Amazon Web Services ブログ
SAP 対応エージェンティック AI アシスタントを AWS の生成 AI サービスで実現
はじめに
SAPシステムは多くの企業のバックボーンであり、重要なビジネスプロセスを管理し、膨大な量の貴重なデータを生成しています。これらの重要なビジネスプロセスとデータは通常、エンタープライズSAPシステムを超えて拡張され、顧客は外部システムとも相互作用する必要があります。組織がより深い洞察と改善された意思決定のためにこのデータを活用しようとする中で、SAP顧客がデータやシステムとどのように相互作用するかを変革する必要性が高まっています。
Generative AIの自然言語処理(NLP)機能は、SAP ユーザーに自然言語クエリを使用して複雑なERPシステムと相互作用する強力なツールを提供し、専門的な技術知識や複雑なSQLクエリの必要性を排除します。これにより組織全体でのデータアクセスが民主化され、ビジネスユーザーが会話型インターフェースを使用してリアルタイムで質問し、レポートを生成し、洞察を得ることができるようになります。
Generative AIをSAPシステムと統合することで、組織は構造化されたERPデータと様々なSAPおよび非SAPソースからの非構造化情報との間のギャップを埋めることができ、ビジネス環境のより包括的な視点を提供します。この統合により、より正確な予測、パーソナライズされた顧客体験、そして企業エコシステム全体にわたるデータ駆動型の意思決定が可能になります。
AWSとSAPは、最先端の生成AIサービス、堅牢なインフラストラクチャ、豊富な実装リソースの包括的なスイートで、Generative AI導入ジャーニーのあらゆる段階で顧客を支援します。これらの提供物はSAPシステムと統合でき、AWSとSAPの広大なクラウドサービスエコシステムを補完します。
このブログ(2部構成シリーズのパート1)では、Amazon Bedrockと他のAWSサービスを活用して、MS Teams、Slack、Streamlitユーザーインターフェースを通じて統一されたビューで人間の自然言語でSAPおよび非SAPデータソースから洞察を得る方法について説明し、図解します。
このブログシリーズのパート2では、SAP BTPサービス(SAP Build Apps、SAP Generative AI Hub)を活用して、SAP Build Appsユーザーインターフェースで統一されたビューで人間の自然言語でSAPおよび非SAPシステムから洞察を得る方法について説明し、図解します。
概要
まず、SAPシステムからデータを抽出するために必要なビジネスロジックを開発します。Bedrock Knowledge BasesとAWS Secrets Managerを含む様々なAWSサービスによってサポートされる、ビジネスロジックを実行する2つのAWS Lambda関数を作成します。次に、追加の非SAPデータソースからデータを処理するビジネスロジックの作成に焦点を当て、物流情報を含むAmazon DynamoDBからデータを抽出するために特別に設計された別のlambda関数を実装します。システムの機能を強化するために、一般的なユーザークエリを促進する第3のデータソースとして機能するナレッジベースを確立します。その後、ユーザークエリに基づいてこれらの異なるデータソース間のフローを調整する責任を持つAmazon Bedrock Agentsを実装します。最終段階では、Streamlitを使用してユーザーインターフェースを作成し、アクセシビリティを向上させるためにMS TeamsとSlackとの代替統合オプションも提供します。
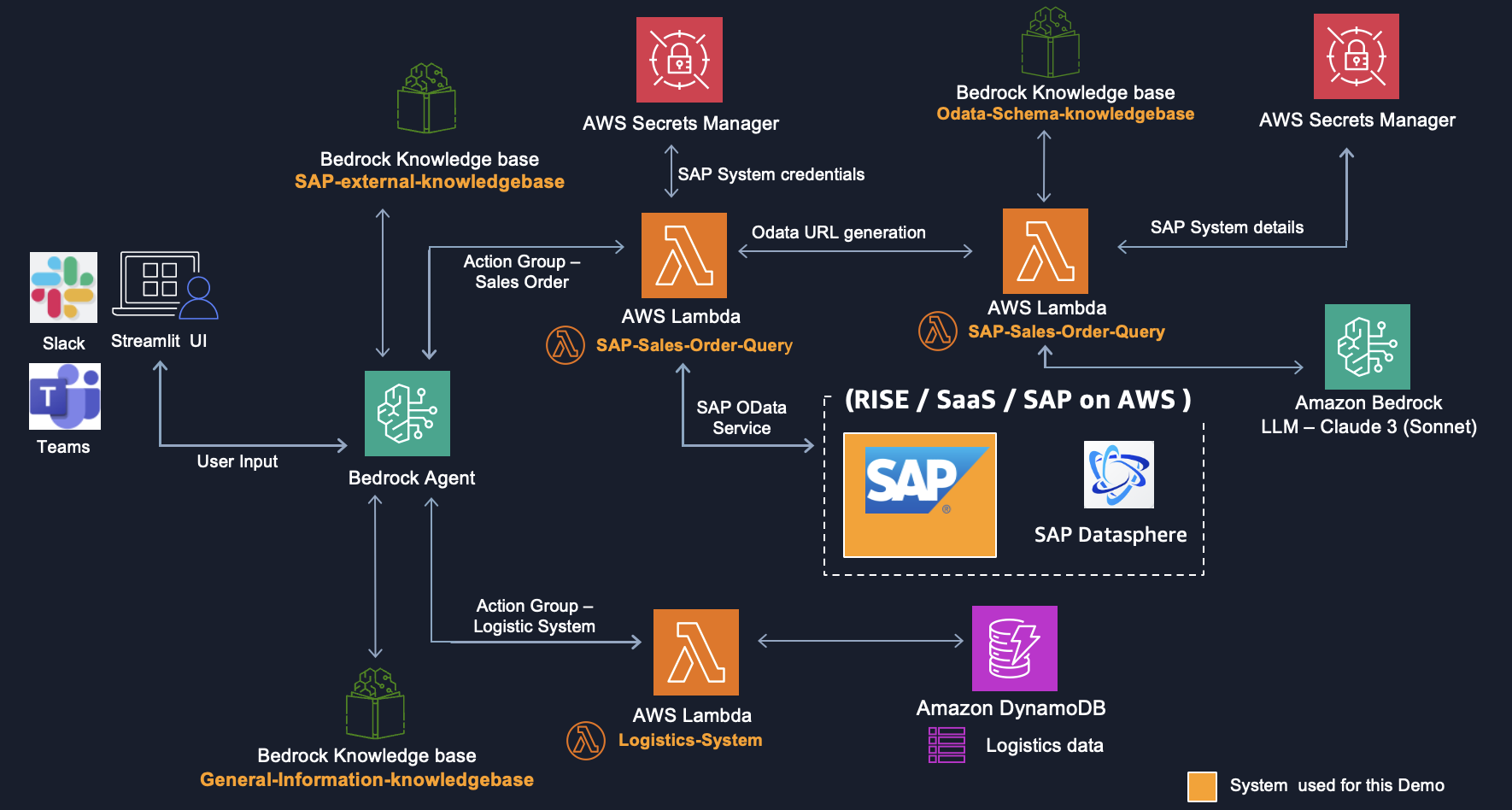
図1. ハイレベルアーキテクチャ
ウォークスルー
ソリューションを5つのステップに構造化しました。各ステップを順を追って説明します:
ステップ1 – SAPシステムからデータを取得するビジネスロジックを作成
ステップ2 – 非SAPシステムからデータを取得するビジネスロジックを作成
ステップ3 – 一般的なクエリ用のBedrock Knowledge Basesを作成
ステップ4 – 異なるデータソース間を調整するBedrock Agentsを作成
ステップ5 – Microsoft Teams、Slack、Streamlitでユーザーインターフェースを作成
前提条件
Amazon S3、AWS Lambda、Amazon Bedrock Agents、Amazon Bedrock Knowledge Bases、Amazon Bedrock LLM(Claude)、AWS Secrets Manager、Amazon DynamoDBを操作するための適切なIAM権限を持つAWSアカウント。これらのサービスに慣れていない場合は、先に進む前にそれらを確認することを強く推奨します。
- SAP Sales OrderのデータソースとしてSAP ODataサービスをサポートするSAPシステム。
- このデモでは標準のODataサービス、SAP Sales Order Service:
API_SALES_ORDER_SRVとEntity Set:A_SalesOrderを使用していますが、ユースケースに基づいて任意のODataサービスを使用できます。ODataをインターネット上に公開していますが、SAPシステムの場所によってはインターネットに公開する必要がない場合もあります。ただし、より良いパフォーマンスとセキュリティ体制のためにプライベート接続を設定することを推奨します。詳細については、SAP S/4HANAでODataサービスを有効にする方法とAWSアカウントからRISEへの接続を参照してください。
- Slack統合用のSlackアカウントとMS Teams統合用のMS Teamsアカウント[オプション]
ステップ1 – SAPシステムからデータを取得するビジネスロジックを作成
I. まず、S4システムの認証情報とシステム接続詳細を保存するためにAWS Secrets Managerでシークレットを作成します。
シークレットタイプを選択でOther type of secretを選択し、キー/値ペアの下に以下の詳細を追加します。環境に適用可能なシークレット値を入力してください。
| シークレットキー | シークレット値 |
S4_host_details |
https://<hostname>:<port> |
S4_username |
xxxx |
S4_password |
xxxx |
詳細については、AWS Secrets Managerシークレットの作成を参照してください。
II. 第2ステップとして、必要に応じてSAPデータを補完・補足するために2つのBedrock Knowledge Basesを作成します。
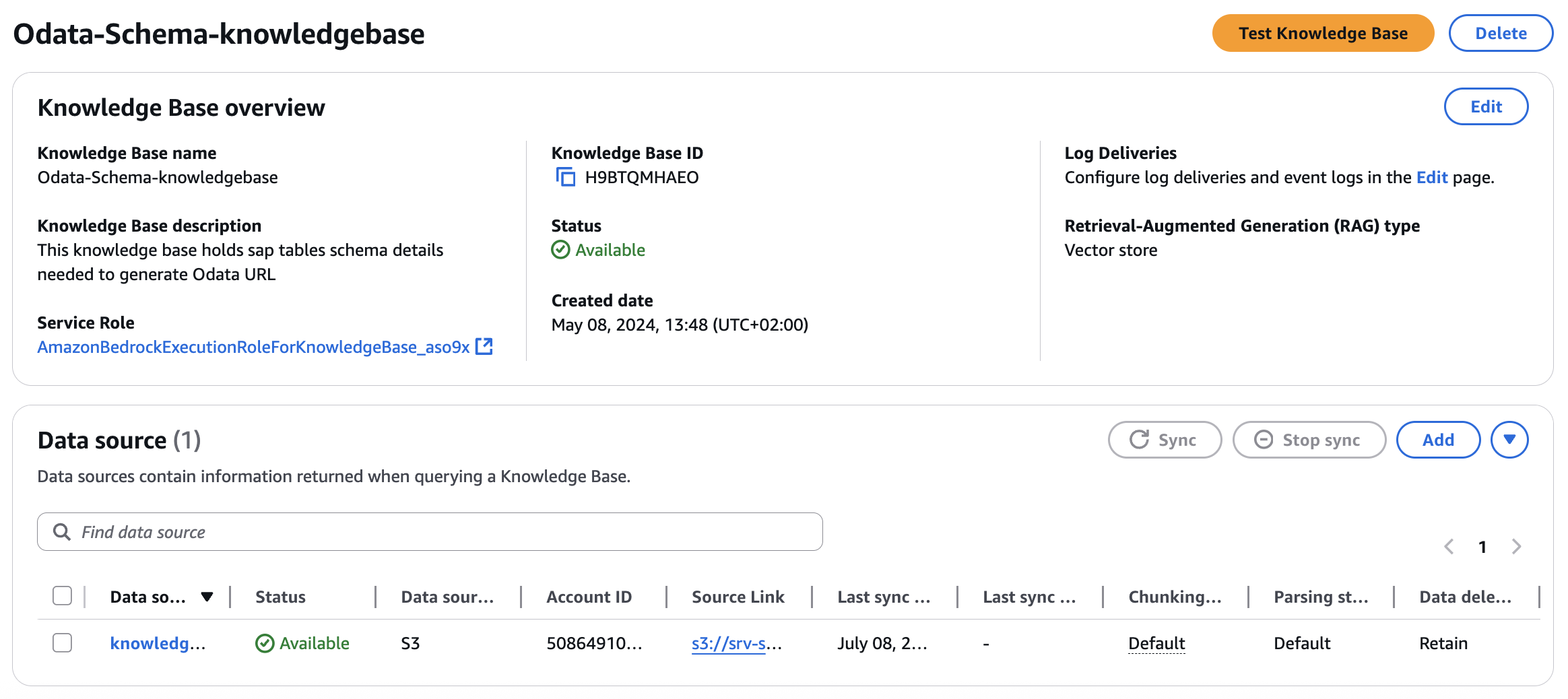
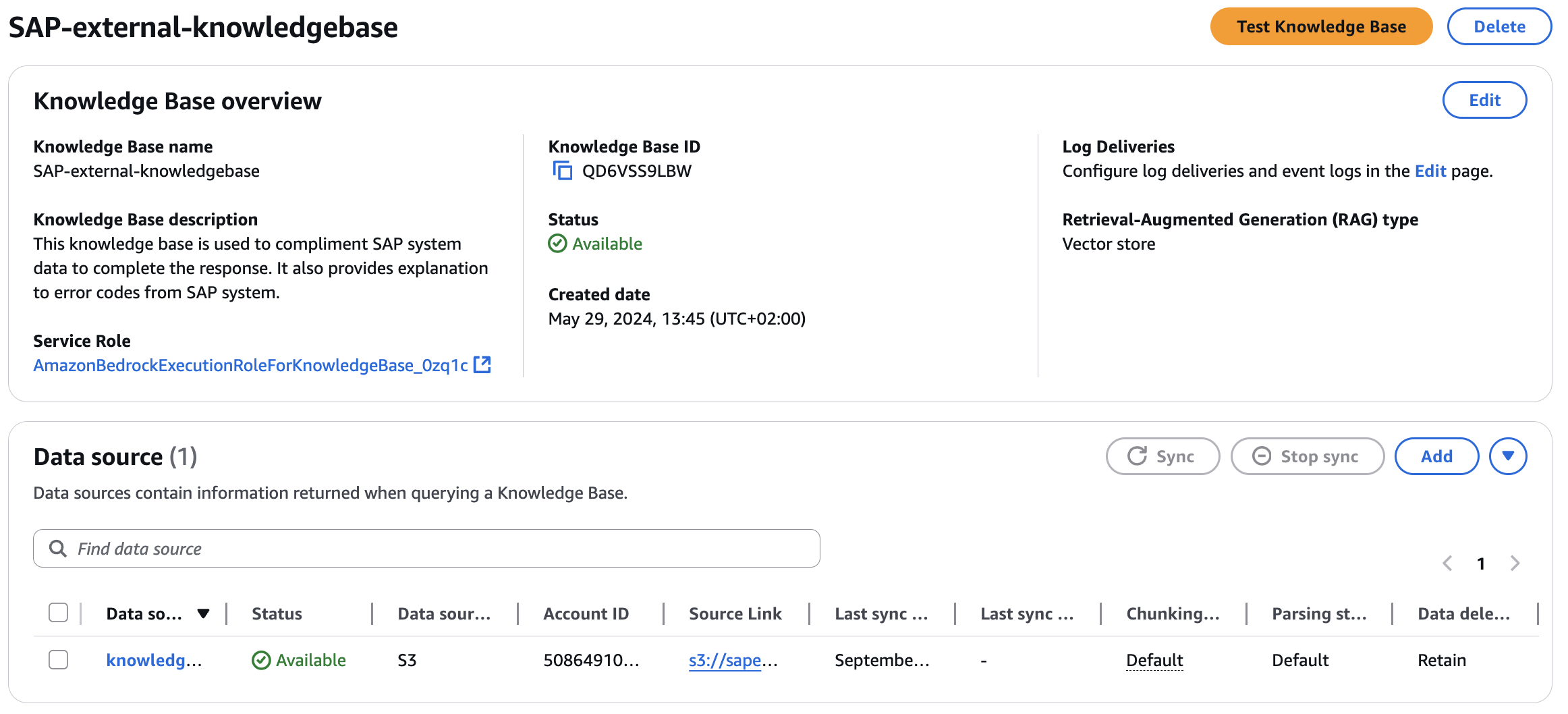
Odata-Schema-knowledgebaseこのKnowledge Basesを使用してLLMにスキーマ詳細を提供し、ユーザークエリに基づいてOdata URLを作成する際に使用する属性について十分な知識をモデルが持てるようにします。SAP-external-knowledgebaseこのKnowledge Basesを使用して非SAPデータに補足詳細を提供します。
2つのKnowledge Basesを作成する際に以下の入力を考慮し、他のすべての設定はデフォルト値のままにしました。
- Bedrock Knowledge Base詳細を提供
- Knowledge Base名: ユーザーフレンドリーな説明とともに各Knowledge Basesの名前を選択します。
Odata-Schema-knowledgebaseとSAP-external-knowledgebaseを使用しました。 - Knowledge Base説明: ナレッジベースを一意に定義する説明を提供します。
- Knowledge Base名: ユーザーフレンドリーな説明とともに各Knowledge Basesの名前を選択します。
- IAM権限:
Create and use a new service roleを選択 - データソースを設定
- データソース:
Amazon S3を選択 - データソース名: 各データソースの名前を選択します。
- S3 URI: 各Knowledge Bases用に2つのS3バケットを作成します。Odata-Schema-knowledgebase用に
Sales_Order_Schema.jsonファイルを、SAP-external-knowledgebase用にShipping_Policy.pdfをGitHubリポジトリから対応するS3バケットにアップロードし、S3 URIを提供します。
- データソース:
- データストレージと処理を設定
- 埋め込みモデル:
Amazon Titan Text Embeddings V2 - ベクターデータベース: ベクター作成方法として
Quick create a new vector store、ベクターストアとしてAmazon OpenSearch Serverlessを選択。
- 埋め込みモデル:
詳細については、Amazon Bedrock Knowledge Basesでデータソースに接続してナレッジベースを作成を参照してください。
最終的なエントリは以下のようになります:
III. 次に、ユーザークエリに基づいてSAPシステムからデータを抽出する2つのLambda関数を作成します。
SAP-Odata-URL-GenerationこのLambdaは、Knowledge Basesからのスキーマ詳細とAWS Secrets Managerからのホスト詳細によってサポートされるLLMの助けを借りて、ユーザークエリに基づいてOdata URLを生成するビジネスロジックを実行します。SAP-Sales-Order-QueryこのLambda関数は、SAPシステムからデータを取得するためのコアビジネスロジックを実行します。SAP-Odata-URL-Generation Lambdaによって提供されるOData URLを利用し、AWS Secrets Managerに保存されたシステム認証情報に安全にアクセスします。その後、関数は取得したデータを処理し、bedrockを通じてLLMを活用し、最終的に構造化された情報をBedrock Agentに提示してさらなる使用に供します。
関数を作成する際に以下の入力を考慮し、他のすべての設定はデフォルト値のままにしました。
Author from scratchを選択- 関数名: ユーザーフレンドリーな説明とともに各関数の名前を選択します。
SAP-Odata-URL-GenerationとSAP-Sales-Order-Queryを選択しました。 - ランタイム:
Python 3.13 - アーキテクチャ:
x86_64 - コード: 関数SAP-Odata-URL-Generation用に
SAP-Odata-URL-Generation.pyのコードを、SAP-Sales-Order-Query用にSAP-Sales-Order-Query.pyをGitHubリポジトリからコピーします。注意:kb_id、SecretIdなど、デプロイメント固有の値でコードを適応させてください。 - 設定: メモリ:
1024MB、タイムアウト:15min - レイヤー: lambda関数に
requestsモジュールを追加するために、GitHubリポジトリからrequests-layer.zipレイヤーを追加 - 権限:Lambda関数に以下の権限を設定する必要があります。
- SAP-Odata-URL-Generation:実行ロール –lambda基本ロールに加えて、以下のアクション
bedrock:InvokeModel、bedrock-agent-runtime:Retrieve、secretsmanager:GetSecretValueを持つ新しいIAMポリシーを作成、リソースベースポリシーステートメント –ステップ4で作成するBedrock Agent ARNへのlambda:InvokeFunctionアクセス。 - SAP-Sales-Order-Query:実行ロール –lambda基本ロールに加えて、以下のアクション
bedrock:InvokeModel、secretsmanager:GetSecretValueを持つ新しいIAMポリシーを作成リソースベースポリシーステートメント –ステップ4で作成するBedrock Agent ARNへのlambda:InvokeFunctionアクセス。
- SAP-Odata-URL-Generation:実行ロール –lambda基本ロールに加えて、以下のアクション
詳細については、PythonでLambda関数を構築とPython Lambda関数のレイヤーの操作を参照してください。
ステップ2 – 非SAPシステムからデータを取得するビジネスロジックを作成
I. まず、以下の入力でDynamoDBテーブルを作成します。
- テーブル名:
logistics - パーティションキー:
order_id
GitHubリポジトリのItems.jsonファイルを使用してDynamoDBテーブルにアイテムを作成します。詳細については、JSONファイルからAmazon DynamoDBテーブルアイテムを作成を参照してください。
II. 次に、ユーザークエリに基づいてDynamoDBテーブルからデータを抽出するLambda関数を作成します。
Author from scratchを選択- 関数名: ユーザーフレンドリーな説明とともに関数の名前を選択します。
Logistics-Systemを選択しました - ランタイム:
Python 3.13 - アーキテクチャ:
x86_64 - 設定: メモリ:
1024MB、タイムアウト:15min - コード: GitHubリポジトリから
Logistics-System.pyのコードをコピーします。 - 権限: Lambda関数に以下の権限を追加します。実行ロール – lambda基本ロールに加えて、以下のアクション
dynamodb:Query、dynamodb:DescribeTableを持つ新しいIAMポリシーを作成、リソースベースポリシーステートメント –ステップ4で作成するBedrock Agent ARNへのlambda:InvokeFunctionアクセス。
ステップ3 – 一般的なクエリ用のKnowledge Basesを作成
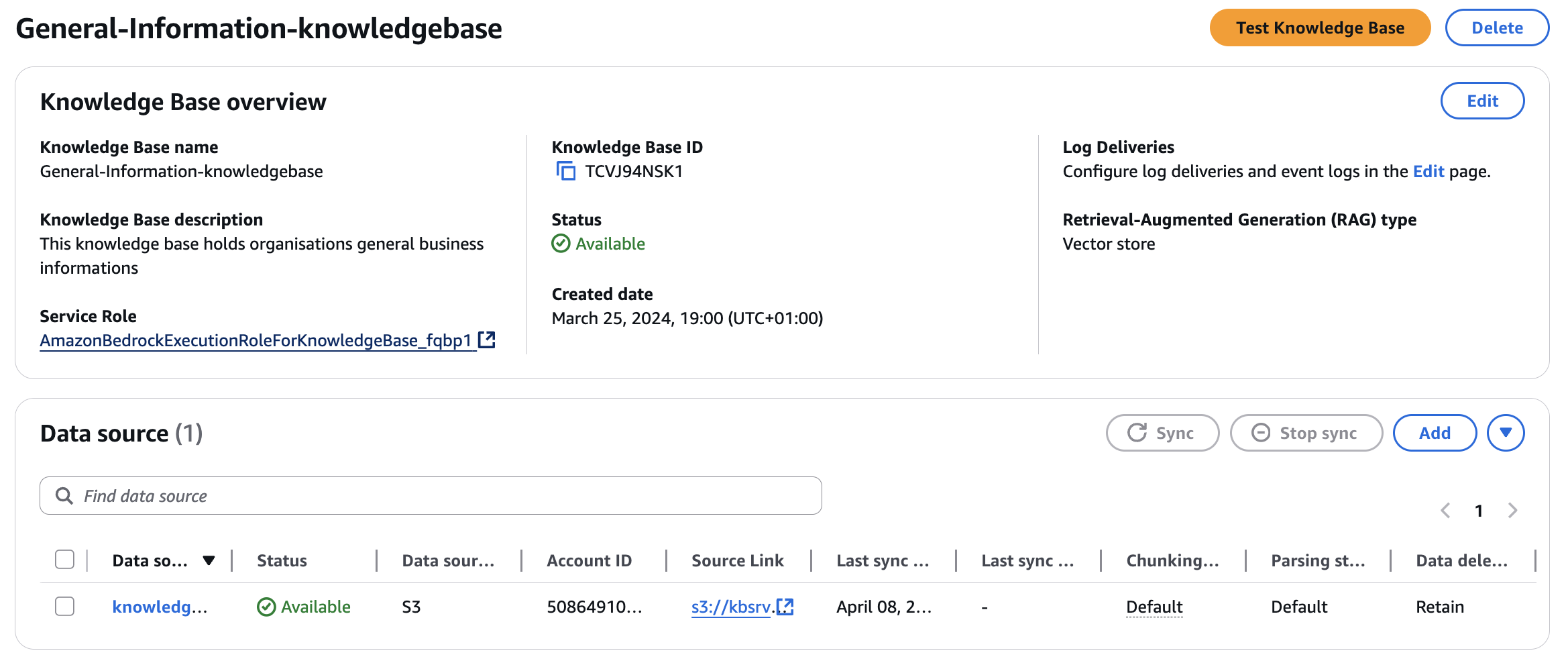
次に、3番目のナレッジベースを作成します。このナレッジベースは一般情報リポジトリとして機能します。ユーザーは、組織情報から特定の専門知識まで、必要に応じて様々なトピックについて学ぶためにこのリソースにアクセスできます。
General-information-knowledgebase: このデモでは、このナレッジベースを使用してSAPビジネスプロセスに関するガイダンスを提供します。
Knowledge Basesを作成する際に以下の入力を考慮し、残りはデフォルトのままにしました。
- Knowledge Base詳細を提供
- Knowledge Base名: 各Knowledge Basesの名前を選択します。ユーザーフレンドリーな説明とともに
General-information-knowledgebaseを使用しました。 - IAM権限:
Create and use a new service roleを選択
- Knowledge Base名: 各Knowledge Basesの名前を選択します。ユーザーフレンドリーな説明とともに
- データソースを設定
- データソース:
Amazon S3を選択 - データソース名: 選択に応じてデータソースの名前を選択します。
- S3 URI: S3バケットを作成し、GitHubリポジトリから「
How to create SAP Sales Order pdf」をアップロードし、対応するS3 URIを提供します。
- データソース:
- データストレージと処理を設定
- 埋め込みモデル:
Amazon Titan Text Embeddings V2 - ベクターデータベース: ベクター作成方法として
Quick create a new vector store、ベクターストアとしてAmazon OpenSearch Serverlessを選択。
- 埋め込みモデル:
最終的なエントリは以下のようになります:
ステップ4 – Bedrock Agentを作成:このステップでは、前のステップで作成した異なるデータソース間を調整してユーザークエリに応答するBedrock Agentを作成します。
bedrock agentを作成する際に以下の入力を考慮し、他のすべての設定はデフォルト値のままにしました。
- Agent詳細:
- Agent名: エージェントの名前とユーザーフレンドリーな説明を選択します。
Business-Query-Systemと名付けました。 - Agentリソースロール:
Create and use a new service roleを選択 - モデルを選択:
Claude 3 Sonnet v1を選択。異なるLLMを選択することもできますが、望ましい応答を得るためにプロンプトを適宜修正する必要があります。 - Agentへの指示: Agentに何をしてほしいかを明確に説明する正確で段階的な指示を与えます。
- Agent名: エージェントの名前とユーザーフレンドリーな説明を選択します。
You are an AI assistant helping users in querying SAP sales data directly from SAP system and shipping details from logistic system. You also help users with general queries about business process from the company knowledge base.
-
- 追加設定: ユーザー入力で
Enabledを選択
- 追加設定: ユーザー入力で
-
- アクショングループ:アクショングループは、エージェントがユーザーの達成を支援すべきタスクを定義します。
- アクショングループ:
SAP-Sales-Order。このアクショングループを使用してSAP Sales orderに関連するクエリを処理します。- アクショングループ名: アクショングループの名前を選択し、ユーザーフレンドリーな説明を入力します。
SAP-Sales-Orderと名付けました - アクショングループタイプ:
Define with function details - アクショングループ呼び出し:
Select an existing Lambda functionを選択し、ステップ1で作成したlambda関数SAP-Sales-Order-Queryを選択 - アクショングループ関数1名:
SalesOrderとして関数の説明を提供します。
- アクショングループ名: アクショングループの名前を選択し、ユーザーフレンドリーな説明を入力します。
- アクショングループ:
Logistics-System。このアクショングループを使用して販売注文の物流情報に関連するクエリを処理します。- アクショングループ名:アクショングループの名前を選択し、ユーザーフレンドリーな説明を入力します。
Logistics-Systemと名付けました - アクショングループタイプ:
Define with API schemas - アクショングループ呼び出し:
Select an existing Lambda functionを選択し、ステップ2で作成したlambda関数Logistics-Systemを選択。 - アクショングループスキーマ:
Select an existing API schema。 - S3 Url: S3バケットを作成し、GitHubリポジトリから
logistics.jsonファイルをS3バケットにアップロードし、バケットのS3 Urlを提供します。
- アクショングループ名:アクショングループの名前を選択し、ユーザーフレンドリーな説明を入力します。
- アクショングループ:
- メモリ:
Enabledを選択し、メモリ期間を2 days、最大最近セッション数を20に設定。 - Knowledge Bases:以前に作成したナレッジベースを追加
- Knowledge Baseを選択:
SAP-external-knowledgebase
- Knowledge Baseを選択:
- アクショングループ:アクショングループは、エージェントがユーザーの達成を支援すべきタスクを定義します。
AgentのKnowledge Base指示:SAPシステム外の情報が必要で、SAPシステムデータと組み合わせて応答を完成させる場合にこのナレッジベースを使用
-
-
- Knowledge Baseを選択:
General-Information-knowledgebase
- Knowledge Baseを選択:
-
AgentのKnowledge Base指示:SAPシステムから利用できないユーザーからの一般的なビジネス質問に答えるためにこのナレッジベースを使用。
-
- オーケストレーション戦略詳細 –
Default orchestration。Bedrock agentsはデフォルトプロンプトテンプレートを提供しますが、特定の要件に合わせて調整できます。特定のユースケース要件に合わせて以下のプロンプトテンプレートをカスタマイズします。
- オーケストレーション戦略詳細 –
-
-
- 前処理:
Override pre-processing template defaultsを選択。プロンプトテンプレートに以下のセクションを追加します。
- 前処理:
-
-Category F: Questions that can be answered or assisted by our function calling agent using the functions it has been provided and arguments from within conversation history or relevant arguments it can gather using the askuser function AND also needs external data from the knowledge base to complete the response. Combine data from the SAP or non-SAP Logistic system and the external knowledge base to prepare the final answer
-
-
- オーケストレーション:
Override orchestration template defaultsを選択。プロンプトテンプレートの対応するセクションの下に以下のテキストを追加します。
- オーケストレーション:
-
$knowledge_base_guideline$
- If any data is not updated in the Logistic system like order shipping date, then check the knowledge base named 'SAP-external-knowledgebase' to look for the estimated delivery timeline as per the shipping category. Then consider that timeline and add the timeline to the date of 'Order Received' and share the estimated the shipping date with the user
- If the SAP system throws any error due to unavailability of the requested data, check the knowledge base named 'SAP-external-knowledgebase' to look for the explanation of the ERROR CODE. Respond to the user with the explanation of the error code ONLY
$tools_guidelines$ [このセクションは存在しないため、作成する必要があります]
- Invoke tool 'SAP-Sales-Order' ONLY for any questions related to sales order
- Invoke tool 'Logistics-System' ONLY for any shipping details for the sales order
- Do NOT invoke both tools 'SAP-Sales-Order' and 'Logistics-System' unless user requested for both the information.
$multiple_tools_guidelines$ [このセクションは存在しないため、作成する必要があります]
- If user asks question which needs to invoke more than one tool. Invoke the tools one by one. Collect the response from both the tools and then combine them before responding to the users.
For example, if user requests for both Sales order and Logistic information. First fetch the Sales Order details with Sales Order tool. Then fetch logistic details from Logistic tool. Finally combine both responses into one when responding to the user.
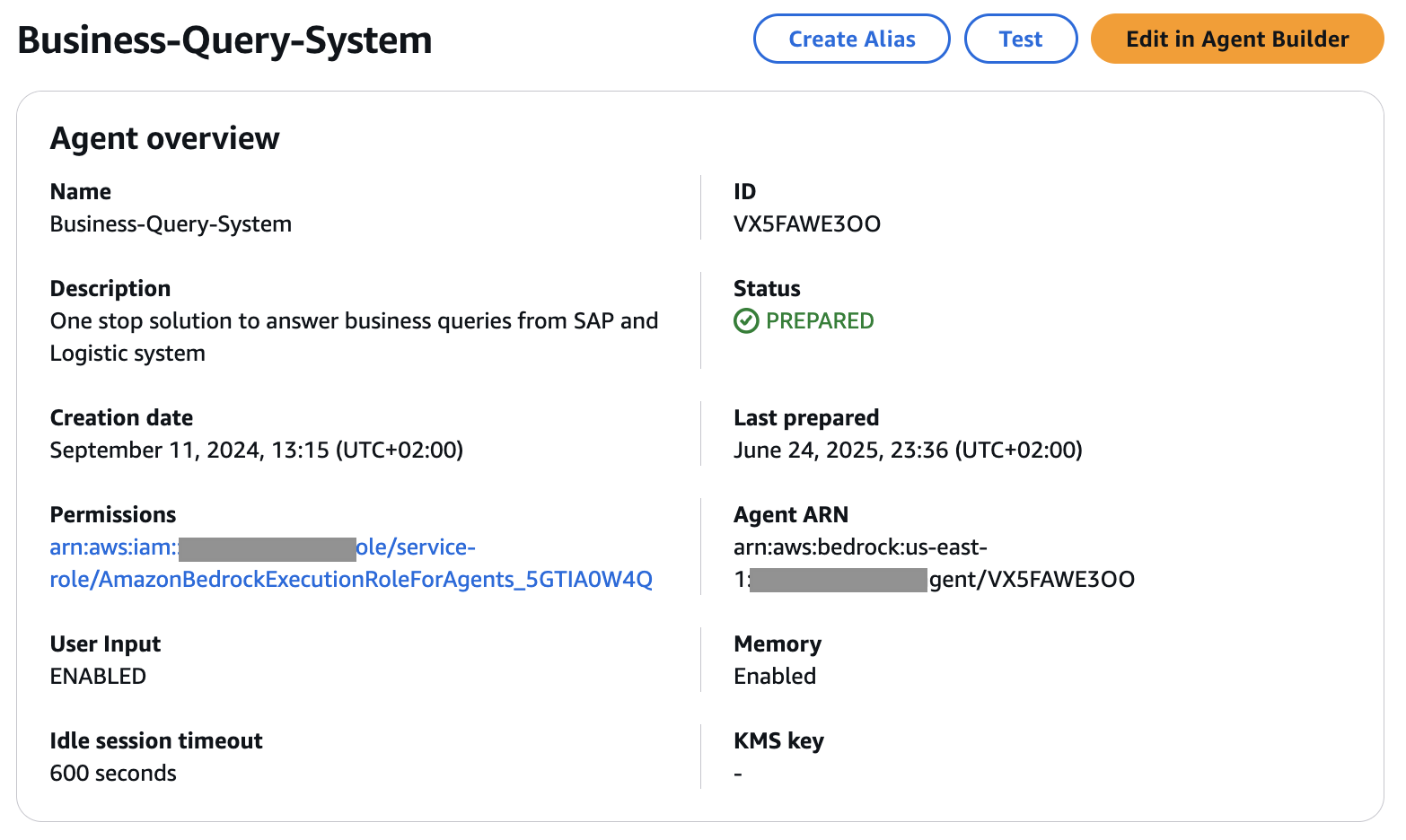
すべての詳細を入力したら保存し、準備を選択して最新の変更を更新します。エージェント概要ページに移動するには保存して終了を選択します。
最後に、アプリケーションで使用するエージェントの特定のスナップショットまたはバージョンを持つためにエイリアスを作成します。
作成を選択し、ユーザーフレンドリーな説明とともにエイリアス名を提供します。
スループットをデフォルトのオンデマンドにしたバージョンで新しいバージョンを作成してこのエイリアスに関連付けるを選択します。
詳細については、エージェントを手動で作成および設定を参照してください。
最終的なエントリは以下のようになります:
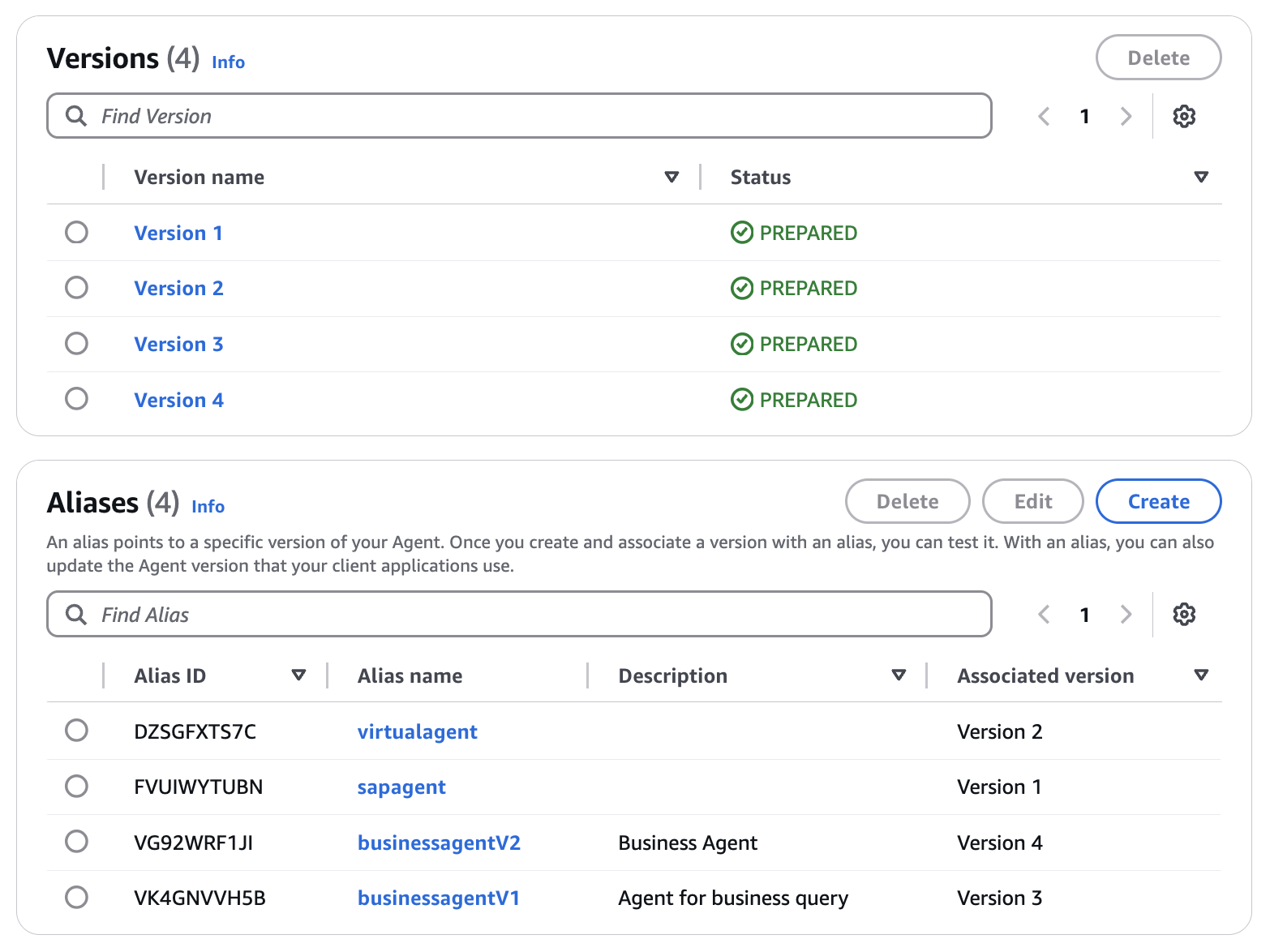
ご覧のように、エージェントの複数のエイリアスとバージョンを作成し、任意のエイリアスを選択してアプリケーションに特定のスナップショットまたはバージョンを統合できます。
次に、bedrock agentがそれらを呼び出せるようにLambda関数のIAMロールを調整する必要があります。
Lambdaのリソースベースポリシーの使用の手順に従い、Amazon Bedrockがエージェントのアクショングループ用にLambda関数にアクセスできるようにするために、必要に応じて${values}を置き換えて、以下のリソースベースポリシーをLambda関数にアタッチします。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AccessLambdaFunction",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:${region}:${account- id}:function:function-name",
"Condition": {
"StringEquals": {
"AWS:SourceAccount": "${account-id}"
},
"ArnLike": {
"AWS:SourceArn": "arn:aws:bedrock:${region}:${account-id}:agent/${agent-id}"
}
}
}
]
}
私のポリシーは以下のようになります
{ "Version": "2012-10-17", "Id": "default", "Statement": [ { "Sid": "bedrock-agent-sales", "Effect": "Allow", "Principal": { "Service": "bedrock.amazonaws.com" }, "Action": "lambda:InvokeFunction", "Resource": "arn:aws:lambda:us-east-1:1234567xxxx:function:SAP-Sales-Order-Query", "Condition": { "StringEquals": { "AWS:SourceAccount": "1234567xxxx" }, "AWS:SourceArn": { "arn:aws:bedrock:us-east-1: 1234567xxxx:agent/VX5FAWE3OO" } } } ] } ステップ5 – Microsoft Teams、Slack、Streamlitでユーザーインターフェースを作成
このステップでは、ユーザーがBedrock agentと相互作用できるユーザーインターフェースの開発を行います。
- Microsoft Teams – この統合には、MS Teams(適切な権限を持つ)とAmazon Q Developer in chat applicationの両方へのアクセスが必要です。Amazon Q Developer in chat applications(以前のAWS Chatbot)により、Microsoft TeamsでGenAI Bedrock Agentsと相互作用できます。
ステップ1: アプリアクセスを設定:
Microsoft Teamsが組織管理者によってインストールされ、承認されています。
ステップ2: Teamsチャンネルを設定:
MS Teams標準チャンネルを作成するか既存のものを使用し、Amazon Q DeveloperをチャンネルにAmazon Q Developerを追加します。[注意:Microsoft Teamsは現在プライベートチャンネルでAmazon Q Developerをサポートしていないため、標準チャンネルが必要です]
-
-
- Microsoft Teamsで、チーム名を見つけて選択し、チームを管理を選択します。
- アプリを選択し、その他のアプリを選択します。
- 検索バーにAmazon Q Developerと入力してAmazon Q Developerを見つけます。
- ボットを選択します。
- チームに追加を選択し、プロンプトを完了します
-
ステップ3: TeamsクライアントのAmazon Q Developerを設定
このステップでは、Amazon Q Developer in chat ApplicationsにMS Teamsチャンネルへのアクセスを提供します。
-
-
- AWSコンソールでAmazon Q Developer in chat applicationsを開きます。
- チャットクライアントを設定の下で、Microsoft Teamsを選択し、前のステップで作成したMicrosoft TeamsチャンネルURLをコピーして貼り付け、設定を選択します。[Amazon Q DeveloperがあなたのAmazon Q Developerがあなたの情報にアクセスする権限を要求するTeams認証ページにリダイレクトされます]。
- Microsoft Teams認証ページで、承認を選択します。左側に、Microsoft TeamsでTeamsチャンネルがリストされているのが確認できるはずです。
-
次に、MS Teamsチャンネルを設定に関連付けます。
Amazon Q DeveloperコンソールのTeams詳細ページで、新しいチャンネルを設定を選択します。設定に以下の入力を使用し、残りはデフォルトのままにします。
-
-
- 設定詳細:
-
設定名: 設定の名前を選択します。aws-sap-demos-teamと名付けました
-
-
- Microsoft Teamsチャンネル
-
チャンネルURL:ステップ2で作成したMicrosoft TeamsチャンネルURLをコピーして貼り付けます。
-
-
- 権限
- ロール設定: チャンネルロールを選択
- チャンネルロール:テンプレートを使用してIAMロールを作成を選択
- ロール名:選択した名前を選択します。awschatbot-sap-genai-teams-role と名付けました
- ポリシーテンプレート:Amazon Q Developer access permissions
- チャンネルガードレールポリシー[ポリシー名]:AWSLambdaBasicExecutionRole、AmazonQDeveloperAccess。要件に応じてIAMポリシーを調整できますが、常に最小権限権限のベストプラクティスに従うことを推奨します。
- 権限
-
ステップ4: 次に、エージェントをチャットチャンネルに接続します
Amazon Q Developer Bedrock Agentコネクタにはbedrock:InvokeAgent IAMアクションが必要です。
前のステップで作成したIAMロール:awschatbot-sap-genai-teams-role に以下のポリシーを追加します。
{
"Sid": "AllowInvokeBedrockAgent",
"Effect": "Allow",
"Action": "bedrock:InvokeAgent",
"Resource": [
"arn:aws:bedrock:aws-region:<AWS Account ID>:agent-alias/<Bedrock Agent ID>/<Agent Alias ID>/"
]
}Amazon Bedrock agentをチャットチャンネルに追加するには、@Amazon Q connector add connector_name arn:aws:bedrock:aws-region:AWSAccountID:agent/AgentID AliasID.と入力します。選択したコネクタ名を選択してください。
私のエントリは以下のようになります。
@Amazon Q connector add order_assistant arn:aws:bedrock:us-east-1:xxxxxxx:agent/VX5FAWE3OO VG92WRF1JI
詳細については、チュートリアル:Microsoft Teamsを開始するを参照してください。
Teamsインターフェースは以下のようになります
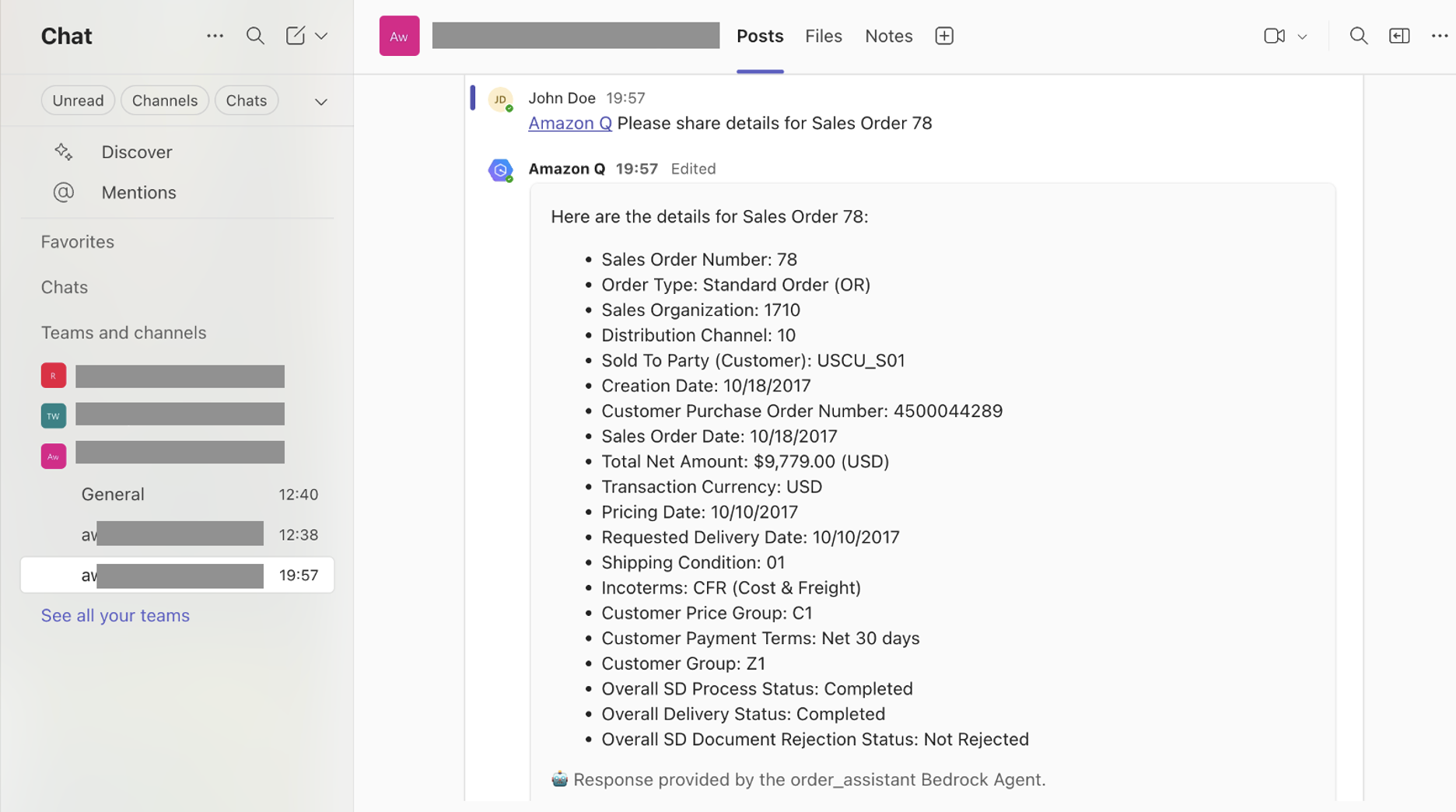
- Slack – この統合には、Slack(適切な権限を持つ)とAmazon Q Developer in chat applicationの両方へのアクセスが必要です。Amazon Q Developer in chat applications(以前のAWS Chatbot)により、SlackでGenAI Bedrock Agentsと相互作用できます。
ステップ1: アプリアクセスを設定:
ワークスペース管理者は、ワークスペース内でのAmazon Q Developerアプリの使用を承認する必要があります。
ステップ2: Slackチャンネルを設定:
slackチャンネルを作成するか既存のものを使用し、Amazon Q DeveloperをSlackチャンネルに追加します。
Slackチャンネルで、/invite @Amazon Qと入力し、招待するを選択します
ステップ3: SlackクライアントのAmazon Q Developerを設定
このステップでは、Amazon Q Developer in chat ApplicationsにSlackワークスペースへのアクセスを提供します。
-
-
- AWSコンソールでAmazon Q Developer in chat applicationsを開きます。チャットクライアントを設定の下で、Slackを選択し、設定を選択します。[Amazon Q Developerがあなたの情報にアクセスする権限を要求するSlackの認証ページにリダイレクトされます]。
- Amazon Q Developerで使用したいSlackワークスペースを選択し、許可を選択します。
- 左側に、SlackでSlackワークスペースがリストされているのが確認できるはずです。
-
次に、チャンネルを設定に関連付けます。
Amazon Q Developerコンソールのワークスペース詳細ページで、新しいチャンネルを設定を選択します。設定に以下の入力を使用し、残りはデフォルトのままにします。
-
-
- 設定詳細:
-
設定名: 設定の名前を選択します。sap-genai-slack-chatbotと名付けました
-
-
- Amazon内部設定
-
アカウント分類:非本番を選択
-
-
- Slackチャンネル
-
チャンネルID: ステップ2で設定したslackチャンネルのチャンネルIDを提供します。
-
-
- 権限
- ロール設定: チャンネルロールを選択
- チャンネルロール:テンプレートを使用してIAMロールを作成を選択
- ロール名:選択した名前を選択します。aws-sap-genai-chatbot-role と名付けました
- ポリシーテンプレート:Amazon Q Developer access permissions
- チャンネルガードレールポリシー[ポリシー名]:AWSLambdaBasicExecutionRole、AmazonQDeveloperAccess。要件に応じてIAMポリシーを調整できますが、常に最小権限権限のベストプラクティスに従うことを推奨します。
- 権限
-
ステップ4: 次に、エージェントをチャットチャンネルに接続します
Amazon Q Developer Bedrock Agentコネクタにはbedrock:InvokeAgent IAMアクションが必要です。
前のステップで作成したIAMロール:awschatbot-sap-genai-teams-role に以下のポリシーを追加します。
{
"Sid": "AllowInvokeBedrockAgent",
"Effect": "Allow",
"Action": "bedrock:InvokeAgent",
"Resource": [
"arn:aws:bedrock:aws-region:<AWS Account ID>:agent-alias/<Bedrock Agent ID>/<Agent Alias ID>/"
]
}
Amazon Bedrock agentをチャットチャンネルに追加するには、以下のように入力します。選択したコネクタ名を選択してください。
@Amazon Q connector add connector_name arn:aws:bedrock:aws-region:AWSAccountID:agent/AgentID AliasID.
私のエントリは以下のようになります。
@Amazon Q connector add order_assistant arn:aws:bedrock:us-east-1:xxxxxxx:agent/VX5FAWE3OO VG92WRF1JI
詳細については、チュートリアル:Slackを開始するを参照してください。
Slackインターフェースは以下のようになります
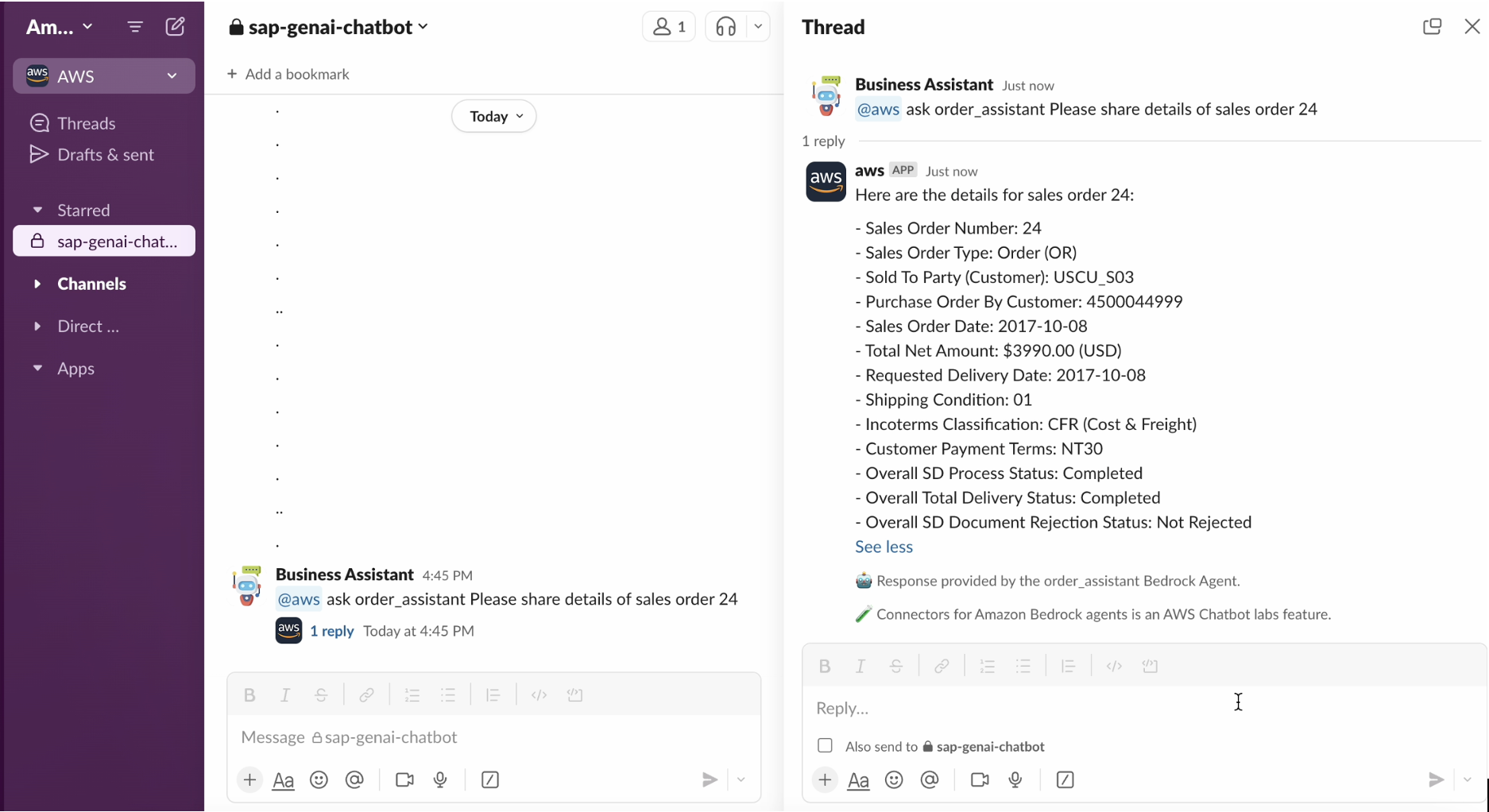
- Streamlit – Streamlitは、pythonスクリプト用のインタラクティブなWebアプリを構築するために一般的に使用されるオープンソースのPythonフレームワークです。Amazon EC2インスタンスでアプリケーションをホストするために以下の手順に従いました。
- EC2インスタンスを起動します。Amazon Linux t2.microインスタンスを考慮しました。
- HTTP/HTTPSトラフィック(ポート80/443/8501または使用を選択した他のポート)を許可する必要なセキュリティグループでEC2インスタンスを設定
- 以下のように環境を準備
必要なパッケージをインストール
$sudo apt update
$sudo apt-get install python3-venv
仮想環境を設定
$mkdir streamlit-demo
$cd streamlit-demo
$python3 -m venv venv
$source venv/bin/activate
-
- Streamlitをインストール
$pip install streamlit
-
- Vi/Vim/nanoエディタを使用してstreamlit-app.pyという名前のファイルを作成し、GitHubリポジトリから
streamlit-app.pyのコードをコピーします。
- Vi/Vim/nanoエディタを使用してstreamlit-app.pyという名前のファイルを作成し、GitHubリポジトリから
-
- 以下のコマンドでStreamlitアプリを実行
$streamlit run streamlit-app.py
-
- 以下のコマンドでstreamlitアプリをバックグラウンドで実行
$nohup streamlit run streamlit-app.py &
-
- Streamlitは8501から1ずつ増加して利用可能なポートを割り当てます。streamlitに特定のポートを考慮させたい場合は、以下のコマンドを使用できます
$streamlit run streamlit-app.py --server.port XXXX
上記のコマンドを実行した後、以下に示すように、ブラウザでStreamlitアプリケーションを開くURLを確認できました
Streamlitアプリケーションは以下のようになります

コスト
大規模言語モデル(LLM)の運用には、相当なインフラストラクチャ、開発、保守コストが伴います。しかし、Amazon BedrockなどのAWSサービスは、簡素化されたインフラストラクチャ管理、合理化された開発プロセス、柔軟な価格モデル、選択したLLMにアクセスするための様々なコスト最適化オプションを通じて、費用を大幅に削減できます。
| AWSサービス – US East(N. Virginia) | コスト | 見積もり[1時間実行] |
| Bedrock – Foundation Model LLM推論[Claude 3.5 Sonnet] | 100K入力、200K出力 | $3.3 |
| Bedrock – 埋め込みモデル推論[Amazon Titan Text Embeddings v2] | 100ドキュメント、各平均500語 | $0.10 |
| OpenSearch Compute Unit(OCU)– インデックス作成 | 2 OCU[最小2 OCU] | $0.48 |
| OpenSearch Compute Unit(OCU)– 検索とクエリ | 2 OCU[最小2 OCU] | $0.48 |
| OpenSearch管理ストレージ | 10GB | $0.24 |
| EC2インスタンス[Streamlitアプリ] | t2.micro | $ 0.0116 |
| Lambda、Secrets Manager、DynamoDB | $ 0.2 | |
| 1時間のアプリケーション使用の推定コスト – $4.8116 | ||
詳細については、Amazon Bedrock価格、Amazon OpenSearch Service価格、Amazon EC2オンデマンド価格、AWS Lambda価格、AWS Secrets Manager価格、Amazon DynamoDB価格を参照してください。
結論
このブログ投稿では、Amazon Bedrockに焦点を当てたAWSサービスを使用して、SAPと非SAPシステムの両方とシームレスに相互作用するインテリジェントな仮想アシスタントを作成する方法を実演しています。このソリューションは、販売注文データ用のSAPシステム、物流情報用の非SAPシステム、補足詳細用のKnowledge Basesを統合し、Streamlit、Microsoft Teams、Slackを含む複数のユーザーインターフェースを通じてアクセス可能です。Lambda、Bedrock、Secrets Manager、DynamoDBなどのAWSサービススイートを活用することで、実装は複雑なエンタープライズシステムとの自然言語相互作用を可能にし、堅牢なセキュリティを維持しながら多様なデータソースへの統一アクセスを提供します。サーバーレスアーキテクチャと従量課金制価格モデルにより、これは会話型AIインターフェースを通じてデータアクセス機能を強化しようとする組織にとってアクセス可能で費用対効果の高いソリューションとなります。このブログ投稿では、このソリューションを実装するための詳細な段階的ガイドを提供し、企業がSAPおよび非SAP環境で生成AIを活用する道を開きます。
このソリューションを実装することで、エンタープライズデータとの相互作用を変革する実践的な経験を得てください。Amazon AgentCore(プレビュー)でAIエージェントを安全に大規模にデプロイ・運用、予測分析用のAmazon Forecast、インテリジェントドキュメント処理用のAmazon Textract、言語翻訳用のAmazon Translate、自然言語処理用のAmazon Comprehendを含む包括的な機械学習サービススイートを探索してデジタル変革を加速してください。これらのサービスはSAPとシームレスに統合し、様々なビジネスニーズに対応し、組織の新しい可能性を解き放ちます。
何千もの顧客がSAPの移行とイノベーションでAWSを信頼する理由を学ぶには、AWS for SAPページをご覧ください。
本ブログはパートナー SA 松本が翻訳しました。原文はこちらです。