Amazon Web Services ブログ
Author: Takayuki Enomoto
OpenSearch Specialist Solutions Architect in AWS Japan.

Amazon OpenSearch Service のエージェント AI でオブザーバビリティとトラブルシューティングを効率化
Amazon OpenSearch Service にエージェント AI 機能が追加されました。エージェントチャットボット、調査エージェント、エージェントメモリの 3 つの機能が連携し、インシデント発生時のアラートから根本原因の特定までを数分で実現します。仮説駆動型の分析で複数インデックスのデータを自動相関し、平均復旧時間 (MTTR) を短縮します。

Amazon OpenSearch Serverless の集中型・分散型ネットワーク接続パターンの設計 – パート 2
本記事は、Amazon OpenSearch Serverless のハイブリッドマルチアカウントアクセスパターンに関するシリーズのパート 2 です。複数の事業部門が独立して OpenSearch Serverless コレクションを管理するシナリオに対応する分散型アーキテクチャを紹介します。中央ネットワーキングアカウントのカスタムプライベートホストゾーンと Route 53 Profile を活用し、オンプレミスおよびスポークアカウントからのプライベートアクセスを実現します。

Amazon OpenSearch Serverless の集中型・分散型ネットワーク接続パターンの設計 – パート 1
本記事では、Amazon OpenSearch Serverless の集中型・分散型ネットワーク接続パターンを紹介します。集中型インターフェイス VPC エンドポイントと Route 53 Profiles を使用して、オンプレミス環境や複数の AWS アカウントから OpenSearch Serverless コレクションにセキュアにプライベートアクセスする方法を解説します。

Amazon MSK Express ブローカーで Kafka 運用をシンプルにする
本記事では、Amazon MSK Express ブローカーが Kafka クラスターの運用をどのようにシンプルにするかを紹介します。サイジング、ストレージ管理、コンピューティングのスケーリング、モニタリング、アクセス制御、高可用性について、Express ブローカーがもたらす改善を解説します。
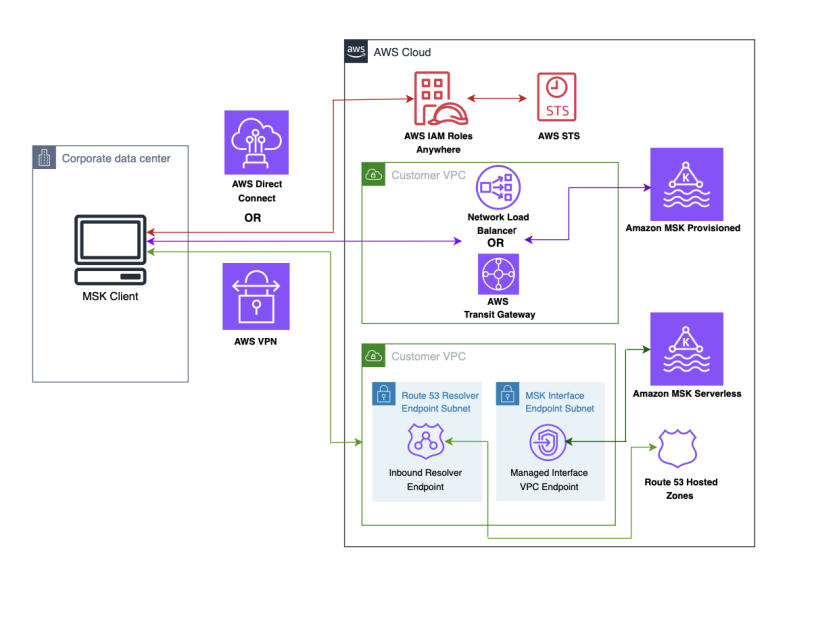
IAM Roles Anywhere を使用して AWS 外の Kafka クライアントから Amazon MSK にセキュアに接続する
本記事では、AWS IAM Roles Anywhere を使用して、AWS 外で動作する Kafka クライアントから Amazon MSK クラスターにセキュアに接続する方法を紹介します。X.509 証明書による一時的なセキュリティ認証情報の取得により、長期認証情報の管理が不要になり、セキュリティ体制を強化できます。

Kinesis On-demand Advantage でストリーミングコストを 60% 以上削減
Amazon Kinesis Data Streams の On-demand Advantage モードを使用して、ストリーミングコストを 60% 以上削減する方法を 3 つの実際のシナリオで紹介します。安定したスループット、延長保持、Enhanced Fan-Out コンシューマーなど、さまざまなユースケースでのコスト最適化効果を検証しました。

Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析を実現した方法
Amplitude が Amazon OpenSearch Service をベクトルデータベースとして活用し、自然言語による分析機能 Ask Amplitude を構築した過程を紹介します。PostgreSQL での総当たりコサイン類似度から pgvector による ANN 検索を経て、OpenSearch Service でのハイブリッド検索へと進化させ、アーキテクチャの簡素化、レイテンシーの削減、マルチテナント環境でのスケーラビリティ向上を実現しました。
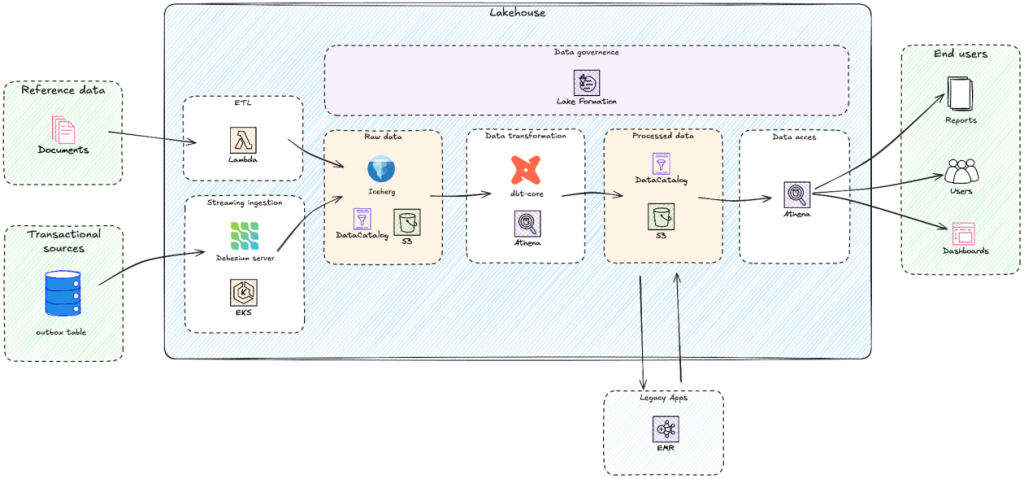
レイクハウスアーキテクチャの構築: Yggdrasil Gaming の BigQuery から AWS への移行
Yggdrasil Gaming が Google BigQuery から AWS 分析サービスへ移行し、Apache Iceberg ベースのレイクハウスアーキテクチャを構築した事例を紹介します。AWS パートナーの GOStack と連携し、データ処理コストの 60% 削減、分析レイテンシーの 75% 改善を実現した段階的な移行アプローチを解説します。

CloudWatch アラームを使用した Amazon MSK の本番環境向けモニタリングの設定
本記事では、Amazon CloudWatch を使用した Amazon MSK クラスターの本番環境向けモニタリングの設定方法を解説します。ブローカーの健全性、リソース使用率、コンシューマーラグなどの主要メトリクスのカテゴリ分類と、推奨される CloudWatch アラームのしきい値を紹介し、ストリーミングワークロードの問題を早期に検知するためのプラクティスを説明します。

Amazon OpenSearch Serverless のコレクショングループでマルチテナントワークロードのコストを最適化
Amazon OpenSearch Serverless のコレクショングループ機能が一般提供開始されました。マルチテナントワークロードで、テナントごとの暗号化によるセキュリティ境界を維持しながら、異なる KMS キーを持つコレクション間で OCU リソースを共有し、コンピューティングコストを最大 90% 削減できます。