AWS Storage Blog
Collecting, archiving, and retrieving surveillance footage with AWS
Video feeds and still images from judiciary locations are considered critical forms of evidence in the court of law. These locations can be police stations and government offices or even civil locations of importance like banks and hospitals. As governments, particularly in smart cities rely upon video surveillance, it is critical to design a cost optimized, highly secure system to archive surveillance feeds. It is important to archive these feeds for long-term retention and retrieval, as well as for regulatory compliance. It is paramount for customers using surveillance solutions to address the need to collect the data from different geographic locations, store data efficiently, and make decisions faster. These locations may or may not have network support, or may come with legacy camera installations. Furthermore, surveillance feeds from smart cities can also help deliver safe, secure, and sustainable cities. This can be done by contributing to lower crime rates, optimizing pedestrian and vehicle traffic flow, monitoring aggregate population movement trends, and enabling proactive response with real-time alerting to better serve the community and protect our environment.
In this blog, we discuss how to collect data from closed-circuit television (CCTV) cameras that are dispersed across a large geographic area. We then review how to centralize the data in Amazon S3 Glacier Deep Archive. We also showcase the path for retrieving the data from S3 Glacier Deep Archive. The Amazon S3 Glacier storage classes are purpose-built for data archiving. The S3 Glacier storage classes provide you with the highest performance, most retrieval flexibility, and the lowest cost archive storage in the cloud. All S3 Glacier storage classes provide virtually unlimited scalability and are designed for 99.999999999% (11 nines) of data durability. S3 Glacier Deep Archive provides secure and durable object storage for long-term retention and digital preservation for your data. We address the following source data paths in the proposed solution:
- Locations with old cameras sending feeds to a local Network Attached Storage (NAS)
- Locations with new IP-enabled camera installations
- Remote locations with slow or unreliable networks
Source data paths
Let’s first review the solution architecture for each source data path.
Collecting video feeds from locations with old cameras sending feeds to a local Network Attached Storage (NAS)
Although there are several methods to implement this solution, we focus on two approaches. The first is AWS Storage Gateway Hardware Appliance configured as Amazon S3 File Gateway (this is our preferred approach). S3 File Gateway provides a way to connect to AWS in order to store application data files and backup images as durable objects in Amazon S3. S3 File Gateway offers SMB or NFS-based access to data in Amazon S3. The second approach is to use a Network Attached Storage (NAS) from the AWS Marketplace that comes integrated with Amazon S3. The NAS vendor options in AWS Marketplace have S3 integration available, but integrating disparate NAS systems can be a daunting task. Integrating these systems can come with additional operational responsibilities like managing, monitoring, and administering different NAS technologies. Let’s look at both approaches to bring data from the old (non IP-enabled) cameras to Amazon S3.
Amazon S3 File Gateway
S3 File Gateway at the source data location provides the NFS/SMB compatible network file share. This file share exposes S3 objects to the local server on premises. The CCTV cameras are reconfigured to use the network file share created by S3 File Gateway at the primary storage location. The data stored on the file share syncs to the Amazon S3 bucket via AWS Direct Connect. The lifecycle transition rule configured on Amazon S3 Standard then moves the data to S3 Glacier Deep Archive.
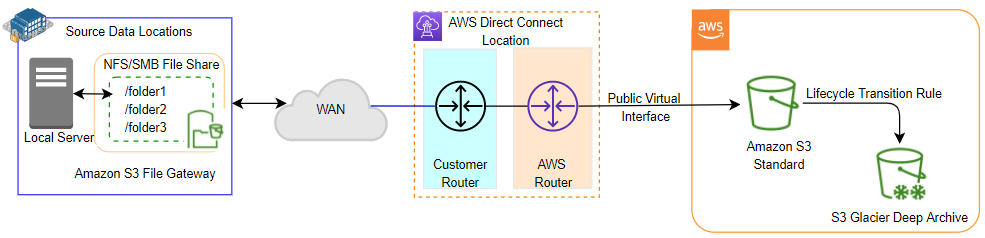
Figure 1: Data collection using Amazon S3 File Gateway at source
Network Attached Storage with Amazon S3 integration
As an alternative to S3 File Gateway, you can also locally use a network attached storage (NAS) device that has the capability to integrate with Amazon S3. Such network attached storage devices provide you with the capability to sync files between a local device and Amazon S3.
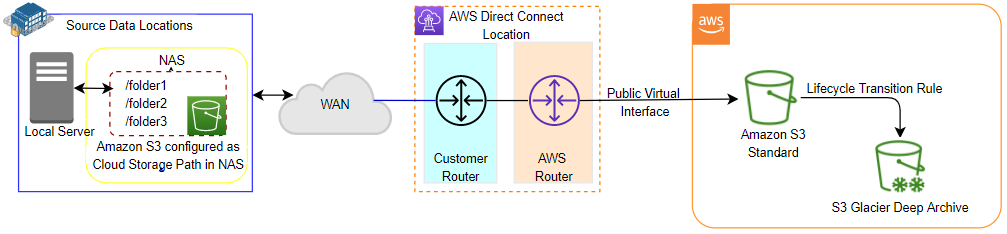
Figure 2: Data collection using Amazon S3 as the cloud storage path in a NAS device
Collecting video feeds from locations with IP-enabled cameras using Amazon Kinesis Video Streams
Ingest real-time live CCTV IP camera feeds into Amazon Kinesis Video Streams (KVS) by installing the Kinesis Video Streams SDK on your devices. Using KVS Producer libraries, the video from existing IP cameras can be fed into Amazon Kinesis Video Streams. You can develop a consumer application to use the KVS provided API for extracting media from KVS and storing it into your target S3 bucket. KVS endpoints are available over Direct Connect/Public Virtual Interface. Amazon Kinesis Video Streams uses Amazon S3 as the underlying data store, which means your data is stored durably and reliably. Amazon Kinesis Video Streams automatically indexes the data you store in your video streams. This indexing is based on timestamps generated by the device, or timestamps generated by Kinesis Video Streams when it receives the video. You can combine stream-level tags with timestamps to search and retrieve specific video fragments for playback, analytics, and other processing.

Figure 3: Data collection using Amazon Kinesis Video Streams Producer Library
Collecting video feeds from locations with slow or unreliable networks
AWS Snow Family offers a petabyte-scale data transport solution that uses secure, physical devices to move large amounts of data into and out of AWS. You can create a job in the AWS Snow Family console to send a Snowball Edge. Once a job is created, AWS ships a Snowball Edge to your location. When it arrives at your specified destination, attach it to your local network and transfer the data using the Snowball client or the Amazon S3 Adapter for Snowball. Once the device is ready to be returned, ship the Snowball Edge back to AWS, and we’ll import your data into Amazon S3. A Snowball Edge job can support up to 80 TB of data, and each job has exactly one Snowball Edge associated with it. For multiple terabytes of data, multiple devices can be used in parallel or clustered together to transfer petabytes of data. This provides you with continued availability of data storage at the source location.
For smaller data transport jobs, AWS Snowcone is the smallest member of the AWS Snow Family of secure edge computing, edge storage, and data migration devices. AWS Snowcone is available in two models. First is AWS Snowcone Hard Disk Drive (HDD) equipped with 8 TB of usable storage. Second is Snowcone Solid State Drive (SSD) supporting 14 TB of usable storage. Both Snowcones weigh only 4.5 pounds (2.1 kg). The Snowcone device is ruggedized, secure, and purpose-built for use outside of a traditional data center. Its small form factor makes it a perfect fit for tight spaces or where portability is a necessity and network connectivity is unreliable. You can use Snowcone to collect, process, and move data to AWS, either offline by shipping the device, or online with AWS DataSync from edge locations.
Once data is copied into Amazon S3, use Amazon S3 Lifecycle policies to manage your objects so that they are stored cost effectively throughout their lifecycle. An S3 Lifecycle configuration is a set of rules that define actions that Amazon S3 applies to a group of objects. There are two types of actions: Transition actions and Expiration actions that can be configured to transition data from S3 Standard to S3 Glacier Deep Archive as a data lifecycle rule.

Figure 4: Data collection and migration using AWS Snowball
Now that we have our data in S3 Glacier Deep Archive, let’s review the solution for retrieving the data from S3 Glacier Deep Archive.
Retrieving the specific video feed from S3 Glacier Deep Archive
Amazon DynamoDB is a NoSQL data store that can be used for storing the Amazon S3 object index. AWS Lambda is a compute service that can run code to add index entries to Amazon DynamoDB. Lambda will be triggered on an S3 event to extract the metadata of the incoming object and save it in Amazon DynamoDB.
The object restoration from S3 Glacier Deep Archive will follow this path:
- Your client-side browser calls the API, which in turn triggers the Lambda function.
- The Lambda function then gets the search index from Amazon DynamoDB.
- The Lambda function triggers the object restore request from S3 Glacier Deep Archive based on the index received from DynamoDB.
- S3 Glacier Deep Archive starts the object restore.
- Once the restore is complete, the restoration process will publish the notification to Amazon Simple Notification Service (Amazon SNS).
- Amazon SNS triggers another Lambda function that returns the S3 object URL to the API call made from the client-side browser. API response will be consumed by application code to download the object from Amazon S3 on the client-side browser.

Figure 5: Application flow to request object retrieval from S3 Glacier Deep Archive
Conclusion
For some customers, collecting surveillance feeds from different geographic locations and storing them securely for long-term retention and retrieval, while adhering to regulatory compliance, is vital. In this blog, we presented an end-to-end approach for long-term data archival and data retrieval to and from Amazon S3 Glacier Deep Archive. We covered the solution architectures for addressing the scenarios where you may have old non IP-enabled cameras, remote locations with no access to network, or new IP-enabled cameras. The blog also describes a solution that will help you retrieve your data from Amazon S3 Glacier Deep Archive based on the metadata associated with the data to be retrieved. For the use case discussed in this blog, ability to provide secure, reliable, and scalable solutions is extremely important.
AWS uses an end-to-end approach to secure and harden our Global Infrastructure including physical, operational, and software measures. Centralizing your data in Amazon S3 allows you to store all your structured and unstructured data at any scale. Data centralization in Amazon S3 opens the path for future innovation in field analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to provide you with more-informed decision making.
Thanks for reading this blog post! If you have any questions or suggestions, leave your feedback in the comments section.