AWS 기술 블로그
Category: Artificial Intelligence
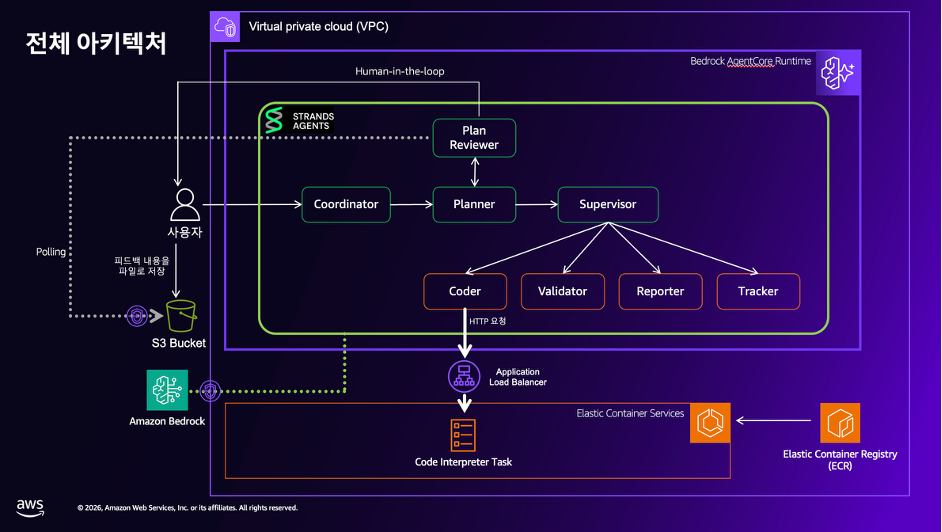
프로덕션 Multi-Agent 시스템이 해결해야 할 5가지 문제 – Deep Insight 아키텍처로 배우는 실전 설계
AI Agent를 만드는 것 자체는 이제 어렵지 않습니다. 오픈소스 프레임워크와 클라우드 서비스 덕분에 에이전트 구축 자체는 수일 내에 가능해졌고, 툴 호출 몇 개, 프롬프트 몇 줄이면 그럴듯한 에이전트를 만들 수 있습니다. 그러나 파일럿을 넘어 실제 비즈니스에 적용하려는 순간, 많은 팀들이 비슷한 벽에 부딪힙니다. Agent를 프로덕션에 적용하려다가 막힌 분들이라면 다음 고민들에 공감하실 것입니다. “왜 에이전트가 우리 비즈니스 […]

분산 트레이닝 관점에서의 AWS 인터커넥트 기술 소개 – AWS는 왜 인터커넥트 기술로 EFA를 사용하는가?
2025년 하반기부터 AWS에서 GPU 기반 분산 트레이닝 환경을 구축하는 고객이 급증하고 있습니다. 그럼에도 불구하고 많은 고객분들이 기존에 온프레미스 환경에서 사용되는 대표적인 인터커넥트 기술인 인피니밴드(Infiniband)와 AWS의 인터커넥트 기술의 차이점에 대해 명확히 이해하지 못하는 상황을 지켜보면서 이 블로그를 작성하게 되었습니다. 이번 블로그 시리즈에서는 AWS 클라우드 환경에서 분산 트레이닝 환경을 구축하고 운영하는데 필수적인 AWS의 인터커넥트 기술에 대해 소개하고자 […]

NVIDIA와 함께 AWS에서 자율주행 3.0을 위한 End-to-End Physical AI 데이터 파이프라인 구축하기
본 블로그는 Olivier Sutter, Geoff Van Natter, Mikhail Yurasov, Amrith Prabhu, Steven DeVries, Wonsik Han이 작성한 Building an End-to-End Physical AI Data Pipeline for Autonomous Vehicle 3.0 on AWS with NVIDIA를 번역, 편집하였으며, 이해를 돕기 위해 Note를 추가했습니다. 도입 자율주행(AV) 개발은 아키텍처 관점에서 명확한 세대 전환이 진행 중입니다. AV 1.0: 인지(Perception), 예측(Prediction), 계획(Planning), 제어(Control)로 이어지는 […]

클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 1부 – VoD환경에서의 비디오 분석 파이프라인 구축하기
소개 미디어, 광고, 교육 산업에서 비디오 콘텐츠는 폭발적으로 증가하고 있습니다. Cisco의 예측에 따르면 2022년 기준으로만 전체 인터넷 트래픽의 82%가 비디오가 될 것이라고 전망하였습니다.[1] 하지만 이 방대한 영상 자산에서 원하는 장면을 찾고, 콘텐츠를 분류하고, 인사이트를 추출하는 것은 여전히 어려운 과제입니다. 기존의 비디오 검색은 수동으로 입력한 메타데이터나 파일명에 의존했습니다. “2024년 마케팅 캠페인 영상”이라는 제목만으로는 그 안에 어떤 […]

Neptune GraphRAG Toolkit을 활용하여 정교한 비정형 데이터 검색하기
본 게시글은 AWS Database Blog에 게시된 ‘Introducing the GraphRAG Toolkit by Ian Robinson and Abdellah Ghassel’을 한국어 번역 및 편집하였습니다. Amazon Neptune이 그래프 기반 검색 증강 생성(RAG, Retrieval-Augmented Generation) 워크플로를 누구나 더 쉽게 구축할 수 있도록, Neptune 기반의 오픈 소스 Python 라이브러리 GraphRAG Toolkit을 선보였습니다. 이 툴킷은 비정형 데이터에서 자동으로 벡터 임베딩이 포함된 그래프를 구축하고, […]

Amazon Aurora PostgreSQL에서 Amazon Bedrock으로 벡터 임베딩 생성 자동화
본 블로그는 Domenico di Salvia와 Andrea Filippo La Scola가 작성한 블로그인 Automating vector embedding generation in Amazon Aurora PostgreSQL with Amazon Bedrock를 번역, 편집하였습니다. 벡터 임베딩은 생성형 AI를 활용하여 애플리케이션에서 비정형 데이터를 다루는 방식을 근본적으로 변화시켰습니다. 임베딩은 텍스트, 이미지 및 기타 콘텐츠의 본질을 머신이 효율적으로 처리할 수 있는 형태로 변환하는 수학적 표현 방식으로, 시맨틱 검색, […]

클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 2부 – 준실시간 환경에서 AWS 미디어 서비스를 활용한 분석 파이프라인 구축하기
소개 지난 1부에서는 ‘클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 1부 – VoD환경에서의 비디오 분석 파이프라인 구축하기’라는 주제를 다루었습니다. 2부에서는 영상의 분석과 의사결정이 빠르게 요구되는 환경에서 준실시간으로 비디오 분석 파이프라인을 구축하는 방안에 대해 다루겠습니다. 영상 데이터는 초 단위로 쌓이지만, 그 안에서 의미 있는 이벤트를 찾아내는 일은 여전히 쉽지 않습니다. 기존의 감시/모니터링 시스템은 […]

클라우드 환경에서의 비디오 인텔리전스 구현 : TwelveLabs로 시작하는 AI 영상 분석 5부 – 비디오 임베딩을 위한 Vector DB 비교
배경 이 블로그 시리즈에서는 TwelveLabs의 비디오 인텔리전스 기술을 AWS 클라우드 환경에서 활용하는 방법을 단계별로 살펴봤습니다. 1편과 2편에서는 VoD 및 준실시간 환경에서의 비디오 분석 파이프라인을 구축했고, 3편에서는 Strands Agent를 활용한 Agentic video engine을 구현했습니다. 그리고 4편에서는 Amazon Bedrock에서 제공하는 TwelveLabs Marengo 3.0의 멀티모달 임베딩 전략과 검색 방법론(Fused Embeddings, Score-based Fusion, RRF, Intent-based Routing)을 깊이 있게 다뤘습니다. […]

클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 4부 – TwelveLabs Marengo 3.0 임베딩 및 검색 전략과 구현 가이드
배경 비디오는 단순한 단일 데이터 스트림이 아닙니다. 시간 축을 따라 visual(화면 시각 정보), audio(소리 이벤트), speech/transcription(대화 내용)이 동시에 공존하는 복합 매체입니다. 따라서 비디오 검색 쿼리는 “완전히 시각적”이거나 “완전히 전사(transcription)”인 경우가 드뭅니다. 예를 들어, “Q3 세일즈 장표를 발표하는 여성의 모습”이라는 쿼리는 시각 정보, 대화 내용, 그리고 오디오 정보를 모두 포함해야 합니다. TwelveLabs의 Marengo 3.0은 모든 모달리티(비디오 […]

클라우드 환경에서의 비디오 인텔리전스 구현: TwelveLabs로 시작하는 AI 영상 분석 3부 – Strands Agent를 활용한 Agentic video engine구현
소개 지난 1부에서는 VoD 환경에서의 비디오 분석 파이프라인 구축을, 2부에서는 AWS 미디어 서비스를 활용한 준실시간 분석 파이프라인을 다루었습니다. 이번 3부에서는 한 단계 더 나아가, AI 에이전트가 스스로 판단하고 도구를 선택하여 영상을 분석하는 에이전틱(Agentic) 비디오 엔진을 구축하는 방법을 소개합니다. 기존 1부와 2부의 파이프라인은 미리 정해진 순서대로 영상을 임베딩하고 검색하는 고정된 워크플로 방식이었습니다. 하지만 실제 영상 분석 […]