Intégration Amazon Redshift pour Apache Spark
Création d’applications Apache Spark qui lisent et écrivent des données à partir d’Amazon Redshift
Pourquoi choisir l’intégration Amazon Redshift pour Apache Spark ?

Les avantages d’Amazon Redshift
-
Augmentez considérablement le nombre de sources de données exploitables dans vos applications d’analytiques et de machine learning (ML) exécutées dans Amazon EMR, AWS Glue ou SageMaker en lisant et écrivant des données dans votre entrepôt des données.
-
Simplifiez le processus de configuration souvent manuel et fastidieux de connecteurs non certifiés et de pilotes JDBC, réduisant ainsi le temps de préparation des tâches liées au ML et aux analytiques.
-
Utilisez plusieurs fonctionnalités de filtration pushdown telles que le tri, l’agrégation, la limitation, la jointure et les fonctions scalaires afin que seules les données pertinentes soient déplacées de l’entrepôt des données Amazon Redshift.
Fonctionnement
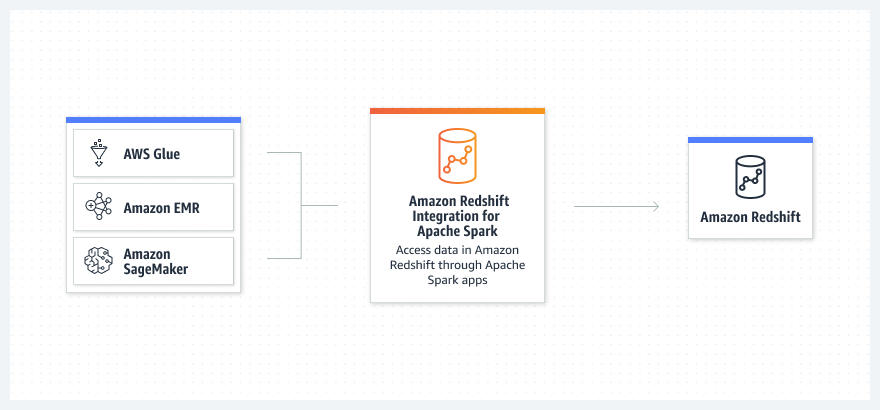
Cas d’utilisation
-
Créez des applications Apache Spark en Java, Scala et Python avec les services d’analyse AWS basés sur Apache Spark.
-
Lisez et écrivez des données vers et depuis Amazon Redshift avec Amazon EMR, AWS Glue, SageMaker et les services AWS analytics et ML.
-
Utilisez Amazon EMR ou AWS Glue afin d’extraire le code de la trame de données de votre tâche ou bloc-notes Apache Spark et vous connecter à Amazon Redshift.
-
Rationalisez votre processus sans installation ni test, avec une sécurité renforcée (informations d’identification basées sur IAM) et des repoussoirs opérationnels, ainsi qu’un format de fichier Parquet pour les performances.
Clients
Corey Johnson, responsable de l’architecture de données - Huron Consulting
Huron est une firme de services professionnels d’envergure internationale qui collabore avec ses clients afin d’élaborer des stratégies concrètes et des opérations d’optimisation, accélérer la transformation numérique et permettre aux entreprises et à leurs employés de prendre le contrôle de leur avenir.
« Nous donnons à nos ingénieurs les moyens de créer leurs pipelines de données et leurs applications avec Apache Spark via les langages Python et Scala. Nous recherchions une solution sur mesure simplifiant les opérations et optimisant le processus de livraison à nos clients. C’est ce que nous offre la nouvelle intégration Amazon Redshift pour Apache Spark. »
Alcuin Weidus, architecte de données principal - GE Aerospace
GE Aerospace est un fournisseur mondial de moteurs à réaction, de composants et de systèmes pour avions commerciaux et militaires. L'entreprise conçoit, développe et fabrique des moteurs à réaction depuis la Première Guerre mondiale.
« GE Aerospace utilise les analytiques AWS et Amazon Redshift pour obtenir des informations commerciales critiques sur lesquelles sont basées les décisions commerciales importantes. Grâce à la prise en charge de la copie automatique depuis Amazon S3, nous pouvons créer des pipelines de données plus simples pour déplacer les données d'Amazon S3 vers Amazon Redshift. Ainsi, nous optimisons la capacité de nos équipes de produits de données à accéder aux données et à fournir des informations aux utilisateurs finaux. Nous passons désormais plus de temps à ajouter de la valeur grâce aux données et moins de temps aux intégrations. »
Neema Raphael, directeur des données – Goldman Sachs
Le groupe Goldman Sachs Group, Inc. est une institution financière mondiale de premier plan qui offre une large gamme de services financiers dans les domaines de la banque d’investissement, des valeurs mobilières, de la gestion des investissements et des services bancaires aux particuliers à une clientèle large et diversifiée comprenant des entreprises, des institutions financières, des gouvernements et des particuliers.
« Notre objectif est de fournir un accès en libre-service aux données pour l'ensemble de nos utilisateurs chez Goldman Sachs. Grâce à Legend, notre plateforme open source de gestion et de gouvernance des données, nous permettons aux utilisateurs de développer des applications centrées sur les données et obtenir des informations basées sur les données tout au long de notre collaboration dans l'industrie des services financiers. Avec l'intégration d'Amazon Redshift pour Apache Spark, notre équipe de plateforme de données aura accès aux données Amazon Redshift avec un minimum d'étapes manuelles, ce qui permettra des processus ETL sans code et augmentera la capacité de nos ingénieurs à se concentrer plus facilement sur le perfectionnement de leur flux au fur et à mesure qu'ils collectent des informations complètes et pertinentes. Nous nous attendons à constater une amélioration des performances des applications et une sécurité améliorée, car nos utilisateurs peuvent désormais accéder facilement aux dernières données Amazon Redshift. »
Ressources
Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages