Que sont les intégrations en machine learning ?
Que sont les intégrations en machine learning ?
Les intégrations sont des représentations numériques d'objets du monde réel que les systèmes d'apprentissage automatique (ML) et d'intelligence artificielle (IA) utilisent pour comprendre des domaines de connaissances complexes, comme le font les humains. À titre d’exemple, les algorithmes informatiques comprennent que la différence entre 2 et 3 est égale à 1, ce qui indique une relation étroite entre 2 et 3 par rapport à 2 et 100. Cependant, les données du monde réel incluent des relations plus complexes. Par exemple, un nid d’oiseau et une tanière à lions sont des couples analogues, tandis que les termes jour-nuit sont opposés. Les intégrations convertissent les objets du monde réel en représentations mathématiques complexes qui capturent les propriétés inhérentes et les relations entre les données du monde réel. L’ensemble du processus est automatisé, les systèmes d’IA créant eux-mêmes des intégrations pendant l’entraînement et les utilisant selon les besoins pour effectuer de nouvelles tâches.
Pourquoi les intégrations sont-elles importantes ?
Les intégrations permettent aux modèles de deep learning de comprendre plus efficacement les domaines de données du monde réel. Ils simplifient la façon dont les données du monde réel sont représentées tout en préservant les relations sémantiques et syntaxiques. Cela permet aux algorithmes de machine learning d’extraire et de traiter des types de données complexes et de permettre des applications d’IA innovantes. Les sections suivantes décrivent certains facteurs importants.
Réduction de la dimensionnalité des données
Les scientifiques des données utilisent des intégrations pour représenter des données de grande dimension dans un espace de faible dimension. En science des données, le terme dimension fait généralement référence à une caractéristique ou à un attribut des données. Les données de plus grande dimension dans l’IA font référence à des jeux de données comportant de nombreuses caractéristiques ou attributs qui définissent chaque point de données. Cela peut signifier des dizaines, des centaines, voire des milliers de dimensions. Par exemple, une image peut être considérée comme une donnée de grande dimension, car chaque valeur de couleur de pixel est une dimension distincte.
Lorsqu’ils sont présentés avec des données de grande dimension, les modèles de deep learning nécessitent plus de puissance de calcul et de temps pour apprendre, analyser et déduire avec précision. Les intégrations réduisent le nombre de dimensions en identifiant les points communs et les modèles entre les différentes fonctionnalités. Cela réduit par conséquent les ressources informatiques et le temps nécessaires au traitement des données brutes.
Entraînement de grands modèles de langage
Les intégrations améliorent la qualité des données lors de la formation de grands modèles linguistiques (LLM). Par exemple, les scientifiques des données utilisent des intégrations pour éliminer les irrégularités affectant l’apprentissage des modèles dans les données d’entraînement. Les ingénieurs ML peuvent également réutiliser des modèles préformés en ajoutant de nouvelles intégrations pour l’apprentissage par transfert, ce qui nécessite d’affiner le modèle de base avec de nouveaux jeux de données. Grâce aux intégrations, les ingénieurs peuvent affiner un modèle pour des jeux de données personnalisés issus du monde réel.
Création d’applications innovantes
Les intégrations permettent de nouvelles applications d'apprentissage profond et d'intelligence artificielle générative (IA générative). Différentes techniques d’intégration appliquées à l’architecture des réseaux neuronaux permettent de développer, d’entraîner et de déployer des modèles d’IA précis dans divers domaines et applications. Par exemple :
- Grâce à l’intégration d’images, les ingénieurs peuvent créer des applications de vision par ordinateur de haute précision pour la détection d’objets, la reconnaissance d’images et d’autres tâches liées à la vision.
- Grâce à l’intégration de mots, les logiciels de traitement du langage naturel peuvent mieux comprendre le contexte et les relations entre les mots.
- Les intégrations de graphes extraient et catégorisent les informations connexes des nœuds interconnectés pour faciliter l’analyse du réseau.
Les modèles de vision par ordinateur, les chatbots d'IA et les systèmes de recommandation d'IA utilisent tous des intégrations pour effectuer des tâches complexes qui imitent l'intelligence humaine.
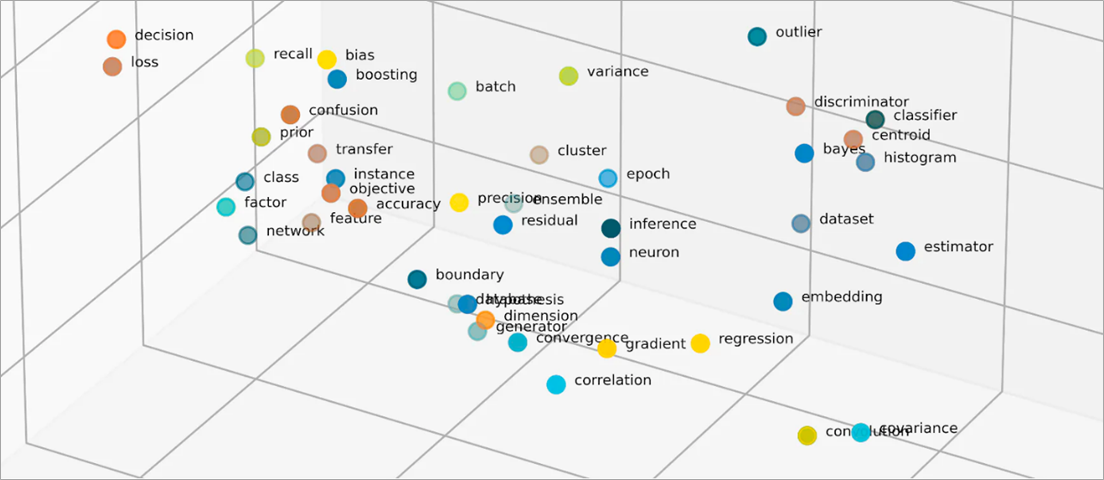
Que sont les vecteurs dans les intégrations ?
Les modèles ML ne peuvent pas interpréter les informations de manière intelligible dans leur format brut et nécessitent des données numériques en entrée. Ils utilisent des intégrations de réseaux neuronaux pour convertir des informations réelles en représentations numériques appelées vecteurs. Les vecteurs sont des valeurs numériques qui représentent des informations dans un espace multidimensionnel. Ils aident les modèles ML à trouver des similitudes entre des éléments peu distribués.
Chaque objet à partir duquel un modèle ML apprend possède des caractéristiques ou des fonctionnalités différentes. À titre d’exemple simple, considérez les films et émissions de télévision suivants. Chacun est caractérisé par le genre, le type et l’année de sortie.
The Conference (Horreur, 2023, Film)
Upload (Comédie, 2023, série télévisée, saison 3)
Tales from the Crypt (Horreur, 1989, série télévisée, saison 7)
Dream Scenario (Comédie d’horreur, 2023, Film)
Les modèles ML peuvent interpréter des variables numériques telles que les années, mais ne peuvent pas comparer des variables non numériques telles que le genre, les types, les épisodes et le total des saisons. L’intégration de vecteurs permet de coder des données non numériques dans une série de valeurs que les modèles ML peuvent comprendre et relier. Par exemple, ce qui suit est une représentation hypothétique des programmes télévisés répertoriés précédemment.
The Conference (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
Tales from the Crypt (1.2, 1989, 36.7)
Dream Scenario (1.8, 2023, 20.0)
Le premier chiffre du vecteur correspond à un genre spécifique. Un modèle ML constaterait que The Conference et Tales from the Crypt partagent le même genre. De même, le modèle trouvera davantage de relations entre Upload et Tales from the Crypt sur la base du troisième chiffre, représentant le format, les saisons et les épisodes. Au fur et à mesure que de nouvelles variables sont introduites, vous pouvez affiner le modèle pour condenser davantage d’informations dans un espace vectoriel plus petit.
Comment fonctionnent les intégrations ?
Les intégrations convertissent les données brutes en valeurs continues que les modèles ML peuvent interpréter. Conventionnellement, les modèles ML utilisent un encodage à chaud pour mapper les variables catégorielles sous des formes à partir desquelles ils peuvent apprendre. La méthode de codage divise chaque catégorie en lignes et en colonnes et leur attribue des valeurs binaires. Prenez pour exemple les catégories de produits suivantes et leur prix.
|
Fruits |
Tarification |
|
Apple |
5.00 |
|
Orange |
7.00 |
|
Carotte |
10.00 |
La représentation des valeurs à l’aide d’un encodage à chaud donne les résultats du tableau suivant.
|
Apple |
Orange |
Poire |
Tarification |
|
1 |
0 |
0 |
5.00 |
|
0 |
1 |
0 |
7.00 |
|
0 |
0 |
1 |
10.00 |
Le tableau est représenté mathématiquement sous forme de vecteurs [1,0,0,5.00], [0,1,0,7.00] et [0,0,1,10.00].
L’encodage à chaud étend les valeurs dimensionnelles de 0 et 1 sans fournir d’informations permettant aux modèles de relier les différents objets. Par exemple, le modèle ne peut pas trouver de similarités entre la pomme et l’orange bien qu’il s’agisse de fruits, pas plus qu’il ne peut différencier l’orange et la carotte en tant que fruits et légumes. Au fur et à mesure que de nouvelles catégories sont ajoutées à la liste, l’encodage génère des variables peu distribuées avec de nombreuses valeurs vides qui consomment un espace mémoire énorme.
Les intégrations vectorisent des objets dans un espace de faible dimension en représentant les similitudes entre les objets avec des valeurs numériques. Les intégrations de réseaux neuronaux garantissent que le nombre de dimensions reste gérable grâce à l’extension des fonctionnalités d’entrée. Les caractéristiques d’entrée sont des caractéristiques d’objets spécifiques qu’un algorithme de ML est chargé d’analyser. La réduction de dimensionnalité permet aux intégrations de conserver les informations que les modèles ML utilisent pour trouver des similitudes et des différences par rapport aux données d’entrée. Les scientifiques des données peuvent également visualiser les intégrations dans un espace bidimensionnel afin de mieux comprendre les relations entre les objets distribués.
Que sont les modèles d’intégration ?
Les modèles d’intégration sont des algorithmes entraînés pour encapsuler des informations dans des représentations denses dans un espace multidimensionnel. Les scientifiques des données utilisent des modèles d’intégration pour permettre aux modèles ML de comprendre et de raisonner avec des données de grande dimension. Il s’agit de modèles d’intégration courants utilisés dans les applications de ML.
Analyse en composantes principales
L’analyse en composantes principales (PCA) est une technique de réduction de la dimensionnalité qui réduit les types de données complexes en vecteurs de faible dimension. Elle trouve les points de données présentant des similitudes et les compresse en vecteurs d’intégration qui reflètent les données d’origine. Bien que la PCA permette aux modèles de traiter les données brutes plus efficacement, des pertes d’informations peuvent survenir pendant le traitement.
Décomposition en valeurs singulières
La décomposition en valeurs singulières (SVD) est un modèle d’intégration qui transforme une matrice en ses matrices singulières. Les matrices résultantes conservent les informations d’origine tout en permettant aux modèles de mieux comprendre les relations sémantiques des données qu’elles représentent. Les scientifiques des données utilisent la SVD pour effectuer diverses tâches de ML, notamment la compression d’images, la classification de texte et la recommandation.
Word2Vec
Word2Vec est un algorithme de ML entraîné pour associer des mots et les représenter dans l’espace d’intégration. Les scientifiques des données alimentent le modèle Word2Vec avec d’énormes jeux de données textuelles pour permettre la compréhension du langage naturel. Le modèle trouve des similitudes entre les mots en tenant compte de leur contexte et de leurs relations sémantiques.
Il existe deux variantes de Word2Vec : Continuous Bag of Words (CBOW) et Skip-gram. CBOW permet au modèle de prédire un mot à partir d’un contexte donné, tandis que Skip-gram déduit le contexte à partir d’un mot donné. Bien que Word2Vec soit une technique d’intégration de mots efficace, elle ne permet pas de distinguer avec précision les différences contextuelles d’un même mot utilisé pour impliquer des significations différentes.
BERT
BERT est un modèle de langage basé sur des transformateurs formé à l’aide d’énormes jeux de données pour comprendre les langues comme le font les humains. Comme Word2Vec, BERT peut créer des intégrations de mots à partir des données d’entrée avec lesquelles il a été entraîné. De plus, BERT peut différencier les significations contextuelles des mots lorsqu’ils sont appliqués à différentes phrases. Par exemple, BERT crée différentes intégrations pour « play », comme dans « I went to a play » et « I like to play. »
Comment sont créées les intégrations ?
Les ingénieurs utilisent des réseaux de neurones pour créer des intégrations. Les réseaux neuronaux sont constitués de couches neuronales cachées qui prennent des décisions complexes de manière itérative. Lors de la création d’intégrations, l’une des couches cachées apprend à factoriser les entités en entrée en vecteurs. Cela se produit avant les couches de traitement des entités. Ce processus est supervisé et guidé par des ingénieurs selon les étapes suivantes :
- Les ingénieurs alimentent le réseau neuronal avec des échantillons vectorisés préparés manuellement.
- Le réseau neuronal apprend à partir des modèles découverts dans l’échantillon et utilise ces connaissances pour faire des prédictions précises à partir de données invisibles.
- Parfois, les ingénieurs peuvent avoir besoin d’affiner le modèle pour s’assurer qu’il distribue les caractéristiques d’entrée dans l’espace dimensionnel approprié.
- Au fil du temps, les intégrations fonctionnent indépendamment, ce qui permet aux modèles ML de générer des recommandations à partir des représentations vectorisées.
- Les ingénieurs continuent de surveiller les performances de l’intégration et de l’affiner à l’aide de nouvelles données.
Comment AWS peut-il vous aider à répondre à vos exigences en matière d’intégration ?
Amazon Bedrock est un service entièrement géré qui propose un choix de modèles de base (FM) performants issus de grandes sociétés d'IA, ainsi qu'un large éventail de fonctionnalités permettant de créer des applications d'intelligence artificielle générative (IA générative). Amazon Nova est une nouvelle génération de modèles de base (FM) de pointe (SOTA) qui fournissent des informations de pointe et des rapports prix/performances inégalés sur le marché. Il s’agit de modèles puissants à usage général conçus pour prendre en charge divers cas d’utilisation. Utilisez-les tels quels ou personnalisez-les avec vos propres données.
Titan Embeddings est un LLM qui traduit le texte en une représentation numérique. Le modèle Titan Embeddings prend en charge la récupération de texte, la similarité sémantique et le clustering. Le texte d’entrée maximal est de 8 000 jetons et la longueur maximale du vecteur de sortie est de 1 536.
Les équipes de machine learning peuvent également utiliser Amazon SageMaker pour créer des intégrations. Amazon SageMaker est une plateforme qui vous permet de créer, de former et de déployer des modèles ML dans un environnement sécurisé et évolutif. Il fournit une technique d’intégration appelée Object2Vec, grâce à laquelle les ingénieurs peuvent vectoriser des données de haute dimension dans un espace de faible dimension. Vous pouvez utiliser les intégrations apprises pour calculer les relations entre les objets pour des tâches en aval telles que les classifications et la régression.
Commencez à utiliser les intégrations sur AWS en créant un compte dès aujourd'hui.
Prochaines étapes sur AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages