadenas high risk (riesgo alto) y low risk (riesgo bajo). En este paso, va a convertir esta clasificación en una representación binaria, 0 o 1.
Debajo del panel ALL STEPS (Todos los pasos), seleccione + Add Step (+ Agregar paso). Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Encode categorical (Codificación categórica). SageMaker Data Wrangler proporciona tres tipos de transformación: codificación ordinal, codificación en caliente y codificación de similitud. Debajo del panel ENCODE CATEGORICAL (Codificación categórica), en Transform (Transformar), deje la Ordinal encode (Codificación ordinal) predeterminada. En Input columns (Columnas de entrada), seleccione risk (riesgo). En Output column (Columna de salida), ingrese target (destino). Ignore el cuadro Invalid handling strategy (Estrategia de gestión no válida) para este tutorial. Seleccione Preview (Vista previa) y luego Add (Agregar).

# Table is available as variable ‘df’
savings_map = {"unknown":0, "little":1, "moderate":2, "high":3, "very high":4}
df["savings"] = df["savings"].map(savings_map).fillna(df["savings"])

Utilice la transformación Encode categorical (Codificación categórica) para codificar las columnas restantes, housing, job, sex y marital_status de la siguiente manera: en ALL STEPS (Todos los pasos), elija + Add Step (+ Agregar paso). Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Encode categorical (Codificación categórica). Debajo del panel ENCODE CATEGORICAL (Codificación categórica), en Transform (Transformar), deje la Ordinal encode (Codificación ordinal) predeterminada. En Input columns (Columnas de entrada), seleccione housing, job, sex y marital_status. Deje Output column (Columna de salida) en blanco de modo tal que los valores codificados reemplacen los valores categóricos. Seleccione Preview (Vista previa) y luego Add (Agregar).

Para escalar la columna numérica creditamount, aplique un escalador a la cantidad de crédito para normalizar la distribución de los datos en esta columna: debajo del panel ALL STEPS (Todos los pasos), elija + Add Step (+ Agregar paso). Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Process numeric (Proceso numérico). En Scaler (Escalador), seleccione la opción predeterminada Standard scaler (Escalador estándar). En Input columns (Columnas de entrada), seleccione creditamount. Seleccione Preview (Vista previa) y luego Add (Agregar).


Para eliminar las columnas originales que transformó: debajo del panel ALL STEPS (Todos los pasos), seleccione + Add step (+ Agregar paso). Desde la lista ADD TRANSFORM (Agregar transformación), seleccione Manage columns (Administrar columnas). Debajo del panel MANAGE COLUMNS (Administrar columnas), en Transform (Transformar), seleccione Drop Column (Eliminar columna). En Columns to drop (Columnas para eliminar), seleccione status_sex, existingchecking, employmentsince, risk y vec. Seleccione Preview (Vista previa) y luego Add (Agregar).

Paso 6: ejecutar una comprobación de sesgo de datos
En este paso, comprobará los datos en busca de sesgo con el uso de Amazon SageMaker Clarify, que proporciona una mayor visibilidad de los datos y modelos de entrenamiento para poder identificar y limitar los sesgos y explicar las predicciones.
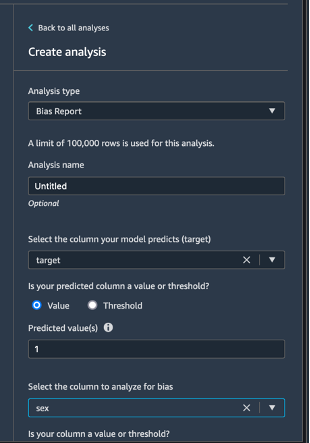
Seleccione Data flow (Flujo de datos) en la parte superior izquierda para volver al diagrama de flujo de datos. Seleccione el ícono +, Add analysis (Agregar análisis). En el panel Create analysis (Crear análisis), en Analysis type (Tipo de análisis), seleccione Bias Report (Informe de sesgo). En Analysis name (Nombre de análisis), ingrese cualquier nombre. En Select the column your model predicts (target) (Seleccionar la columna que predice el modelo [destino]), seleccione target (destino). Deje la casilla de verificación de Value (Valor) seleccionada. En el cuadro Predicted value(s) (Valor[es] predicho[s]), ingrese 1. En Select the column to analyze for bias (Seleccionar la columna para analizar el sesgo), seleccione sex. En Choose bias metrics (Elegir métricas de sesgo), mantenga las selecciones predeterminadas. Elija Check for bias (Comprobar el sesgo).
Después de unos segundos, SageMaker Clarify genera un informe que muestra el valor de las columnas de destino y de prueba en una serie de métricas relacionadas con el sesgo, incluidas Desequilibrio de clase (CI) y Diferencia en proporciones positivas en etiquetas (DPL). En este caso, los datos están ligeramente sesgados en cuanto al sexo (-0,38) y poco sesgados en cuanto a las etiquetas (0,075). En base a este informe, puede considerar un método de corrección de sesgos, como el uso de la transformación SMOTE incorporada a SageMaker Data Wrangler. A los efectos de este tutorial, se omite el paso de corrección. Seleccione Save (Guardar) para guardar el informe de sesgo en el flujo de datos.

Paso 7: exportar el flujo de datos
Exporte el flujo de datos a un cuaderno de Jupyter para ejecutar los pasos como trabajos de Procesamiento de SageMaker. Estos pasos procesan los datos de acuerdo con el flujo de datos definido y almacenan los resultados en Amazon S3 o en el Almacén de características de Amazon SageMaker.
Desde el diagrama de flujo de datos, seleccione el ícono +, Export to (Exportar a), Amazon S3 (via Jupyter Notebook) (Amazon S3 [a través de un cuaderno de Jupyter]). Esto crea un cuaderno en SageMaker Studio donde puede ejecutar los trabajos de Procesamiento de SageMaker generados para crear el conjunto de datos transformado. Ejecute este cuaderno para almacenar los resultados en el bucket de S3 predeterminado.



Paso 8: eliminar los recursos
Una práctica recomendada es eliminar los recursos que ya no se utilizan para no incurrir en cargos no deseados.
Para eliminar el bucket de S3, haga lo siguiente:
- Abra la consola de Amazon S3. En la barra de navegación, seleccione Buckets, sagemaker-<your-Region>-<your-account-id> y, a continuación, marque la casilla de verificación junto a data_wrangler_flows. Luego, seleccione Delete (Eliminar).
- En el cuadro de diálogo Delete objects (Eliminar objetos), verifique que haya seleccionado el objeto apropiado para eliminar e ingrese permanently delete (eliminar de forma permanente) en la casilla de confirmación Permanently delete objects (Eliminar objetos de forma permanente).
- Una vez que haya finalizado esto y el bucket esté vacío, puede eliminar el bucket sagemaker-<your-Region>-<your-account-id> siguiendo el mismo procedimiento nuevamente.

El kernel de ciencia de datos utilizado para ejecutar la imagen del cuaderno en este tutorial acumulará cargos hasta que lo detenga o realice los siguientes pasos para eliminar las aplicaciones. Para obtener más información, consulte Apagar recursos en la Guía para desarrolladores de Amazon SageMaker.
Para eliminar las aplicaciones de SageMaker Studio, haga lo siguiente: en la consola de SageMaker Studio, elija studio-user y, a continuación, elimine todas las aplicaciones que aparecen en Apps (Aplicaciones) al seleccionar Delete app (Eliminar aplicación). Espere hasta que el Status (Estado) cambie a Deleted (Eliminado).

Si usó un dominio existente de SageMaker Studio en el paso 1, omita el resto del paso 8 y vaya directamente a la sección de conclusión.
Si ejecutó la plantilla de CloudFormation en el paso 1 para crear un dominio de SageMaker Studio nuevo, continúe con los siguientes pasos a fin de eliminar el dominio, el usuario y los recursos creados por la plantilla de CloudFormation.
Para abrir la consola de CloudFormation, ingrese CloudFormation en la barra de búsqueda de la consola de AWS y elija CloudFormation en los resultados de búsqueda.

En el panel de CloudFormation, elija Stacks (Pilas). En la lista desplegable de estado, seleccione Active (Activo). En Stack name (Nombre de la pila), elija CFN-SM-IM-Lambda-catalog para abrir la página de detalles de la pila.

En la página de detalles de la pila CFN-SM-IM-Lambda-catalog, elija Delete (Eliminar) para eliminar la pila junto con los recursos que creó en el paso 1.

Conclusión
Ha utilizado correctamente Amazon Sagemaker Data Wrangler con el fin de preparar datos para entrenar un modelo de machine learning. SageMaker Data Wrangler ofrece una selección de más de 300 transformaciones de datos preconfiguradas, como la conversión del tipo de columna, la codificación en caliente, la imputación de datos faltantes con la media o la mediana, el reescalado de columnas y la incrustación de datos/tiempo; todo esto para que pueda transformar los datos en formatos que puedan utilizarse de manera eficaz en los modelos sin tener que escribir una sola línea de código.
Entrenar un modelo de aprendizaje profundo
Crear un modelo de ML automáticamente
Encontrar más tutoriales prácticos