Guida all’integrazione e all’analisi dei dati multi-omici e multi-modali in AWS
Panoramica
Come funziona
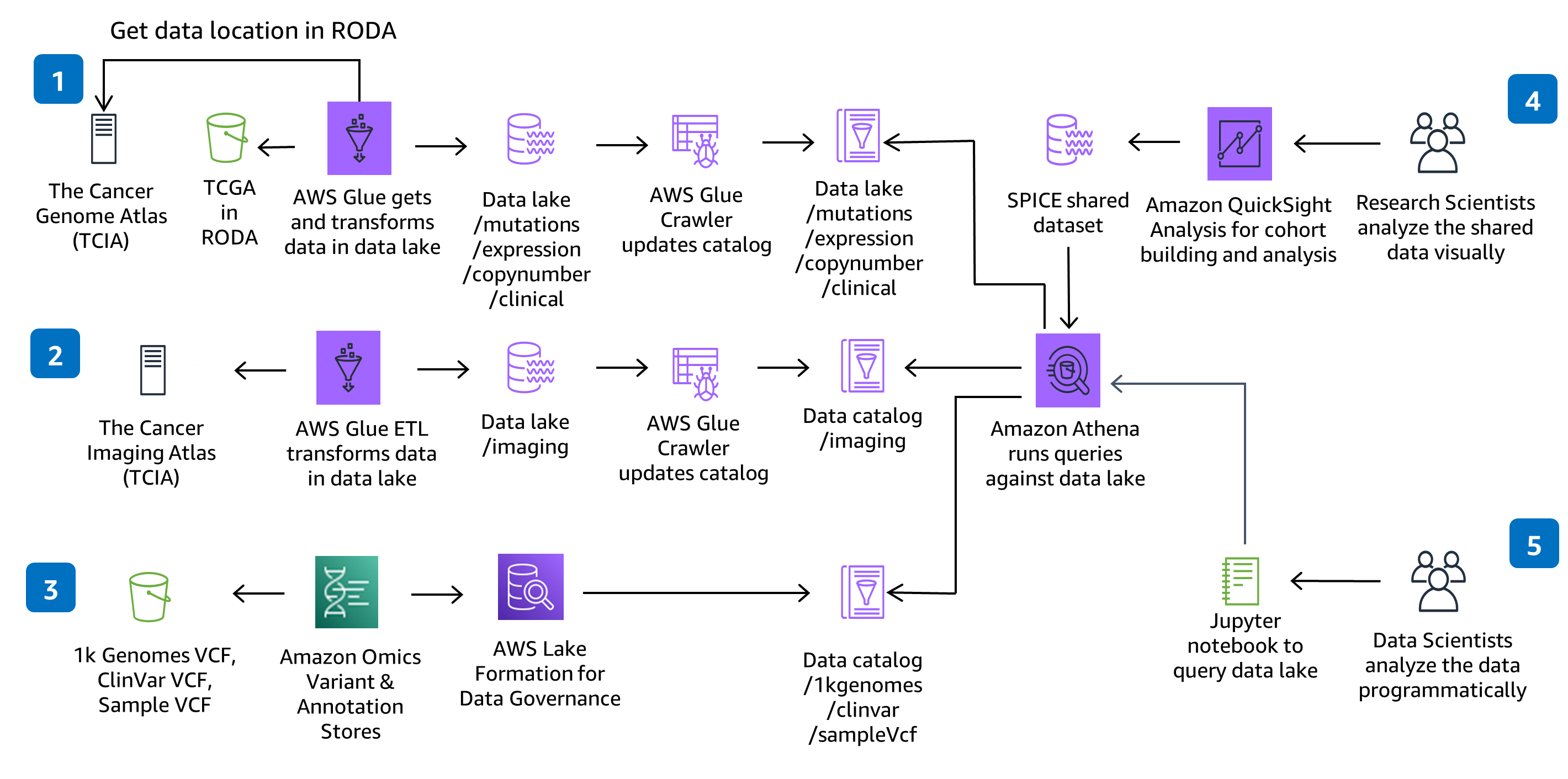
Architettura
Prepara dati genomici, clinici, di mutazione, di espressione e di imaging per un’analisi su larga scala ed esegui query su un data lake.
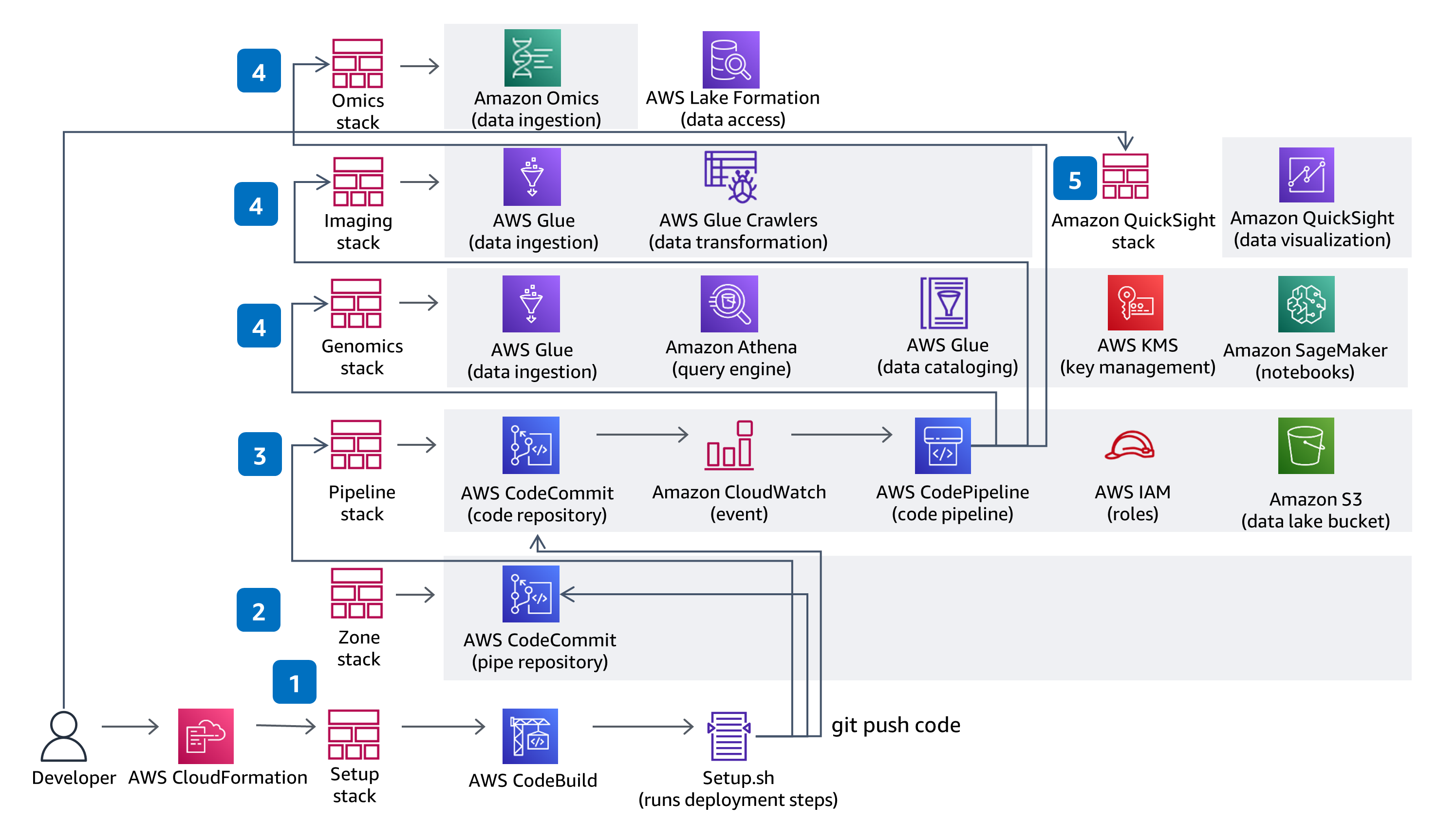
Integrazione e distribuzione continue (CI/CD)
Prepara dati genomici, clinici, di mutazione, di espressione e di imaging per un’analisi su larga scala ed esegui query su un data lake.
Principi Well-Architected
Il diagramma dell'architettura sopra riportato è un esempio di una soluzione creata tenendo conto delle best practice Well-Architected. Per essere completamente Well-Architected, devi seguire il maggior numero possibile di best practice Well-Architected.
Questa guida utilizza CodeBuild e CodePipeline per sviluppare, creare pacchetti e distribuire tutto ciò che è necessario nella soluzione per importare e archiviare i file VCF (Variant Call File) e lavorare con dati multi-modali e multi-omici dai set di dati di The Cancer Genome Atlas (TCGA) e The Cancer Imaging Atlas (TCIA). L’acquisizione e l’analisi dei dati genomici serverless vengono dimostrate utilizzando un servizio completamente gestito, Amazon Omics. Le modifiche al codice apportate nel repository CodeCommit della soluzione saranno implementate attraverso la pipeline di distribuzione CodePipeline fornita.
Questa Guida utilizza gli accessi basati su ruoli con IAM e la crittografia è abilitata su tutti i bucket, che sono privati e dispongono del blocco degli accessi pubblici. La crittografia è abilitata sul catalogo dati in AWS Glue e tutti i metadati scritti da AWS Glue su Amazon S3 sono crittografati. Tutti i ruoli sono caratterizzati da privilegio minimo e tutte le comunicazioni tra i servizi rientrano nell’account cliente. Gli amministratori possono controllare il notebook Jupyter, l’accesso ai dati degli archivi di varianti di Amazon Omics e del catalogo dati AWS Glue è gestito completamente tramite Lake Formation e l’accesso ai dati di Athena, del notebook SageMaker e di QuickSight è gestito tramite i ruoli IAM forniti.
AWS Glue, Amazon S3, Amazon Omics e Athena sono serverless e scalano le prestazioni di accesso ai dati man mano che aumenta il loro volume. AWS Glue effettua il provisioning, configura e scala le risorse necessarie per eseguire le attività di integrazione dei dati. Athena è serverless, pertanto è possibile eseguire rapidamente query sui dati senza configurare e gestire server o data warehouse. L'archiviazione in memoria di QuickSight SPICE scala l’esplorazione dei dati a migliaia di utenti.
Grazie a tecnologie serverless, eseguirai il provisioning soltanto delle risorse utilizzate. Ogni processo AWS Glue eseguirà il provisioning di un cluster Spark on demand per trasformare i dati e annullerà il provisioning delle risorse al termine del processo. Se si decide di aggiungere nuovi set di dati TCGA, sarà possibile aggiungere anche nuovi processi AWS Glue e crawler AWS Glue che eseguiranno il provisioning delle risorse on demand. Athena esegue automaticamente query in parallelo; in questo modo, la maggior parte dei risultati viene restituita entro pochi secondi. Amazon Omics ottimizza le prestazioni delle query di varianti su larga scala trasformando i file in Apache Parquet.
Grazie all’utilizzo di tecnologie serverless che scalano le risorse on demand, pagherai soltanto le risorse utilizzate. Per ottimizzare ulteriormente i costi, puoi interrompere gli ambienti notebook in SageMaker quando non sono in uso. Anche la dashboard QuickSight viene distribuita tramite un modello di CloudFormation separato. In questo modo, se non desideri utilizzare la dashboard di visualizzazione, puoi decidere di non distribuirla e ridurre i costi. Amazon Omics ottimizza i costi di archiviazione di dati delle varianti su larga scala. I costi delle query sono determinati dalla quantità di dati scansionati da Athena e possono essere ottimizzati scrivendo query di conseguenza.
Tramite un ampio utilizzo dei servizi gestiti e della scalabilità dinamica, potrai ridurre al minimo l’impatto ambientale dei servizi di backend. Un fattore fondamentale per la sostenibilità è massimizzare l’uso delle istanze del server notebook. Quando non sono in uso, devi interrompere gli ambienti notebook.
Ulteriori considerazioni
Trasformazione dei dati
Questa architettura sceglie AWS Glue per i processi di estrazione, trasformazione e caricamento (ETL) necessari per acquisire, preparare e catalogare i set di dati nell’ambito delle soluzioni per le query e le prestazioni. Puoi aggiungere nuovi processi AWS Glue e crawler AWS Glue per importare nuovi set di dati di The Cancer Genome Atlas (TCGA) e The Cancer Image Atlas (TCIA), a seconda delle necessità. Puoi aggiungere anche nuovi processi e crawler per importare, preparare e catalogare i set di dati.
Analisi dei dati
Questa architettura ha scelto i notebook SageMaker per fornire un ambiente notebook Jupyter per l’analisi. Puoi aggiungere nuovi notebook all'ambiente esistente o crearne dei nuovi. Se preferisci RStudio ai notebook Jupyter, puoi utilizzare RStudio su Amazon SageMaker.
Visualizzazione di dati
Questa architettura ha scelto QuickSight per fornire dasboard interattive per la visualizzazione e l’esplorazione dei dati. La configurazione della dashboard QuickSight avviene tramite un modello separato di CloudFormation. In questo modo, se non desideri utilizzare la dashboard, non dovrai eseguire il provisioning. In QuickSight puoi eseguire analisi personalizzate, esplorare filtri o visualizzazioni aggiuntivi e condividere set di dati e analisi con i colleghi.
Distribuzione sicura
Questo repository crea un ambiente scalabile in AWS per preparare dati genomici, clinici, di mutazione, di espressione e di diagnostica per immagini per un’analisi su larga scala e per eseguire query interattive in un data lake. Questa soluzione mostra come 1) utilizzare l’archivio di varianti e l’archivio di annotazioni di HealthOmics per archiviare dati di varianti e di annotazione genomica, 2) eseguire il provisioning di pipeline serverless di acquisizione dei dati per la preparazione e la catalogazione di dati multi-modali, 3) visualizzare ed esplorare dati clinici tramite un’interfaccia interattiva e 4) eseguire query analitiche interattive in un data lake multi-modale tramite Amazon Athena e Amazon SageMaker.
Viene fornita una guida dettagliata da sperimentare e utilizzare all’interno del tuo account AWS. Ogni fase della creazione della guida, inclusa la distribuzione, l’utilizzo e la pulizia, viene esaminata per prepararla alla distribuzione.
Apri la guida all’implementazione
Il codice di esempio è un punto di partenza. È convalidato dal settore, prescrittivo ma non definitivo, ed è il punto di partenza per iniziare a lavorare.
Contenuti correlati
Guida
Guida per l’analisi multi-modale dei dati con servizi di IA e ML per la salute su AWS
Questa Guida illustra come impostare un framework end-to-end per analizzare i dati multimodali relativi all’assistenza sanitaria e alle scienze della vita (HCLS).
Collaboratori
Avvertenza
Hai trovato quello che cercavi?
Facci sapere la tua opinione in modo da migliorare la qualità dei contenuti delle nostre pagine