Partage de données Amazon Redshift
Partager des données en toute sécurité entre les entrepôts sans copier les données
Avantages
-
Rendez les données disponibles pour une utilisation dans plusieurs entrepôts dès qu’elles se trouvent dans n’importe quelle base de données Amazon Redshift. Extrayez, transformez et chargez (ETL) les données à l'aide d'un seul entrepôt pour qu'elles soient accessibles au sein et entre les organisations et les régions AWS. Les ingénieurs de données n’ont pas besoin de créer et de gérer plusieurs pipelines qui permettent l’ETL des données à plusieurs endroits.
-
Accédez aux données avec le calcul de votre choix : différentes tailles (nœuds ou RPU), types (provisionnés ou sans serveur) et plans tarifaires (instances à la demande ou réservées). Choisissez l'entrepôt en fonction des besoins en termes de rapport prix/performances de l'équipe, de l'application ou de la charge de travail. Suivez et surveillez l’utilisation par équipe, contrôlez les coûts et augmentez la transparence
-
Éliminez les silos de données et la duplication des données, car les équipes n’ont pas à déplacer ou à copier les données d’un endroit à un autre. Les équipes peuvent collaborer sur des données en temps réel au point de source pour agir rapidement sur les données. L’accès est géré de manière centralisée via AWS Lake Formation, ce qui permet des contrôles d’accès précis.
-
Accédez aux données de fournisseurs tiers en toute sécurité et facilement, sans les tracas liés aux processus de licence manuels ou à la réalisation d’opérations ETL dans votre entrepôt. Il vous suffit de vous abonner au jeu de données dans AWS Data Exchange depuis Amazon Redshift. Les fournisseurs de données peuvent monétiser leurs données et apporter de la valeur à leurs clients en les mettant à disposition pour une consommation dans les entrepôts des clients en quelques clics
Partage de données Amazon Redshift
Le partage de données Amazon Redshift vous permet de partager des données au sein et entre les organisations, les régions AWS et même des fournisseurs tiers, sans déplacer ni copier les données. Lisez et écrivez dans les mêmes bases de données Redshift en utilisant plusieurs entrepôts de données et étendez la facilité d'utilisation, les performances et les avantages en termes de coûts qu'offre Amazon Redshift aux architectures de maillage de données multi-entrepôts. Donnez instantanément accès à des données actualisées au sein de l'entreprise et dans l'ensemble de celle-ci, en éliminant les multiples pipelines d'extraction, de transformation et de chargement (ETL), en favorisant la collaboration sur les données et en réduisant le temps nécessaire pour obtenir des informations. En outre, il vous permet d'utiliser plusieurs entrepôts de types et de tailles différents pour l'ETL afin que vous puissiez ajuster vos entrepôts en fonction des besoins en termes de rapport prix-performance de vos charges de travail d'écriture. Grâce à l’intégration à AWS Data Exchange, la place de marché d’AWS hébergeant des milliers de jeux de données tiers, les utilisateurs d’Amazon Redshift peuvent facilement et en toute sécurité concéder sous licence des ensembles de données tiers à combiner avec les données de leurs bases de données Redshift pour une analyse holistique et créer de nouvelles opportunités de monétisation des données.
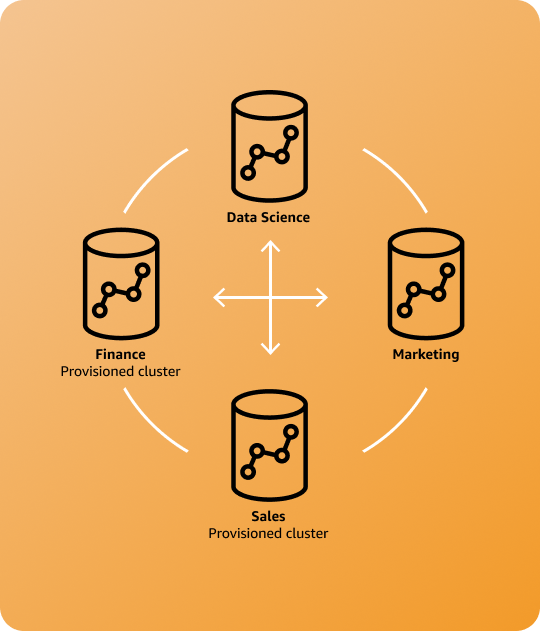
Cas d’utilisation
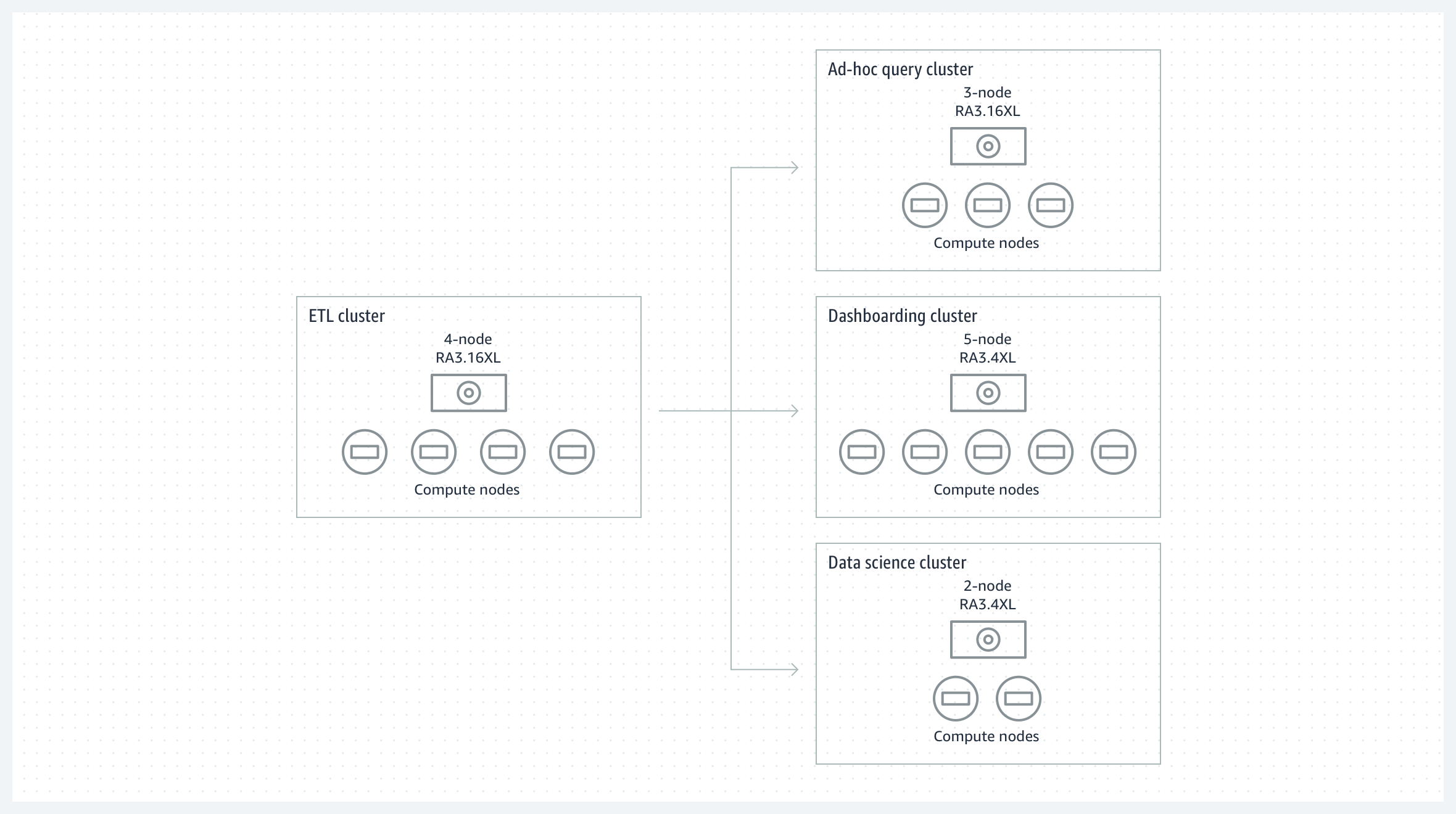
Isolation de la charge de travail et facturation
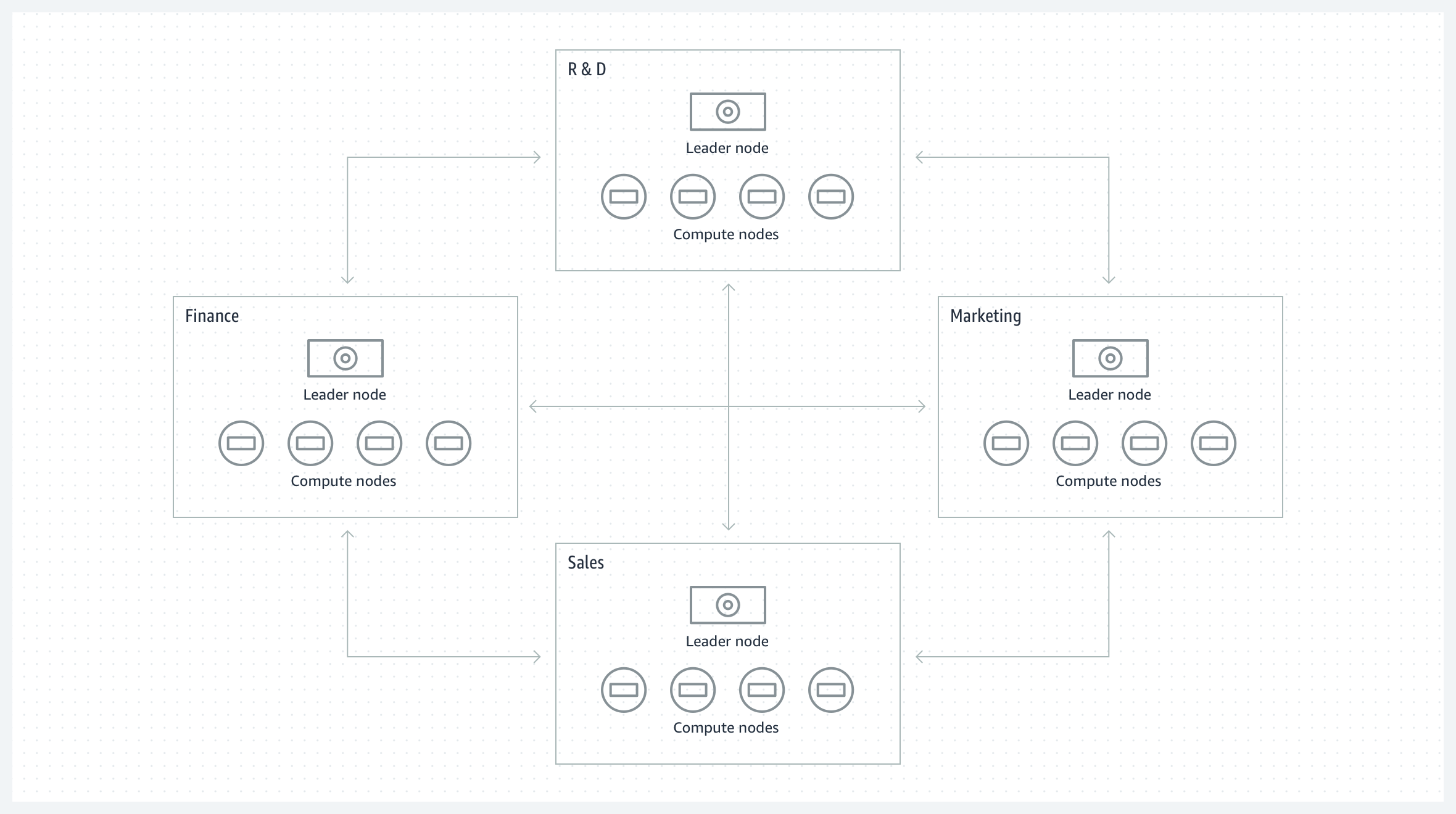
Collaboration entre groupes
Données et analytique en tant que service

Agilité du développement
