Amazon Web Services 한국 블로그
Amazon S3 Files 정식 출시 – S3 버킷을 파일 시스템처럼 접근 가능
모든 AWS 컴퓨팅 리소스를 Amazon Simple Storage Service(Amazon S3)와 원활하게 연결하는 새로운 파일 시스템인 Amazon S3 Files를 발표합니다!
10여 년 전, AWS 트레이너로 일하면서 객체 스토리지와 파일 시스템의 근본적인 차이를 설명하는 데 긴 시간을 할애했습니다. 제가 가장 좋아하는 비유는 S3 객체를 도서관의 책(페이지를 편집할 수 없고 책 전체를 바꿔야 함)과 비교하는 것이었습니다. 반면, 컴퓨터의 파일은 페이지별로 수정할 수 있습니다. 도표와 비유를 통해 고객들이 다양한 워크로드에 따라 서로 다른 스토리지 유형이 필요한 이유를 이해하도록 도왔습니다. 자, 오늘은 그 차이에 융통성이 조금 더해졌습니다.
S3 Files 덕분에 Amazon S3는 데이터에 대한 모든 기능과 고성능 파일 시스템 액세스를 제공하는 최초이자 유일한 클라우드 객체 스토어가 되었습니다. 버킷에 파일 시스템처럼 액세스할 수 있습니다. 파일 시스템의 데이터 변경 사항이 S3 버킷에 자동으로 반영되며 동기화에 대한 미세 제어가 가능하기 때문입니다. S3 Files는 여러 컴퓨팅 리소스에 연결이 가능하기 때문에 데이터 중복 없이 클러스터 간에 데이터를 공유할 수 있습니다.
지금까지는 Amazon S3 비용, 내구성, 포함된 데이터를 기본적으로 사용할 수 있는 서비스 또는 파일 시스템의 대화형 기능 중에서 하나를 선택해야 했습니다. S3 Files에서는 이러한 절충이 사라집니다. S3는 모든 조직 데이터의 중앙 허브가 됩니다. 프로덕션 애플리케이션을 실행하든, 기계 학습 모델을 훈련하든, 에이전틱 AI 시스템을 구축하든, 모든 AWS 컴퓨팅 인스턴스, 컨테이너 또는 함수에서 바로 액세스할 수 있습니다.
Amazon Elastic Compute Cloud(Amazon EC2) 인스턴스, Amazon Elastic Container Service(Amazon ECS) 또는 Amazon Elastic Kubernetes Service(Amazon EKS)에서 실행되는 컨테이너, 또는 AWS Lambda 함수에서 기본 파일 시스템과 같은 범용 버킷에 액세스할 수 있습니다. 이 파일 시스템은 S3 객체를 파일과 디렉터리로 표시하며, 파일 생성, 읽기, 업데이트, 삭제 등 모든 네트워크 파일 시스템(NFS) v4.1 이상의 작업을 지원합니다.
파일 시스템을 통해 특정 파일과 디렉터리 작업을 할 때 관련 파일 메타데이터와 콘텐츠가 파일 시스템의 고성능 스토리지에 저장됩니다. 기본적으로 액세스 지연 시간이 짧으면 좋은 파일은 고성능 스토리지에 저장되고 제공됩니다. 대용량 순차 읽기가 필요한 파일처럼 고성능 스토리지에 저장되지 않은 파일의 경우, S3 Files는 처리량을 극대화하기 위해 Amazon S3에서 바로 파일을 제공합니다. 바이트 범위 읽기의 경우 요청된 바이트만 전송되므로 데이터 이동과 비용이 최소화됩니다.
또한 이 시스템은 사용자의 데이터 액세스 필요성을 예측하는 지능적인 사전 가져오기를 지원합니다. 또한 파일 시스템의 고성능 스토리지에 무엇을 저장할지 미세하게 제어할 수 있습니다. 파일 전체 데이터를 로드할지, 메타데이터만 로드할지 정할 수 있기 때문에 특정 액세스 패턴에 맞게 최적화할 수 있습니다.
내부적으로 S3 Files는 Amazon Elastic File System(Amazon EFS)을 사용하며 활성 데이터에 대해 1ms 이하의 지연 시간을 제공합니다. 이 파일 시스템에서는 NFS close-to-open 일관성으로 인해 여러 컴퓨팅 리소스에서 동시 액세스할 수 있습니다. 따라서 파일 기반 도구를 통해 협업하는 에이전틱 AI 에이전트부터 데이터세트를 처리하는 ML 훈련 파이프라인까지, 데이터를 변형하는 대화형 공유 워크로드에 이상적입니다.
시작하는 방법을 보여드리겠습니다.
간단하게 Amazon S3 파일 시스템을 처음 생성하고, 마운트하고, EC2 인스턴스에서 사용할 수 있습니다.
EC2 인스턴스와 범용 버킷이 있습니다. 이 데모에서는 일반 파일 시스템 명령을 사용하여 S3 파일 시스템을 구성하고 EC2 인스턴스에서 버킷에 액세스합니다.
이 데모에서는 AWS Management Console을 사용합니다. AWS Command Line Interface(AWS CLI) 또는 코드형 인프라(IaC)를 사용할 수도 있습니다.
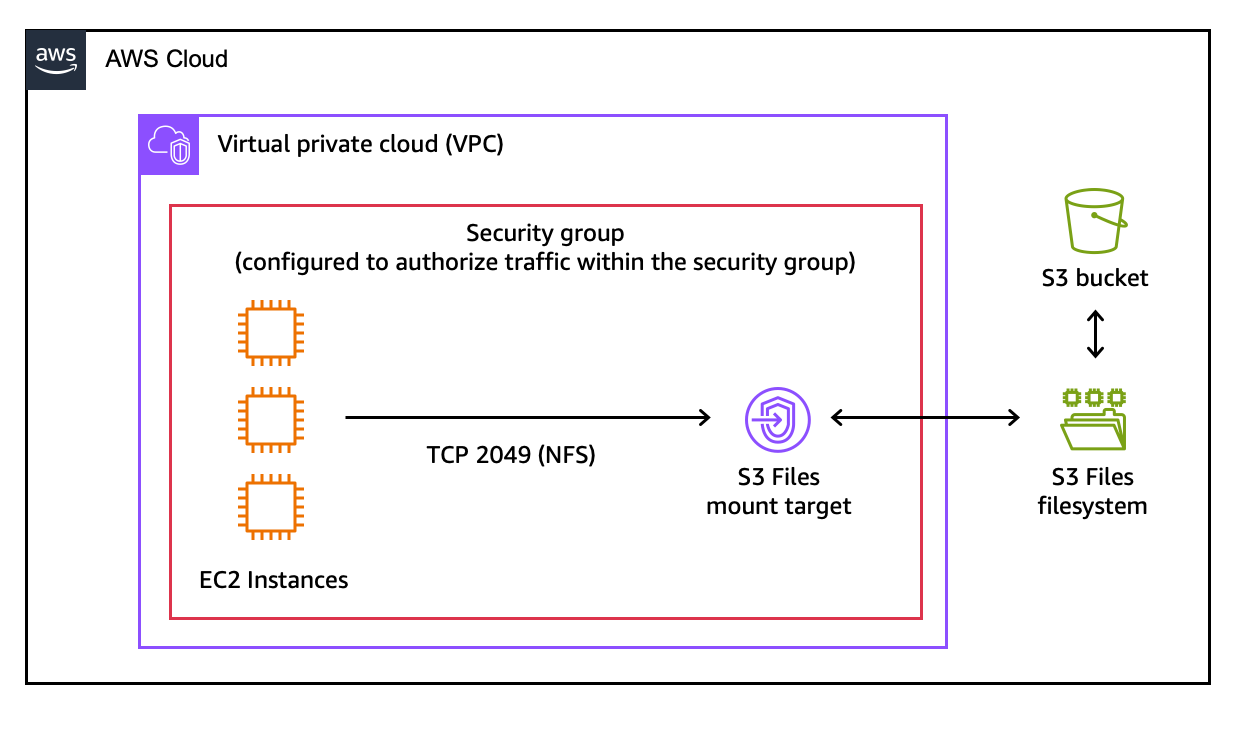
이 데모의 아키텍처 다이어그램입니다.
 1단계: S3 파일 시스템을 생성합니다.
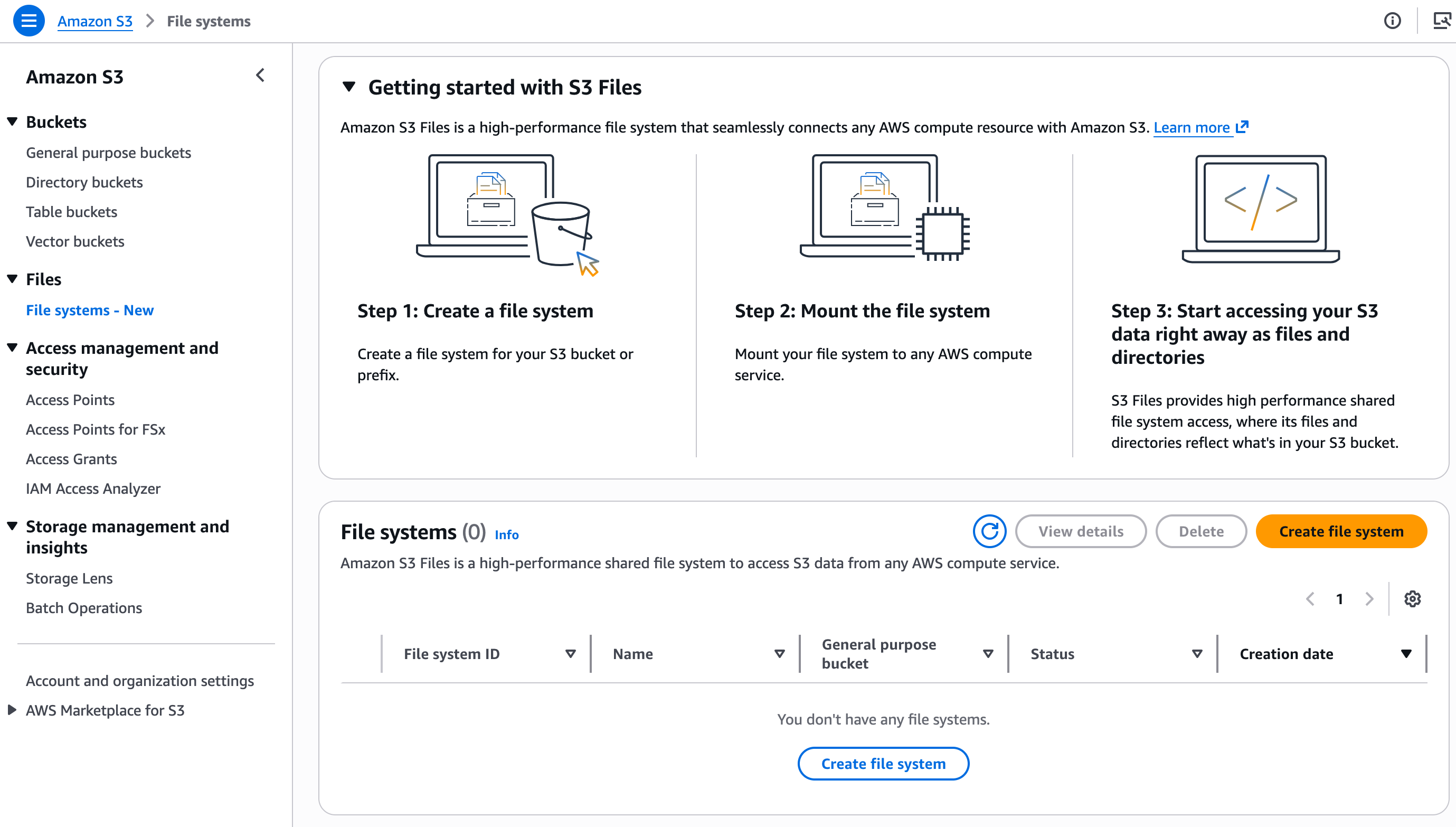
1단계: S3 파일 시스템을 생성합니다.
콘솔의 Amazon S3 섹션에서 File systems에 이어 Create file system을 선택합니다.
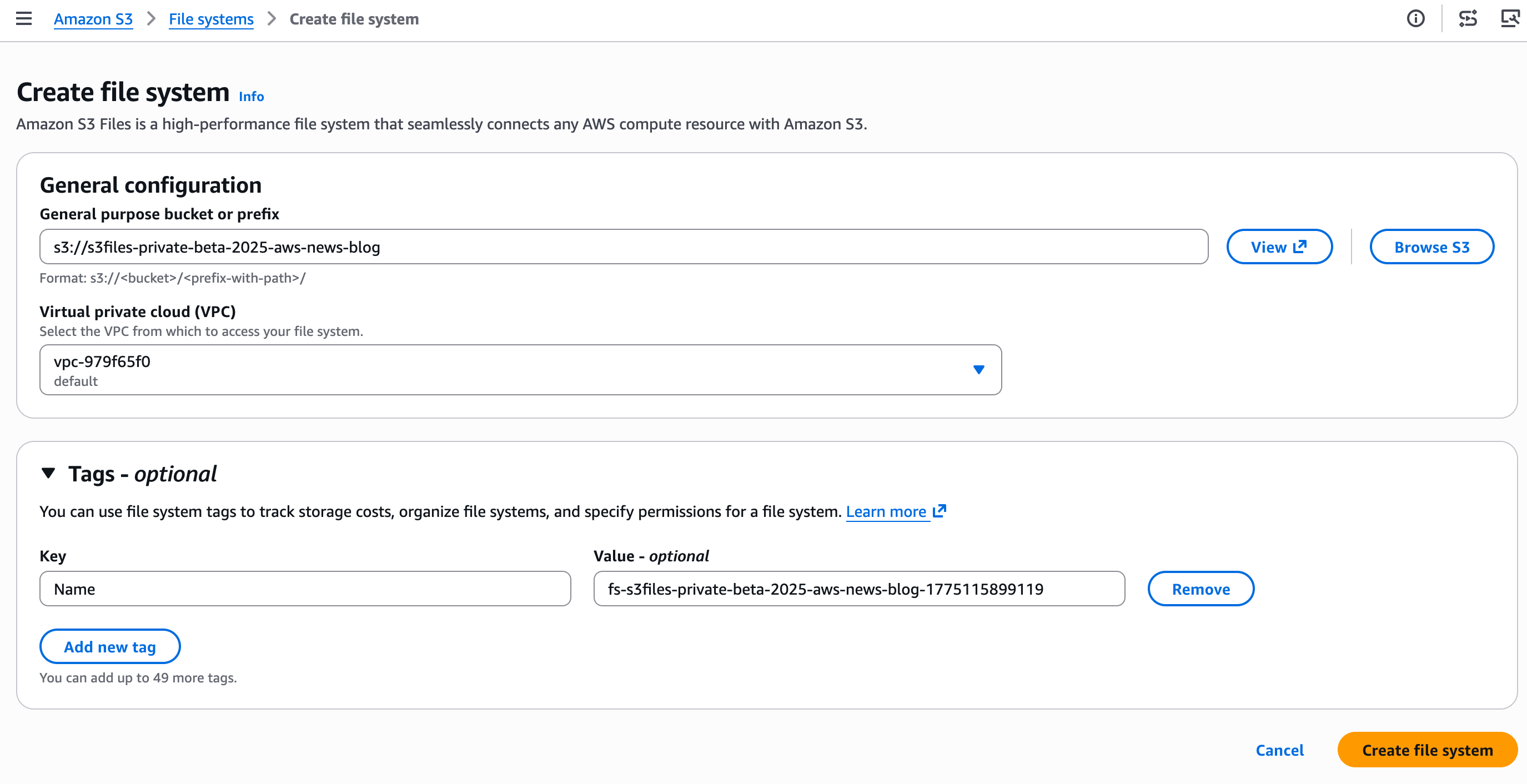
파일 시스템으로 노출하려는 버킷의 이름을 입력하고 Create file system을 선택합니다.
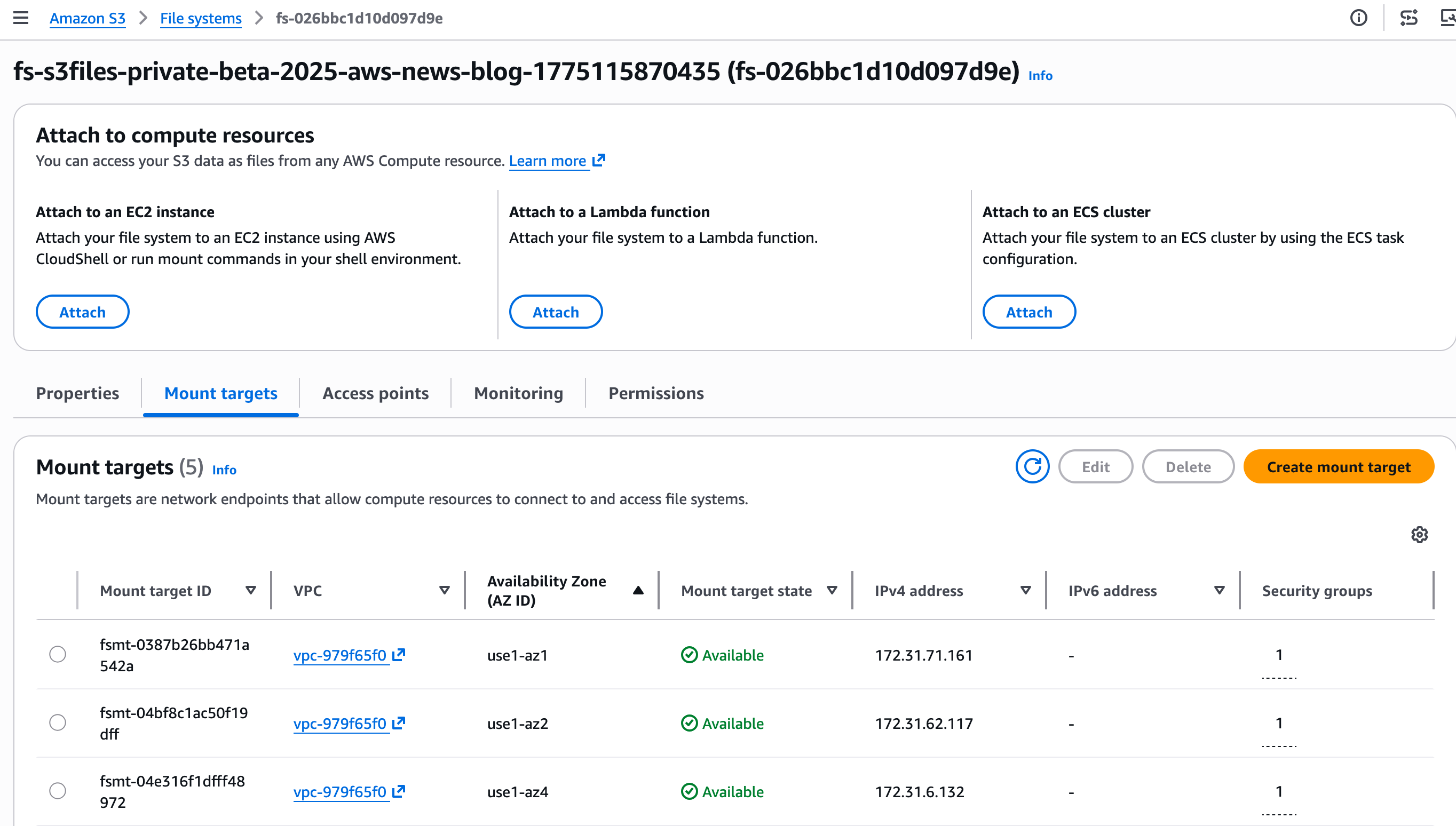
2단계: 마운트 대상을 검색합니다.
마운트 대상은 내 가상 프라이빗 클라우드(VPC)에 있을 네트워크 엔드포인트입니다. 이를 통해 내 EC2 인스턴스가 S3 파일 시스템에 액세스할 수 있습니다.
콘솔이 마운트 대상을 자동으로 생성합니다. Mount targets 탭의 Mount target ID를 기록해 둡니다.
CLI를 사용하는 경우, 파일 시스템과 마운트 대상을 생성하려면 2개의 개별 명령이 필요합니다. 먼저 create-file-system으로 S3 파일 시스템을 생성합니다. 그 다음, create-mount target으로 마운트 대상을 생성합니다.
3단계: 내 EC2 인스턴스에 파일 시스템을 마운트합니다.
EC2 인스턴스에 연결한 후 다음을 입력합니다.
sudo mkdir /home/ec2-user/s3files sudo mount -t s3files fs-0aa860d05df9afdfe:/ /home/ec2-user/s3files
이제 표준 파일 작업을 사용하여 ~/s3files에 마운트된 파일 시스템을 통해 직접 S3 데이터로 작업할 수 있습니다.
파일 시스템에서 내 파일을 업데이트하면 S3가 자동으로 모든 업데이트를 관리하고 새 객체 또는 기존 객체의 새 버전으로 내 S3 버킷에 몇 분 내에 내보냅니다.
S3 버킷의 객체에 대한 변경은 몇 초 내에 파일 시스템에 반영되지만, 경우에 따라 1분 이상 걸릴 수 있습니다.
# EC2 파일 시스템에 파일 생성
echo "Hello S3 Files" > s3files/hello.txt
# and verify it's here
ls -al s3files/hello.txt
-rw-r--r--. 1 ec2-user ec2-user 15 Oct 22 13:03 s3files/hello.txt
# 보시다시피 파일은 S3에도 있습니다
aws s3 ls s3://s3files-aws-news-blog/hello.txt
2025-10-22 13:04:04 15 hello.txt
# 그리고 내용은 동일합니다!
aws s3 cp s3://s3files-aws-news-blog/hello.txt . && cat hello.txt
Hello S3 Files알아야 할 사항
유용하다고 생각한 몇 가지 중요한 기술 정보를 공유하겠습니다.
- S3 Files는 액세스 제어와 암호화를 위해 AWS Identity and Access Management(IAM)와 통합됩니다. ID 및 리소스 정책을 사용하여 파일 시스템 수준과 객체 수준 모두에서 권한을 관리할 수 있습니다.
- 전송 중 데이터는 TLS 1.3을 사용하여, 저장 데이터는 Amazon S3 관리형 키(SSE-S3) 또는 AWS Key Management Service(AWS KMS)를 통한 고객 관리형 키를 사용하여 항상 암호화됩니다.
- S3 Files는 파일과 디렉터리에 대한 POSIX 권한을 사용하여 S3 버킷에 객체 메타데이터로 저장된 파일 권한의 사용자 ID(UID)와 그룹 ID(GID)를 확인합니다.
- Amazon CloudWatch 지표를 사용하여 S3 Files의 성능과 업데이트를 모니터링하고 AWS CloudTrail을 사용하여 관리 이벤트를 로깅합니다.
- EC2 인스턴스에 최신 버전의 EFS 드라이버(amazon-efs-utils 패키지)가 설치되어 있는지 확인합니다. 이 패키지는 AWS에서 제공하는 Amazon Machine Image(AMI)에 사전 설치되어 있습니다. 작성 시점에 최신 버전으로 업데이트할 수 있습니다.
- 이 게시물에서는 EC2 인스턴스에서 S3 Files를 사용하는 방법을 보여드렸습니다. AWS Fargate 사용 여부와 관계없이 ECS 또는 EKS 컨테이너 또는 Lambda 함수에서 S3 버킷을 파일 시스템으로 마운트할 수도 있습니다.
고객과의 대화에서 자주 듣는 또 한 가지 질문은 워크로드에 최적인 파일 서비스 선택에 관한 것입니다. 네, 아마 이렇게 생각하시겠죠. 중복되어 보이는 AWS 서비스들이 클라우드 아키텍트 분들의 아키텍처 검토 회의에서 재미를 주는 요소라고요. 제가 오해를 풀어드리겠습니다.
S3 Files는 고성능 파일 시스템 인터페이스를 통해 Amazon S3에 저장된 데이터에 대한 대화형 공유 액세스가 필요할 때 가장 효과적입니다. 프로덕션 애플리케이션, Python 라이브러리, CLI 도구를 사용하는 에이전틱 AI 에이전트, 기계 학습(ML) 훈련 파이프라인 등 여러 컴퓨팅 리소스가 데이터를 공동으로 읽고 쓰고 변형해야 하는 워크로드에 이상적입니다. 데이터 중복 없는 컴퓨팅 클러스터 간 공유 액세스, 1밀리초 미만의 지연 시간과 S3 버킷과의 자동 동기화 기능을 이용할 수 있습니다.
Amazon FSx는 온프레미스 NAS 환경에서 마이그레이션하는 워크로드에 필요한 익숙한 기능과 호환성을 제공합니다. Amazon FSx는 Amazon FSx for Lustre를 통한 GPU 클러스터 스토리지, 고성능 컴퓨팅(HPC)에도 이상적입니다. 특히 애플리케이션이 Amazon FSx for NetApp ONTAP, Amazon FSx for OpenZFS 또는 Amazon FSx for Windows File Server의 특정 파일 시스템 기능을 필요로 하는 경우에 유용합니다.
요금 및 가용성
S3 Files는 현재 모든 상용 AWS 리전에서 사용 가능합니다.
S3 파일 시스템에 저장된 데이터 용량, 작은 파일 읽기 및 파일 시스템에 대한 모든 쓰기 작업, 파일 시스템과 S3 버킷 간 데이터 동기화 중 발생하는 S3 요청 비용을 지불하면 됩니다. Amazon S3 요금 페이지에서 모든 세부 정보를 볼 수 있습니다.
고객들과의 대화를 통해 S3 Files가 데이터 사일로, 동기화 복잡성, 객체와 파일 간 수동 데이터 이동을 없애 클라우드 아키텍처를 단순화하는 데 도움이 된다고 생각했습니다. 이미 파일 시스템과 연동되는 프로덕션 도구를 실행하든, 파일 기반 Python 라이브러리와 쉘 스크립트에 의존하는 에이전틱 AI 시스템을 구축하든, ML 훈련을 위한 데이터세트를 준비하든, S3 Files를 사용하면 이러한 대화형, 공유형, 계층형 워크로드가 S3 데이터에 직접 액세스할 수 있습니다. Amazon S3의 내구성과 비용 효율성, 그리고 파일 시스템의 대화형 기능 사이에서 하나만 선택할 필요가 없습니다. 이제 Amazon S3를 조직의 모든 데이터를 저장하는 곳으로 사용하여 모든 AWS 컴퓨팅 인스턴스, 컨테이너, 함수에서 바로 데이터에 액세스할 수 있습니다.
자세한 내용과 시작 방법은 S3 Files 설명서를 참조하십시오.
이 새로운 기능을 어떻게 사용하시는지 듣고 싶습니다. 아래 댓글로 자유롭게 의견을 공유해 주시기 바랍니다.