En quoi consiste un pipeline de données ?
En quoi consiste un pipeline de données ?
Un pipeline de données est une série d'étapes de traitement visant à préparer les données de l'entreprise pour l'analyse. Les organisations disposent d'un volume important de données provenant de diverses sources telles que des applications, des appareils Internet des objets (IoT) et d'autres canaux numériques. Cependant, les données brutes sont inutiles ; elles doivent être déplacées, triées, filtrées, reformatées et analysées pour l'informatique décisionnelle. Un pipeline de données comprend diverses technologies permettant de vérifier, de résumer et de trouver des modèles dans les données afin d'éclairer les décisions métier. Des pipelines de données bien organisés prennent en charge divers projets big data, tels que les visualisations de données, les analyses de données exploratoires et les tâches de machine learning.
Quels sont les avantages d'un pipeline de données ?
Les pipelines de données vous permettent d'intégrer des données provenant de différentes sources et de les transformer pour les analyser. Ils suppriment les silos de données et rendent vos analytiques de données plus fiables et plus précises. Voici quelques avantages clés d'un pipeline de données.
Qualité des données améliorée
Les pipelines de données nettoient et affinent les données brutes, améliorant ainsi leur utilité pour les utilisateurs finaux. Ils normalisent les formats des champs comme les dates et les numéros de téléphone tout en vérifiant les erreurs de saisie. Ils suppriment également les redondances et garantissent une qualité de données cohérente dans toute l'organisation.
Traitement efficace des données
Les ingénieurs de données doivent effectuer de nombreuses tâches répétitives lors de la transformation et du chargement des données. Les pipelines de données leur permettent d'automatiser les tâches de transformation des données et de se concentrer plutôt sur la recherche des meilleures informations métier. Les pipelines de données aident également les ingénieurs de données à traiter plus rapidement les données brutes qui perdent de leur valeur au fil du temps.
Intégration complète des données
Un pipeline de données permet d'abstraire les fonctions de transformation des données pour intégrer des ensembles de données provenant de sources hétérogènes. Il peut recouper les valeurs de données identiques provenant de plusieurs sources et corriger les incohérences. Par exemple, imaginez que le même client effectue un achat sur votre plateforme de commerce électronique et un autre sur votre service numérique. Cependant, il orthographie mal son nom dans le service numérique. Le pipeline peut corriger cette incohérence avant d'envoyer les données à des fins analytiques.
Comment fonctionne un pipeline de données ?
Tout comme un pipeline d'eau transporte l'eau du réservoir à vos robinets, un pipeline de données transporte les données du point de collecte au stockage. Un pipeline de données extrait des données d'une source, y apporte des modifications, puis les enregistre dans une destination spécifique. Nous expliquons ci-dessous les composants essentiels de l'architecture du pipeline de données.
Sources de données
Une source de données peut être une application, un appareil ou une autre base de données. Des sources hétérogènes peuvent pousser des données dans le pipeline. Le pipeline peut également extraire des points de données à l'aide d'un appel API, d'un webhook ou d'un processus de duplication des données. Vous pouvez synchroniser l'extraction des données pour un traitement en temps réel ou collecter des données à intervalles planifiés à partir de vos sources de données.
Transformations
À mesure que les données brutes circulent dans le pipeline, elles se transforment pour devenir plus utiles à l'informatique décisionnelle. Les transformations sont des opérations (telles que le tri, le reformatage, la déduplication, la vérification et la validation) qui modifient les données. Votre pipeline peut filtrer, résumer ou traiter les données pour répondre à vos besoins d'analyse.
Dépendances
Comme les changements se produisent de manière séquentielle, il peut exister des dépendances spécifiques qui réduisent la vitesse de déplacement des données dans le pipeline. Il existe deux principaux types de dépendances : techniques et métier. Par exemple, si le pipeline doit attendre qu'une file d'attente centrale se remplisse avant de poursuivre, il s'agit d'une dépendance technique. À l'inverse, si le pipeline doit faire une pause jusqu'à ce qu'une autre unité opérationnelle procède à une vérification croisée des données, il s'agit d'une dépendance métier.
Destinations
Le point de terminaison de votre pipeline de données peut être un entrepôt de données, un lac de données ou une autre application d'informatique décisionnelle ou d'analyse de données. Parfois, la destination est également appelée un puits de données.
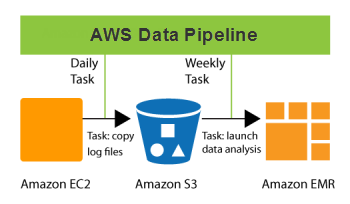
Quels sont les types de pipelines de données ?
Il existe deux principaux types de pipelines de données : les pipelines de traitement en continu et les pipelines de traitement par lots.
Pipelines de traitement des flux
Un flux de données est une séquence continue et incrémentielle de paquets de données de petite taille. Il représente généralement une série d'événements se produisant sur une période donnée. Par exemple, un flux de données pourrait montrer des données d'un capteur contenant les mesures de la dernière heure. Une action unique, comme une transaction financière, peut également être appelée événement. Les pipelines de streaming traitent une série d'événements pour l'analytique en temps réel.
Le streaming de données nécessitent une faible latence et une haute tolérance aux pannes. Votre pipeline de données doit être capable de traiter les données même si certains paquets de données sont perdus ou arrivent dans un ordre différent de celui prévu.
Pipelines de traitement par lots
Les pipelines de données à traitement par lots traitent et stockent les données en gros volumes ou par lots. Ils conviennent aux tâches occasionnelles de grand volume, comme la comptabilité mensuelle.
Le pipeline de données contient une série de commandes séquencées, et chaque commande est exécutée sur l'ensemble du lot de données. Le pipeline de données transmet la sortie d'une commande en tant qu'entrée de la commande suivante. Une fois toutes les transformations de données terminées, le pipeline charge l'ensemble du lot dans un entrepôt de données cloud ou un autre magasin de données similaire.
À propos du traitement par lots »
Différence entre les pipelines de données par lots et les pipelines de streaming de données
Les pipelines de traitement par lots fonctionnent peu fréquemment et généralement pendant les heures creuses. Ils nécessitent une puissance de calcul élevée pendant une courte période d'exécution. En revanche, les pipelines de traitement des flux fonctionnent en continu, mais nécessitent une faible puissance de calcul. Ils ont plutôt besoin de connexions réseau fiables et à faible latence.
Quelle est la différence entre les pipelines de données et les pipelines ETL ?
Un pipeline d'extraction, transformation et chargement (ETL) est un type particulier de pipeline de données. Les outils ETL extraient ou copient les données brutes de plusieurs sources et les stockent dans un emplacement temporaire appelé zone de transit. Ils transforment les données dans la zone de transit et les chargent dans des lacs de données ou des entrepôts.
Tous les pipelines de données ne suivent pas la séquence ETL. Certains peuvent extraire les données d'une source et les charger ailleurs sans transformations. D'autres pipelines de données suivent une séquence d'extraction, chargement et transformation (ELT), où ils extraient et chargent des données non structurées directement dans un lac de données. Ils effectuent des modifications après avoir déplacé les informations vers des entrepôts de données cloud.
Comment AWS peut-il prendre en charge vos besoins en matière de pipeline de données ?
AWS Glue est un service d'intégration de données sans serveur qui permet aux utilisateurs d'analyses de découvrir, de préparer, de déplacer et d'intégrer plus facilement des données provenant de sources multiples à des fins d'analyse, d'apprentissage automatique et de développement d'applications.
- Vous pouvez découvrir et vous connecter à plus de 80 magasins de données différents.
- Vous pouvez gérer vos données dans un catalogue de données centralisé.
- Les ingénieurs de données, les développeurs ETL, les analystes de données et les utilisateurs professionnels peuvent utiliser AWS Glue Studio pour créer, exécuter et surveiller des pipelines ETL afin de charger des données dans des lacs de données.
- AWS Glue Studio propose des interfaces Visual ETL, Notebook et éditeur de code, afin que les utilisateurs disposent d'outils adaptés à leurs compétences.
- Avec Interactive Sessions, les ingénieurs des données peuvent explorer les données ainsi que créer et tester des tâches à l'aide de leur IDE ou bloc-notes préféré.
- AWS Glue est sans serveur et évolue automatiquement à la demande. Vous pouvez donc vous concentrer sur l'exploitation des données à l'échelle du pétaoctet sans avoir à gérer l'infrastructure.
Commencez à utiliser AWS Glue en créant un compte AWS.
Prochaines étapes du pipeline de données
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages