Artificial Intelligence
Building a customized recommender system in Amazon SageMaker
Recommender systems help you tailor customer experiences on online platforms. Amazon Personalize is an artificial intelligence and machine learning service that specializes in developing recommender system solutions. It automatically examines the data, performs feature and algorithm selection, optimizes the model based on your data, and deploys and hosts the model for real-time recommendation inference. However, if you need to access trained models’ weights, you may need to build your recommender system from scratch. In this post, I show you how to train and deploy a customized recommender system in TensorFlow 2.0, using a Neural Collaborative Filtering (NCF) (He et al., 2017) model on Amazon SageMaker.
Understanding Neural Collaborative Filtering
A recommender system is a set of tools that helps provide users with a personalized experience by predicting user preference amongst a large number of options. Matrix factorization (MF) is a well-known approach to solving such a problem. Conventional MF solutions exploit explicit feedback in a linear fashion; explicit feedback consists of direct user preferences, such as ratings for movies on a five-star scale or binary preference on a product (like or not like). However, explicit feedback isn’t always present in datasets. NCF solves the absence of explicit feedback by only using implicit feedback, which is derived from user activity, such as clicks and views. In addition, NCF utilizes multi-layer perceptron to introduce non-linearity into the solution.
Architecture overview
An NCF model contains two intrinsic sets of network layers: embedding and NCF layers. You use these layers to build a neural matrix factorization solution with two separate network architectures, generalized matrix factorization (GMF) and multi-layer perceptron (MLP), whose outputs are then concatenated as input for the final output layer. The following diagram from the original paper illustrates this architecture.
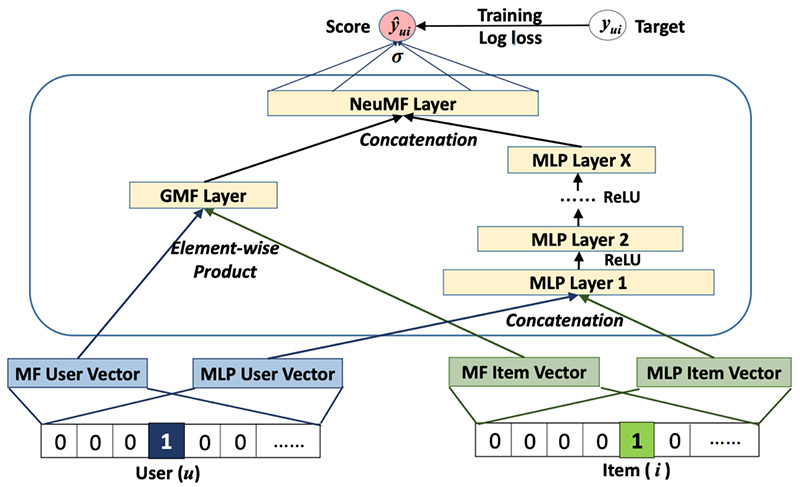
In this post, I walk you through building and deploying the NCF solution using the following steps:
- Prepare data for model training and testing.
- Code the NCF network in TensorFlow 2.0.
- Perform model training using Script Mode and deploy the trained model using Amazon SageMaker hosting services as an endpoint.
- Make a recommendation inference via the model endpoint.
You can find the complete code sample in the GitHub repo. You can also launch this solution in your Amazon SageMaker Studio via Amazon SageMaker JumpStart using the button below.
Open the console to get started.
Preparing the data
For this post, I use the MovieLens dataset. MovieLens is a movie rating dataset provided by GroupLens, a research lab at the University of Minnesota.
First, I run the following code to download the dataset into the ml-latest-small directory:
I only use rating.csv, which contains explicit feedback data, as a proxy dataset to demonstrate the NCF solution. To fit this solution to your data, you need to determine the meaning of a user liking an item.
To perform a training and testing split, I take the latest 10 items each user rated as the testing set and keep the rest as the training set:
Because we’re performing a binary classification task and treating the positive label as if the user liked an item, we need to randomly sample the movies each user hasn’t rated and treat them as negative labels. This is called negative sampling. The following function implements the process:
You can use the following code to perform the training and testing splits, negative sampling, and store the processed data in Amazon Simple Storage Service (Amazon S3):
I use the Amazon SageMaker session’s default bucket to store processed data. The format of the default bucket name is sagemaker-{region}–{aws-account-id}.
Coding the NCF network
In this section, I implement GMF and MLP separately. These two components’ input are both user and item embeddings. To define the embedding layers, we enter the following code:
To implement GMF, we multiply the user and item embeddings:
The authors of Neural Collaborative Filtering show that a four-layer MLP with 64-dimensional user and item latent factor performed the best across different experiments, so we implement this structure as our MLP:
Lastly, to produce the final prediction, we concatenate the output of GMF and MLP as the following:
To build the entire solution in one step, we create a graph building function:
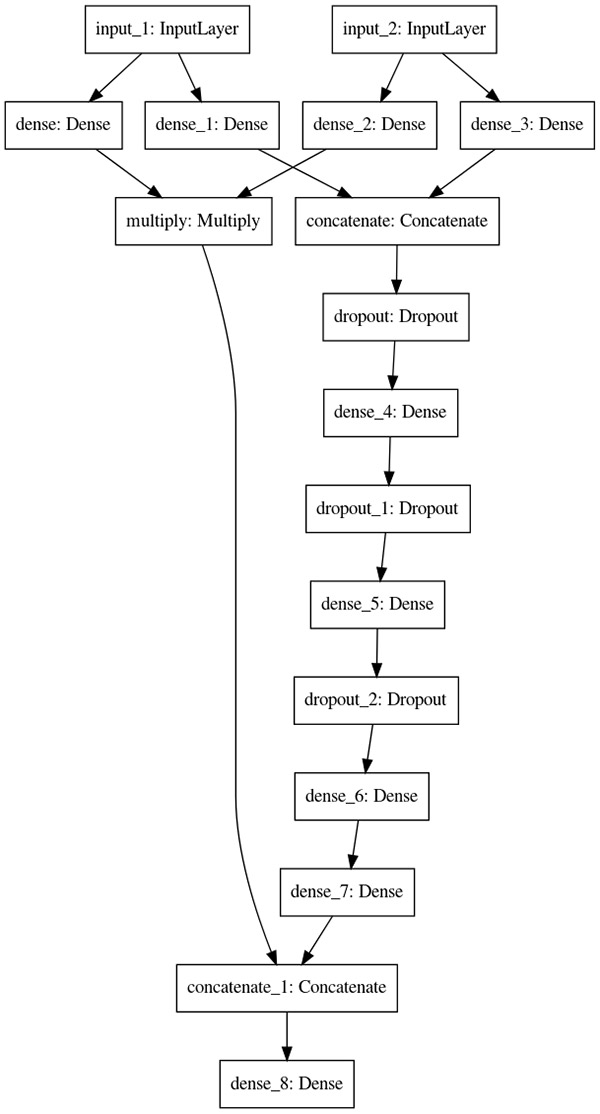
I use the Keras plot_model utility to verify the network architecture I just built is correct:
The output architecture should look like the following diagram.
Training and deploying the model
For instructions on deploying a model you trained using an instance on Amazon SageMaker, see Deploy trained Keras or TensorFlow models using Amazon SageMaker. For this post, I deploy this model using Script Mode.
We first need to create a Python script that contains the model training code. I compiled the model architecture code presented previously and added additional code required in the ncf.py, which you can use directly. I also implemented a function for you to load training data; to load testing data, the function is the same except the file name is changed to reflect the testing data destination. See the following code:
After downloading the training script and storing it in the same directory as the model training notebook, we can initialize a TensorFlow estimator with the following code:
We fit the estimator to our training data to start the training job:
When you see the output in the following screenshot, your model training job has started.
When the model training process is complete, we can deploy the model as an endpoint. See the following code:
Performing model inference
To make inference using the endpoint on the testing set, we can invoke the model in the same way by using TensorFlow Serving:
The model output is a set of probabilities, ranging from 0 to 1, for each user-item pair that we specify for inference. To make final binary predictions, such as like or not like, we need to apply a threshold. For demonstration purposes, I use 0.5 as a threshold; if the predicted probability is equal or greater than 0.5, we say the model predicts the user will like the item, and vice versa.
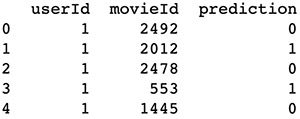
Finally, we can get a list of model predictions on whether a user will like a movie, as shown in the following screenshot.
Conclusion
Designing a recommender system can be a challenging task that sometimes requires model customization. In this post, I showed you how to implement, deploy, and invoke an NCF model from scratch in Amazon SageMaker. This work can serve as a foundation for you to start building more customized solutions with your own datasets.
For more information about using built-in Amazon SageMaker algorithms and Amazon Personalize to build recommender system solutions, see the following:
- Omnichannel personalization with Amazon Personalize
- Creating a recommendation engine using Amazon Personalize
- Extending Amazon SageMaker factorization machines algorithms to predict top x recommendations
- Build a movie recommender with factorization machines on Amazon SageMaker
To further customize the Neural Collaborative Filtering network, Deep Matrix Factorization (Xue et al., 2017) model can be an option.
About the Authors
 Ray Li is a Sr. Data Scientist with AWS Professional Services. His specialty focuses on building and operationalizing AI/ML solutions for customers of varying sizes, ranging from startups to enterprise organizations. Outside of work, Ray enjoys fitness and traveling.
Ray Li is a Sr. Data Scientist with AWS Professional Services. His specialty focuses on building and operationalizing AI/ML solutions for customers of varying sizes, ranging from startups to enterprise organizations. Outside of work, Ray enjoys fitness and traveling.
 Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS cloud. His passion extends to his proclivity for travel and diverse cultural experiences.
Nick Biso is a Machine Learning Engineer at AWS Professional Services. He solves complex organizational and technical challenges using data science and engineering. In addition, he builds and deploys AI/ML models on the AWS cloud. His passion extends to his proclivity for travel and diverse cultural experiences.