AWS 기술 블로그
SAP 데이터와 AWS Glue를 활용하여 RISE 워크로드 확장하기
이 글은 AWS Big Data Blog에 게시된 ‘Scaling RISE with SAP data and AWS Glue’를 번역했습니다.
고객은 종종 원본 SAP 데이터를 다른 소스 데이터로 확장하거나 보강하기를 원합니다. 이러한 분석 사용 사례는 데이터 웨어하우스 또는 데이터 레이크를 구축하여 구현할 수 있습니다. 이제 고객은 AWS Glue SAP OData 커넥터를 사용해 SAP에서 데이터를 추출할 수 있습니다. SAP OData 커넥터는 온프레미스 및 클라우드 호스팅(네이티브 및 SAP RISE) 배포를 모두 지원합니다. SAP용 AWS Glue OData 커넥터를 사용하면 AWS Glue 및 Apache Spark에서 데이터를 분산된 방식으로 원활하게 작업하고 효율적으로 처리할 수 있습니다. AWS Glue는 분석, 머신 러닝(ML) 및 애플리케이션 개발을 위해 다양한 소스에서 데이터를 더 쉽게 검색, 준비, 이동 및 통합할 수 있게 해주는 서버리스 데이터 통합 서비스입니다.
SAP용 AWS Glue OData 커넥터는 데이터 추출을 위해 SAP ODP 프레임워크와 OData 프로토콜을 사용합니다. 이 프레임워크는 제공자-구독자 모델로 작동하며, SAP 시스템과 비 SAP 데이터 대상 간에 데이터 전송을 가능하게 합니다. ODP(Operational Data Provisioning) 프레임워크는 운영 델타 큐(Operational Delta Queue) 메커니즘을 통해 전체 데이터 추출 및 변경 데이터 캡처를 지원합니다. SAP 데이터 추출을 위해 다양한 소스를 활용할 수 있습니다. 이러한 소스에는 SAP data extractor, ABAP CDS 뷰, 다양한 BW 소스, HANA information views 및 ODP 지원 데이터 소스 등이 있습니다.
SAP 소스 시스템은 과거 데이터를 보관하고 있거나 지속적인 업데이트가 발생할 수 있습니다. 따라서 소스 변경사항의 증분 처리를 활성화하는 것이 중요합니다. 이 블로그 이 블로그 포스트는 SAP에서 데이터를 추출하는 방법과 SAP ODP OData 프레임워크를 활용한 증분 데이터 전송 구현 방법에 대해 자세히 설명합니다. 특히 소스 델타 토큰을 사용하여 SAP 소스에서 효율적으로 데이터를 전송하는 방법을 다룹니다.
솔루션 개요
한 회사가 SAP 소스 시스템에 저장된 제품 데이터를 분석하고자 합니다. 현재 제공되는 제품, 특히 각 자재 그룹에 있는 제품 수를 파악하고자 합니다. 이를 위해 SAP 시스템의 자재 마스터 데이터와 회사에서 보유한 자재 그룹 데이터 소스의 조인이 필요합니다. 자재 마스터 데이터는 증분 추출로 이용 가능한 반면, 자재 그룹은 전체 로드로만 이용 가능합니다. 이러한 데이터 소스들은 분석을 위한 쿼리에 사용할 수 있도록 결합되어야 합니다.
사전 요구사항
이 게시물에 제시된 솔루션을 완료하기 위해, 다음과 같은 사전 요구사항 단계를 완료해야 합니다.
- SAP 시스템의 SAP Gateway에서 추출을 위한 ODP(Operational Data Provisioning) 데이터 소스를 구성합니다.
- SAP 데이터를 저장할 Amazon Simple Storage Service(Amazon S3) 버킷을 생성합니다.
- AWS Glue Data Catalog에서
sapgluedatabase라는 데이터베이스를 생성하세요. - AWS Glue 추출, 변환 및 로드(ETL) 작업이 사용할 AWS Identity and Access Management(IAM) 역할을 생성하세요. 이 역할은 Amazon S3 및 AWS Secrets Manager를 포함하여 작업이 사용하는 모든 리소스에 대한 액세스 권한을 부여해야 합니다. 이 게시물의 솔루션에서는 역할 이름을
GlueServiceRoleforSAP로 지정하세요.
다음 정책을 사용하세요.- AWS 관리형 정책
- 인라인 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObjectAcl",
"s3:GetObject",
"s3:GetObjectAttributes",
"s3:ListBucket",
"s3:DeleteObject",
"s3:PutObjectAcl"],
"Resource": [
"arn:aws:s3:::<S3-BUCKET-NAME>",
"arn:aws:s3:::<S3-BUCKET-NAME>/*"
]
}
]
}SAP를 위한 AWS Glue 커넥션 생성하기
SAP 커넥터는 CUSTOM(SAP 기본 인증) 및 OAUTH 인증 방법을 모두 지원합니다. 이 예시에서는 기본 인증으로 연결합니다.
1. AWS 관리 콘솔에서 AWS 시크릿 매니저를 사용하여 SAP 소스에 대해 ODataGlueSecret이라는 시크릿을 생성합니다. AWS 시크릿 매니저의 세부 정보에는 다음 코드의 요소가 포함되어야 합니다. <your SAP username> 대신에 SAP 시스템 사용자 이름을, <your SAP username password> 대신에 해당 비밀번호를 입력해야 합니다.
{
"basicAuthUsername": "<your SAP username>",
"basicAuthPassword": "<your SAP username password>",
"basicAuthDisableSSO": "True",
"customAuthenticationType": "CustomBasicAuth"
}
2. 새 SAP OData 데이터 소스를 선택하여 SAP 시스템에 대한 AWS Glue 커넥션 GlueSAPOdata를 생성합니다.

3. 사용자의 SAP 소스에 해당하는 적합한 값을 입력하여 커넥션을 구성합니다.
- Application host URL: 호스트는 SAP 호스트 이름의 인증 및 유효성 검사를 위한 SSL 인증서를 가지고 있어야 합니다.
- Application service path:
/sap/opu/odata/iwfnd/catalogservice;v=2; - Port number: SAP 소스 시스템의 포트 번호
- Client number: SAP 소스 시스템의 클라이언트 번호
- Logon language: SAP 소스 시스템에서 사용하는 로그온 언어
4. 인증 섹션에서 인증 유형(Authentication Type)으로 사용자 지정(CUSTOM)을 선택합니다.
5. 전 단계에서 생성한 AWS Secret인 SAPODataSecret을 선택합니다.

6. 네트워크 옵션으로는 사용자의 SAP 시스템 연결에 사용된 VPC, 서브넷 그리고 보안 그룹을 선택합니다. SAP 시스템 연결에 대한 자세한 설명은 Configure a VPC for your ETL job 링크를 확인하세요.
SAP 데이터 수집을 위한 ETL 작업 생성
AWS Glue 콘솔에서 새 Visual Editor AWS Glue 작업을 생성합니다.
1. AWS Glue 콘솔로 이동합니다.
2. ETL Jobs 아래의 탐색 창에서 Visual ETL을 선택합니다.
3. Visual ETL을 선택하여 시각적 편집기에서 작업을 생성합니다.
4.이 게시물에서는 기본 이름값을 Material Master Job으로 편집하고 저장을 클릭합니다.
화면 상에서 SAP 소스를 선택합니다.
5. Visual 탭을 선택한 다음 ‘+’ 기호를 선택하여 노드 추가 메뉴를 엽니다. SAP를 검색하고 SAP OData Source를 추가합니다.

6. 방금 추가한 노드를 선택하고 이름을 Material Master Attributes로 지정합니다.
- SAP OData Connection의 경우 GlueSAPOData 연결을 선택합니다.
- SAP 소스에서 자재 속성, 서비스 및 엔티티 세트를 선택합니다.
- Entity Name과 Sub Entity Name의 경우, SAP 소스에서 SAP OData 엔티티를 선택합니다.
- 필드에서 Material, Created on, Material Group, Material Type, Old Matl number, GLUE_FETCH_SQ 및 DML_STATUS를 선택합니다.
- 필터 섹션에 limit 100을 입력하여 데이터를 제한합니다.
이 서비스는 델타 추출을 지원하므로 증분 전송이 기본 선택 옵션입니다.

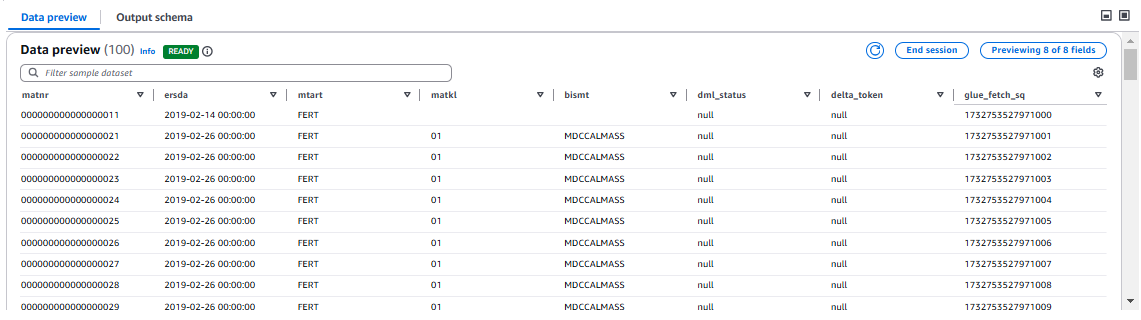
AWS Glue 서비스 역할을 선택하면 데이터 미리 보기를 할 수 있습니다. 미리 보기에 아래 3가지 신규 필드를 확인할 수 있습니다:
glue_fetch_sq: 이것은 레코드가 수신된 순서대로 EPOC 타임스탬프에서 생성되는 시퀀스 필드이며 각 레코드마다 고유합니다. 소스 시스템의 변경 순서를 파악하거나 설정해야 하는 경우에 사용할 수 있습니다.delta_token: 마지막으로 전달된 레코드를 제외한 모든 레코드는 이 필드 값이 비어 있으며, 여기에는 변경된 레코드 캡처(CDC)를 하기 위한 ODQ 토큰의 값이 포함됩니다. 이 레코드는 소스의 트랜잭션 레코드가 아니며 델타 토큰 값을 전달하기 위한 목적으로만 존재합니다.dml_status: 소스에서 새로 삽입되고 업데이트된 모든 레코드에 대해서 ‘UPDATED’가 표시되고 소스에서 삭제된 레코드에 대해서는 ‘DELETED’가 표시됩니다.
델타를 활성화하고 데이터를 추출한 경우, 전달된 마지막 레코드에 DELTA_TOKEN 값이 포함되고 그 값은 위에 설명한 방식대로 채워집니다.
7. SAP ODATA 소스 커넥션을 추가하고 해당 노드의 이름을 Material Group Text로 입력합니다.
- SAP 소스에서 자재 그룹 서비스와 엔티티 세트를 선택합니다.
- Entity Name과 Sub Entity Name으로 SAP 소스의 SAP OData 엔티티를 선택합니다.
해당 서비스는 전체 추출을 지원합니다. 따라서 Full transfer가 기본 옵션 값입니다. 해당 데이터셋을 미리보기로 볼 수 있습니다.

8. 데이터 미리보기 시, 언어 키(language key)를 확인합니다. SAP는 모든 언어를 패스함으로 Filter값으로 SPRAS = ‘E’를 입력하여 영어만 추출하도록 설정합니다. 이것은 SAP 내부 필드 값을 사용하는 것입니다.

9. Material Group Text를 Node parents인 변환 노드(transform node)를 추가하고 이름은 Change Schema를 입력합니다.
- Target key 필드의 자재 그룹을 matkl2로 변경하여 첫번째 소스와 다르도록 합니다.
- Drop 체크 박스에 spras, odq_changemode, odq_entitycntr, dml_status, delta_token, glue_fetch_sq를 선택합니다.

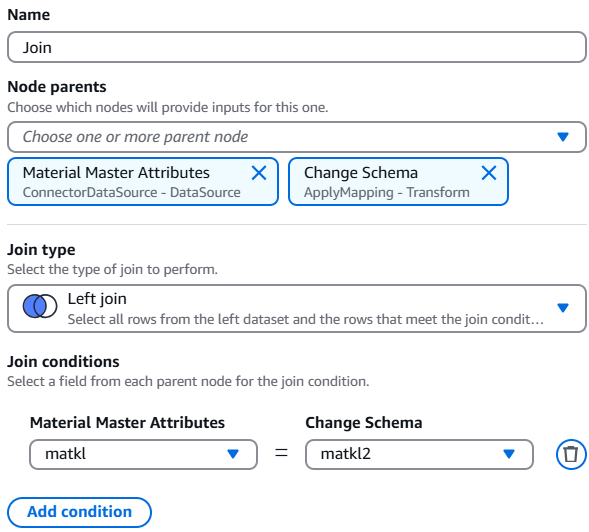
10. join 변환 노드를 선택하고 2개의 소스 데이터를 선택합니다.
- Material Master Attributes와 Change Schema가 Node parents로 선택됐는지 확인합니다.
- Join type은 Left join을 선택합니다.
- join conditions는 각 소스에서의 주요 키값들을 선택합니다.
- Material Master Attributes에서
matkl을 선택 - Change Schema에서
matkl2을 선택
- Material Master Attributes에서
미리 보기를 통해 올바른 데이터가 반환되는 것을 확인합니다. 이제 결과를 저장할 준비가 되었습니다.
11. S3 bucket을 Target으로하는 노드를 생성합니다.
- Node Parents는 Join인 것을 확인합니다.
- 포맷은 Parquet입니다.
- S3 Target Location으로 사전에 생성한 S3버킷을 선택하고 이어서
materialmaster/를 입력합니다. - Data Catalog update options는 Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions를 선택합니다.
- Database는 앞서 생성한 AWS Glue database인 sapgluedatabase를 선택합니다.
- Table name은
materialmaster을 입력합니다.

12. Save를 클릭하여 생성한 작업을 저장합니다. 최종 생성한 작업은 아래와 같습니다.

ETL 작업을 복제하고 증분 처리되도록 설정
ETL 작업이 생성되면 작업을 복제하고 델타 토큰을 사용하여 증분 데이터 처리를 하도록 설정할 수 있습니다.
이를 위해 작업 스크립트를 직접 수정해야 합니다. 스크립트를 수정하여 마지막 델타 토큰을 검색하는 명령문(작업 태그에 저장될 토큰)을 추가하고, 요청(또는 작업 실행)에 델타 토큰 값을 추가해야 합니다. 이렇게 하면 다음 작업 실행 시 데이터를 검색할 때 델타 지원 SAP OData 서비스가 활성화됩니다.
작업의 첫 번째 실행에서는 태그에 델타 토큰 값이 없을 것입니다. 따라서 이 호출은 초기 실행이라는 것이며, 이후 실행 결과에는 델타 토큰이 태그에 저장될 것입니다.
1. AWS Glue 콘솔로 이동합니다.
2. 좌측 ETL Jobs에서 Visual ETL을 선택합니다.
3. Material Master Job을 선택하고 Actions 탭에서 Clone job을 선택합니다.

4. 작업 명을 Material Master Job Delta으로 입력하고 Script탭을 선택합니다.
5. 각 작업 실행에 대한 델타 토큰의 저장 및 검색을 처리할 파이썬 라이브러리를 추가해야 합니다. 이렇게 하려면 Job Details 탭으로 이동하여 아래로 스크롤하여 Advanced Properties 섹션을 펼칩니다.
Python library path에 다음 경로를 추가합니다:
s3://aws-blogs-artifacts-public/artifacts/BDB-4789/sap_odata_state_management.zip

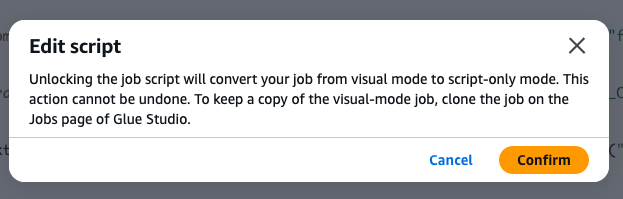
6. 이제 Script tab을 선택하고 우측 Edit script를 선택합니다. Confirm을 클릭하여 작업이 script-only인 것을 확정합니다.
델타 토큰을 활성화하기 위해 아래 변경 내용을 적용합니다.
1. 8번째 행에 아래 코드를 추가함으로써 Step5에서 추가한 SAP OData 상태 관리 라이브러리 클래스를 호출합니다.
from sap_odata_state_management.state_manager import StateManagerFactory, StateManagerType, StateType
2. 다음 단계에서는 작업 태그에서 델타 토큰을 검색하고 저장하여 후속 작업 실행에서 접근할 수 있도록 합니다. 델타 토큰은 SAP 소스로 돌아가는 요청에 추가되어 이를 통해 증분 변경사항이 추출됩니다. 전달된 토큰이 없는 경우 로드는 초기 로드로 실행되고 토큰은 다음 실행 시 델타 로드가 될 때까지 유지됩니다.
sap_odata_state_management 라이브러리를 초기화하기 위해, 연결 옵션을 변수로 추출하고 상태 관리자를 사용하여 업데이트하세요. 이를 위해 다음 코드를 16번 줄(job.init 문 이후)에 추가하세요.
<key of MaterialMasterAttributes node>와 <entityName for Material Attribute> 값은 # Script generated for node Material Master Attributes 아래 생성된 스크립트에서 찾을 수 있습니다. 해당 값을 실제 값으로 대체합니다.
key = "<key of MaterialMasterAttributes node>"
state_manager = StateManagerFactory.create_manager(
manager_type=StateManagerType.JOB_TAG, state_type=StateType.DELTA_TOKEN, options={"job_name": args['JOB_NAME'], "logger": glueContext.get_logger()}
)
options = {
"connectionName": "GlueSAPOData",
"entityName": "<entityName for Material Attribute>",
"ENABLE_CDC": "true"
}
connector_options = state_manager.get_connector_options(key)
options.update(connector_options)3. Material Master Attributes 에 대해 생성된 기존 스크립트 앞에 #을 추가하여 주석 처리하고, 그 자리에 새로운 대체 스니펫을 추가하세요.
<key of MaterialMasterAttributes node> = glueContext.create_dynamic_frame.from_options(connection_type="sapodata", connection_options=options, transformation_ctx="<key of MaterialMasterAttributes node>")4. 델타 토큰을 동적 프레임에서 추출하고 작업 태그에 저장하기 위해, 스크립트의 마지막 줄(job.commit() 전) 바로 위에 다음 코드 스니펫을 추가하세요
state_manager.update_state(key, <key of MaterialMasterAttributes node>.toDF())아래는 최종 스크립트입니다.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from sap_odata_state_management.state_manager import StateManagerFactory, StateManagerType, StateType
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
key = "MaterialMasterAttributes_node1730873953236"
state_manager = StateManagerFactory.create_manager(
manager_type=StateManagerType.JOB_TAG, state_type=StateType.DELTA_TOKEN, options={"job_name": args['JOB_NAME'], "logger": glueContext.get_logger()}
)
options = {
"connectionName": "GlueSAPOData",
"entityName": "/sap/opu/odata/sap/ZMATERIAL_ATTR_SRV/EntityOf0MATERIAL_ATTR",
"ENABLE_CDC": "true"
}
# Script generated for node Material Group Text
MaterialGroupText_node1730874412841 = glueContext.create_dynamic_frame.from_options(connection_type="sapodata", connection_options={"ENABLE_CDC": "false", "connectionName": "GlueSAPOData", "FILTER_PREDICATE": "SPRAS = 'E'", "ENTITY_NAME": "/sap/opu/odata/sap/ZMATL_GROUP_SRV/EntityOf0MATL_GROUP_TEXT"}, transformation_ctx="MaterialGroupText_node1730874412841")
# Script generated for node Material Master Attributes
#MaterialMasterAttributes_node1730873953236 = glueContext.create_dynamic_frame.from_options(connection_type="sapodata", connection_options={"ENABLE_CDC": "true", "connectionName": "GlueSAPOdata", "FILTER_PREDICATE": "limit 100", "SELECTED_FIELDS": "MATNR,MTART,MATKL,BISMT,ERSDA,DML_STATUS,DELTA_TOKEN,GLUE_FETCH_SQ", "ENTITY_NAME": "/sap/opu/odata/sap/ZMATERIAL_ATTR_SRV/EntityOf0MATERIAL_ATTR"}, transformation_ctx="MaterialMasterAttributes_node1732755261264")
MaterialMasterAttributes_node1730873953236 = glueContext.create_dynamic_frame.from_options(connection_type="sapodata", connection_options=options, transformation_ctx="MaterialMasterAttributes_node1730873953236")
# Script generated for node Change Schema
ChangeSchema_node1730875214894 = ApplyMapping.apply(frame=MaterialGroupText_node1730874412841, mappings=[("matkl", "string", "matkl2", "string"), ("txtsh", "string", "txtsh", "string")], transformation_ctx="ChangeSchema_node1730875214894")
# Script generated for node Join
MaterialMasterAttributes_node1730873953236DF = MaterialMasterAttributes_node1730873953236.toDF()
ChangeSchema_node1730875214894DF = ChangeSchema_node1730875214894.toDF()
Join_node1730874996674 = DynamicFrame.fromDF(MaterialMasterAttributes_node1730873953236DF.join(ChangeSchema_node1730875214894DF, (MaterialMasterAttributes_node1730873953236DF['matkl'] == ChangeSchema_node1730875214894DF['matkl2']), "left"), glueContext, "Join_node1730874996674")
# Script generated for node Amazon S3
AmazonS3_node1730875848117 = glueContext.write_dynamic_frame.from_options(frame=Join_node1730874996674, connection_type="s3", format="json", connection_options={"path": "s3://sapglueodatabucket", "compression": "snappy", "partitionKeys": []}, transformation_ctx="AmazonS3_node1730875848117")
state_manager.update_state(key, MaterialMasterAttributes_node1730873953236.toDF())
job.commit()5. Save를 클릭하여 변경 사항을 저장합니다.
6. Run을 클릭하여 작업을 시행합니다. 현재는 작업 세부사항에 태그가 존재하지 않습니다.
7. 작업이 성공적으로 완료될 때까지 기다립니다. 작업 상태를 Runs 탭에서 확인할 수 있습니다.
8. 작업이 끝나면 Job Details 탭에 태그가 추가된 것을 확인할 수 있습니다. 다음 작업은 해당 토큰을 읽어 델타 로드를 시행시킬 것입니다.

SAP 데이터 소스 쿼리
AWS Glue 작업이 실행되어 데이터 카탈로그에 항목을 생성하였으므로 데이터를 즉시 쿼리할 수 있습니다.
1. Amazon Athena 콘솔로 이동합니다.
2. Launch Query Editor를 클릭합니다.
3. 적합한 workgroup을 선택하거나 create a workgroup을 클릭하여 신규 생성합니다.
4. sapgluedatabase을 선택하고 아래와 같은 쿼리를 실행하고 데이터를 확인합니다.
select matkl, txtsh, count(*)
from materialmaster
group by 1, 2
order by 1, 2;

정리하기
발생하는 비용을 방지하기 위해 AWS 계정에서 사용한 AWS Glue 작업, SAP OData 커넥션, Glue 데이터 카탈로그, Secrets Manager secret, IAM 역할, S3 bucket에 저장된 콘텐츠, 그리고 S3 버킷을 리소스를 정리합니다.
결론
이 게시물에서는 여러 SAP 데이터 소스에 대해 서버리스 기반의 증분 데이터 로드 프로세스를 구성하는 방법을 보여드렸습니다. 접근 방식으로는 AWS Glue에서 SAP ODP 델타 토큰을 사용해 SAP 소스에서 데이터를 증분 로드하고 데이터를 Amazon S3로 저장하였습니다.
서버리스 서비스인 AWS Glue의 특성상 인프라 관리가 필요 없으며, 작업이 실행되는 동안 소비된 리소스에 대해서만 비용을 지불하면 됩니다(내용물 저장을 위한 스토리지 비용도 추가).조직들이 점점 더 데이터 기반으로 운영됨에 따라, SAP 커넥터는 SAP 소스 데이터를 효율적이고 안전한 방식으로 통합하여 빅데이터 분석과 인사이트 도출에 도움이 되는 방법을 제공합니다. 자세한 내용은 AWS Glue를 참조하세요.