Amazon Web Services ブログ
Category: Analytics
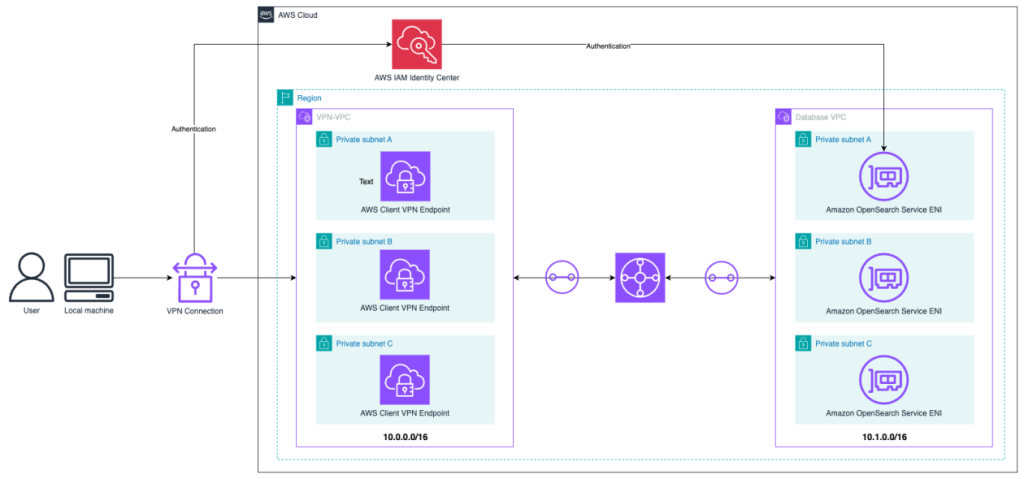
AWS Client VPN を使用して SAML 認証で VPC 内の Amazon OpenSearch Service ドメインにアクセスする
本記事では、AWS Client VPN、AWS Transit Gateway、AWS IAM Identity Center を使用して、VPC 内にデプロイされた Amazon OpenSearch Service ドメインに SAML 認証でアクセスするアーキテクチャの構築方法を紹介します。踏み台サーバーを使用せずに、安全で集中管理されたアクセスを実現できます。

自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]
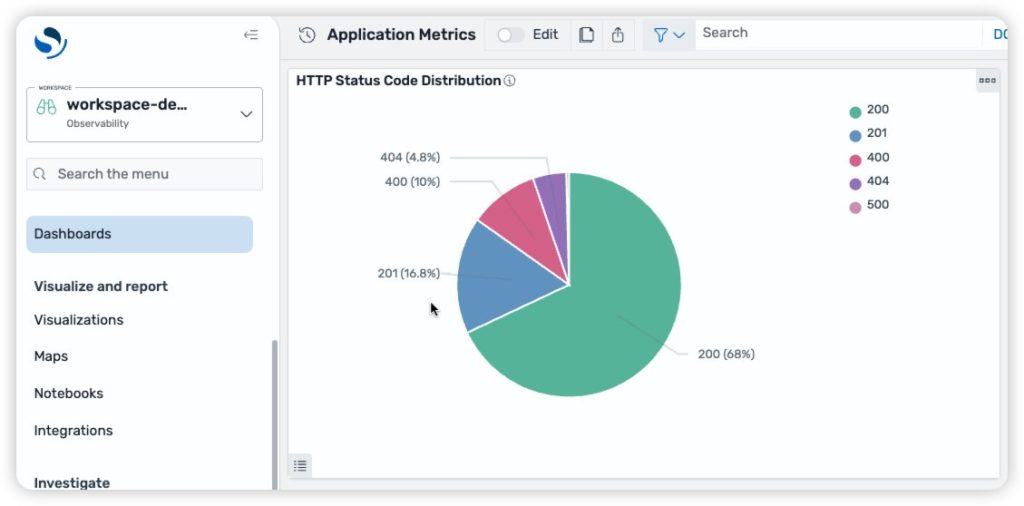
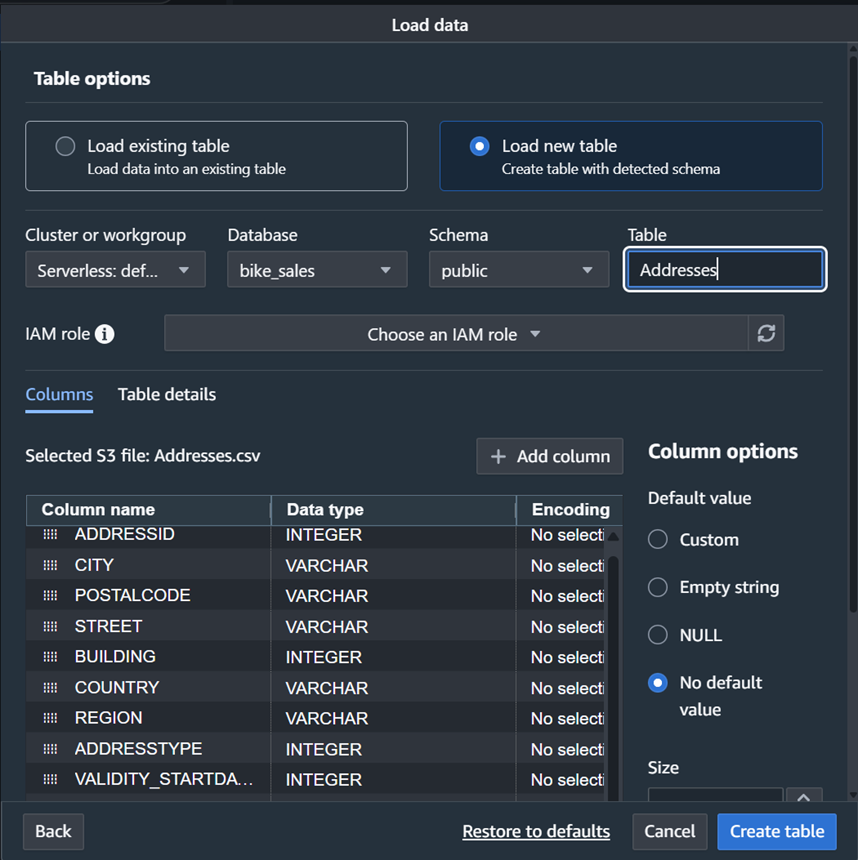
AWS CDK を使用した Amazon OpenSearch UI インフラストラクチャの IaC 管理
この記事では、AWS CDK を使用して Amazon OpenSearch UI アプリケーションをデプロイし、AWS Lambda 関数と統合してワークスペースとダッシュボードを自動的に作成する方法を説明します。Infrastructure as Code (IaC) により、環境は標準化され、バージョン管理され、デプロイ間で一貫性のある分析機能を備えた状態で起動します。

Amazon MSK Express ベースのクラスターのオンデマンドスケーリングとスケジュールスケーリング
Amazon MSK Express ブローカーのインテリジェントリバランシング機能を活用して、CloudWatch メトリクスや事前定義されたスケジュールに基づいて Kafka クラスターを動的にスケーリングするソリューションを紹介します。オンデマンドスケーリングとスケジュールスケーリングの 2 つのアプローチで、パフォーマンスを維持しながらコスト効率を最適化できます。
リクルート『ホットペッパーグルメ』が Amazon OpenSearch Service で Hybrid Search を実現し検索体験を革新
株式会社リクルートは、日本国内で HR・販促事業を行う事業会社です。リクルートでは、満足度No1(*1)を誇る […]
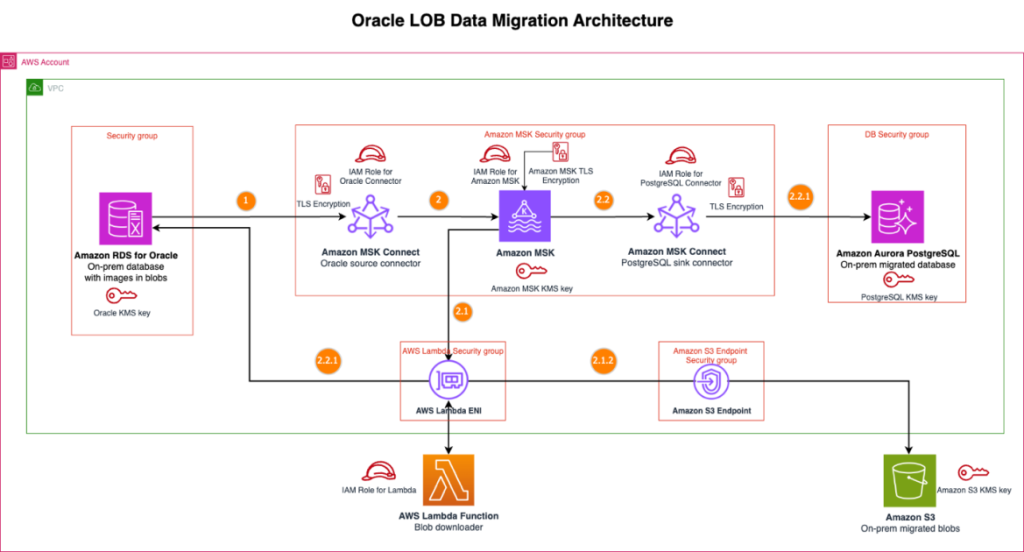
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。

Bazaarvoice が Amazon MSK で Apache Kafka インフラストラクチャをモダナイズした方法
Bazaarvoice は、セルフホスト型 Kafka から Amazon MSK に移行し、運用オーバーヘッドを削減しながら、セキュリティ、信頼性、パフォーマンスを向上させました。この記事では、移行プロセスと得られた教訓を紹介します。
寄稿:東京証券取引所が挑む膨大な取引データの処理 – AWS 活用で実現した次世代データ分析基盤
本稿は、株式会社日本取引所グループ(以下「JPX」)傘下の株式会社東京証券取引所(以下「東証」)による「膨大な […]
Amazon Q Business と Amazon Bedrock によるSAP データ価値の最大化 – パート 2
このシリーズのパート1では、Amazon Q BusinessとAmazon Bedrockの力を組み合わせて、SAP Early Watch Reportsから実用的なインサイトを得る方法、およびBusiness Data Automationを使用したIntelligent Document ProcessingをSAPシステムの請求書データ処理に使用する方法を検討しました。この投稿では、Amazon Bedrock Knowledge Bases for Structured Dataを使用して、SAPデータに関する質問に自然言語形式で回答する方法を実演します。

Amazon Kinesis Video Streams の warm ストレージ階層で長期動画保存コストを最適化
本記事は 2026年 1 月 4 日に公開された Optimize long-term video stora […]