시작하기 리소스 센터 / 10분 자습서 / ...
자동으로 기계 학습 모델 생성
Amazon SageMaker Autopilot 사용
완전관리형 서비스인 Amazon SageMaker를 사용하면 모든 개발자 및 데이터 과학자가 기계 학습(ML) 모델을 빠르게 구축하고, 구축한 모델을 훈련시키고 배포할 수 있습니다.
이 자습서에서는 코드를 전혀 작성하지 않고 기계 학습 모델을 자동으로 생성합니다. 완벽한 제어와 확인이 가능한 최적의 분류 및 회귀 기계 학습 모델을 자동으로 생성하는 AutoML 기능인 Amazon SageMaker Autopilot을 사용하면 됩니다.
이 자습서에서는 다음 작업을 수행하는 방법을 배웁니다.
- AWS 계정 생성
- Amazon SageMaker Autopilot에 액세스할 수 있도록 Amazon SageMaker Studio 설정
- Amazon SageMaker Studio를 사용하여 퍼블릭 데이터 세트 다운로드
- Amazon SageMaker Autopilot을 사용하여 훈련 실험 생성
- 훈련 실험의 각 단계 살펴보기
- 훈련 실험에서 성능이 가장 우수한 모델 확인 및 배포
- 배포한 모델을 사용하여 예측
이 자습서에서는 여러분이 은행에서 일하는 개발자라고 가정합니다. 여러분은 고객이 예금 증서(CD)에 등록할지 예측하는 기계 학습 모델 개발 요청을 받았습니다. 모델은 고객 인구 통계 정보, 마케팅 행사에 대한 반응, 외부 요소에 대한 정보가 포함된 마케팅 데이터 세트로 훈련됩니다.
| 자습서 소개 | |
|---|---|
| 시간 | 10분
|
| 요금 | 10 USD 미만 |
| 사용 사례 | Machine Learning |
| 제품 | Amazon SageMaker |
| 대상 | 개발자 |
| 레벨 | 초보자 |
| 최종 업데이트 날짜 | 2020년 5월 12일 |
1단계. AWS 계정 생성
이 워크샵의 요금은 10 USD 미만입니다. 자세한 내용은 Amazon SageMaker Studio 요금을 참조하세요.
2단계. Amazon SageMaker Studio 설정
다음 단계에 따라 Amazon SageMaker Autopilot 액세스를 위해 Amazon SageMaker Studio에 온보딩합니다.
참고: 자세한 내용은 Amazon SageMaker 설명서에서 Amazon SageMaker Studio 시작하기를 참조하세요.
a. Amazon SageMaker 콘솔에 로그인합니다.
참고: 콘솔 오른쪽 위에서 Amazon SageMaker Studio를 사용할 수 있는 AWS 리전을 선택해야 합니다. 리전 목록은 Amazon SageMaker Studio에 온보딩을 참조하세요.


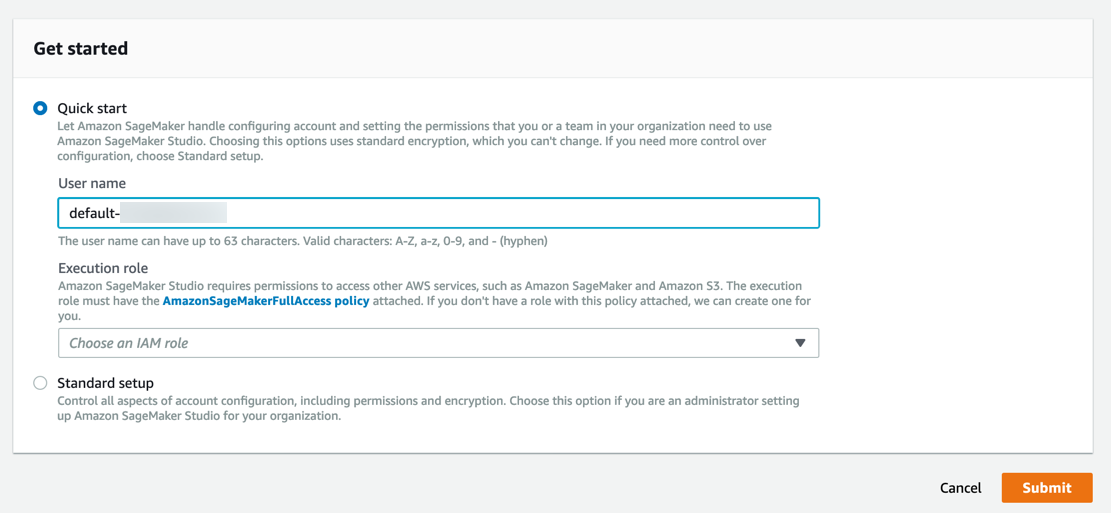
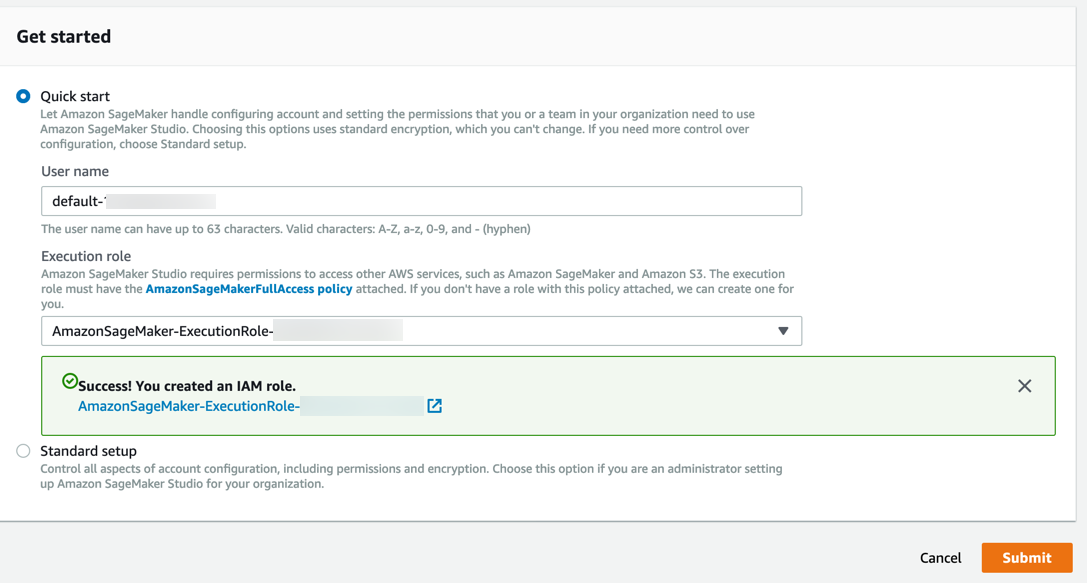
Amazon SageMaker에서 필요한 권한이 있는 역할이 생성되어 인스턴스에 할당됩니다.
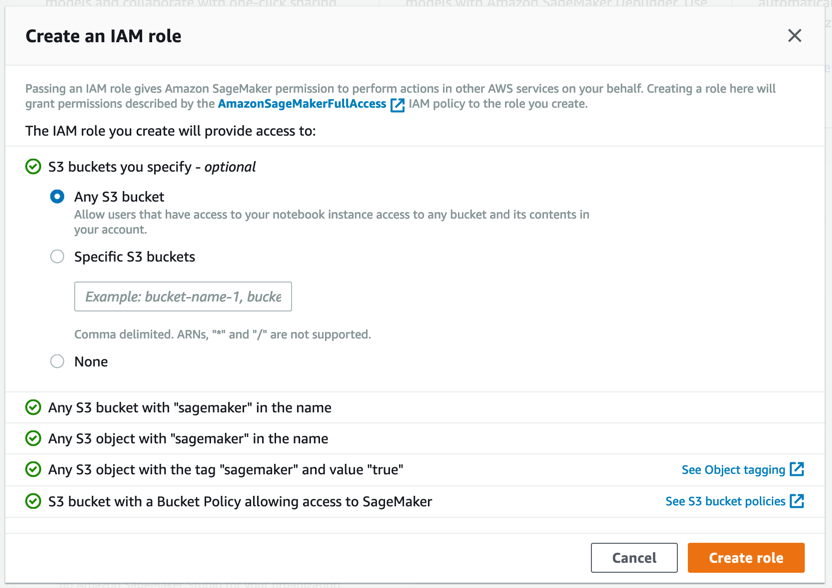
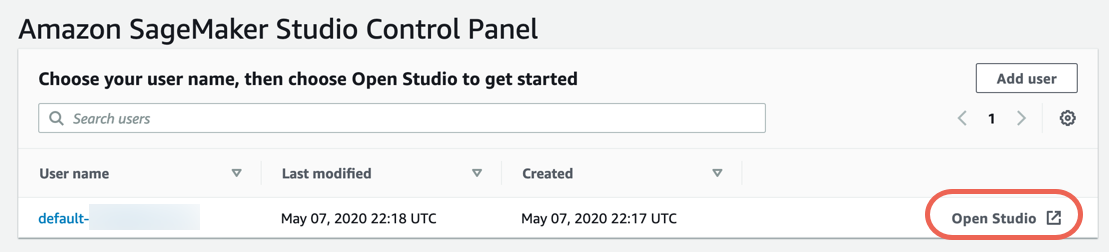
3단계. 데이터 세트 다운로드
다음 단계에 따라 데이터 세트를 다운로드한 다음 살펴봅니다.
참고: 자세한 내용은 Amazon SageMaker 설명서에서 Amazon SageMaker Studio 둘러보기를 참조하세요.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. 다음 코드를 복사하여 새 코드 셀에 붙여넣고 실행을 선택합니다.
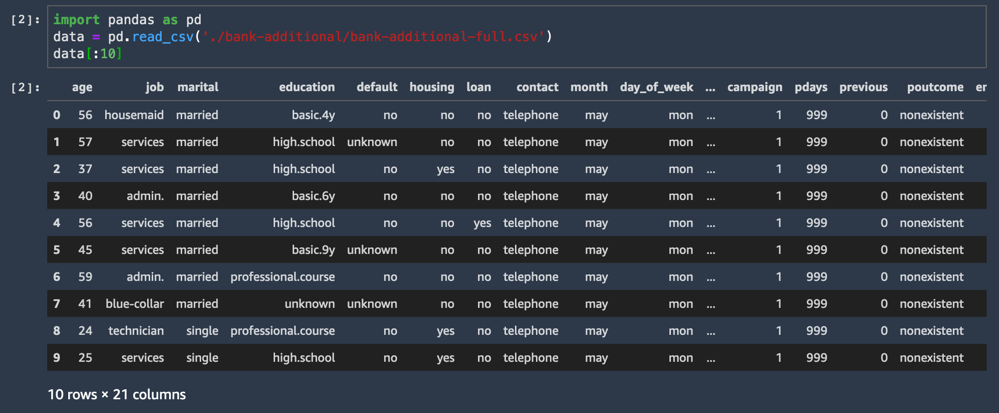
CSV 데이터 세트가 로드되고 첫 10줄이 표시됩니다.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]데이터 세트 열 중 하나(이름: y)는 각 샘플의 레이블(고객의 제안 수락 여부)을 나타냅니다.
데이터 과학자는 이 단계에서 데이터 탐색을 시작하여 새 기능 생성 등의 작업을 수행합니다. Amazon SageMaker Autopilot을 사용하는 경우에는 이러한 추가 단계를 수행할 필요가 없습니다. 스프레드시트나 데이터베이스 등에서 가져온 쉼표로 구분된 값이 포함되어 있는 파일을 사용하여 테이블 형식 데이터를 업로드하고 예측할 대상 열만 선택하면 Autopilot에서 예측 모델이 자동으로 구축됩니다.
d. 다음 코드를 복사하여 새 코드 셀에 붙여넣고 실행을 선택합니다.
이 단계를 수행하면 CSV 데이터 세트가 Amazon S3 버킷에 업로드됩니다. 데이터를 업로드하면 Amazon SageMaker에서 계정에 기본 버킷을 자동으로 생성하므로 Amazon S3 버킷을 직접 생성할 필요가 없습니다.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
이제 작업이 완료되었습니다. 코드 출력에 다음 예시와 같은 S3 버킷 URI가 표시됩니다.
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csv생성된 노트북에 인쇄되어 있는 S3 URI를 잘 보관해 두세요. 다음 단계에서 이 URI가 필요합니다.

4단계. SageMaker Autopilot 실험 생성
이제 Amazon S3에서 데이터 세트를 다운로드하고 스테이징했으므로 Amazon SageMaker Autopilot 실험을 생성할 수 있습니다. 실험은 같은 기계 학습 프로젝트와 관련된 처리 및 훈련 작업의 모음입니다.
다음 단계에 따라 새 실험을 생성합니다.
참고: 자세한 내용은 Amazon SageMaker 설명서에서 SageMaker Studio에서 Amazon SageMaker Autopilot 실험 생성을 참조하세요.
a. Amazon SageMaker Studio의 왼쪽 창에서 실험(플라스크 모양 아이콘)을 선택한 다음 실험 생성을 선택합니다.
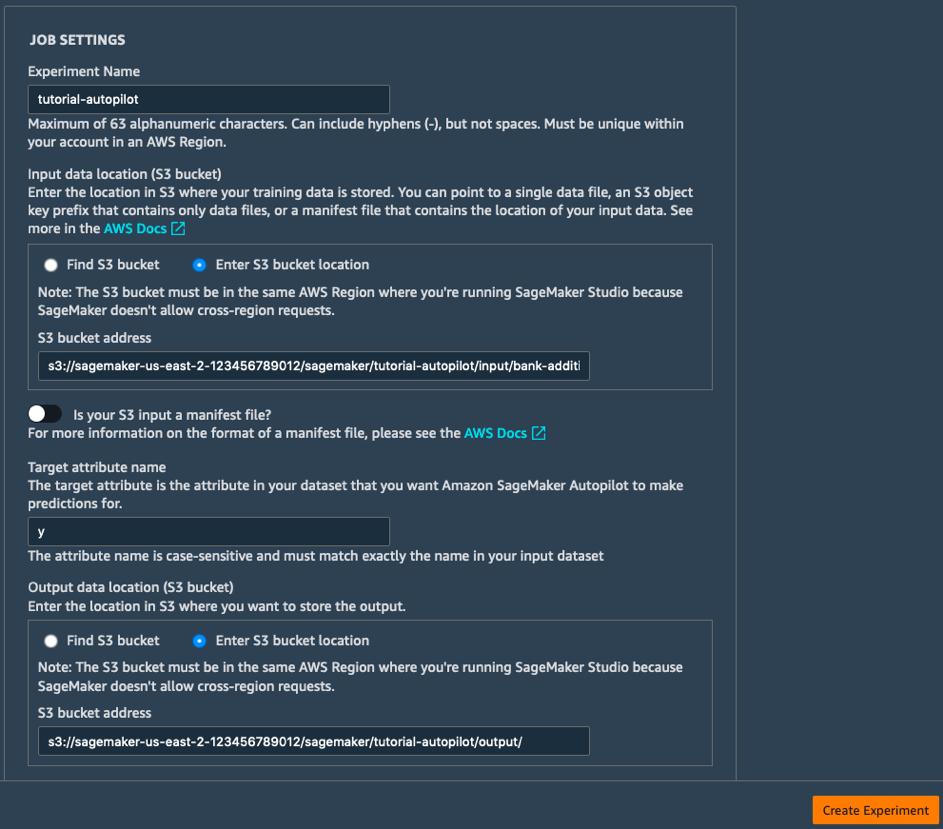
b. 작업 설정 필드에 다음과 같은 정보를 입력합니다.
- 실험 이름: tutorial-autopilot
- 입력 데이터의 S3 위치: 이전 단계에서 인쇄되었던 S3 URI
(예: s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - 대상 속성 이름: y
- 출력 데이터의 S3 위치: s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
([ACCOUNT-NUMBER]는 실제 계정 번호로 바꿔야 함)
c. 나머지 설정은 모두 기본값으로 두고 실험 생성을 선택합니다.
성공입니다! 위의 단계를 완료하면 Amazon SageMaker Autopilot 실험이 시작됩니다. 실험 프로세스에서는 모델이 생성되며, 실험이 실행되는 동안 실시간으로 확인할 수 있는 통계도 생성됩니다. 실험이 완료되면 실험 내용을 확인하고, 목표 지표를 기준으로 실험을 정렬하고, 다른 실험에서 사용할 수 있도록 마우스 오른쪽 버튼을 클릭하여 모델을 배포할 수 있습니다.
5단계. SageMaker Autopilot 실험 단계 살펴보기
실험이 실행되는 동안 SageMaker Autopilot 실험의 각 단계에 대해 알아보고 해당 단계를 살펴볼 수 있습니다.
이 섹션에서는 SageMaker Autopilot 실험 단계에 대해 자세히 설명합니다.
- 데이터 분석
- 기능 엔지니어링
- 모델 튜닝
참고: 자세한 내용은 SageMaker Autopilot 노트북 출력을 참조하세요.
데이터 분석
데이터 분석 단계에서는 해결할 문제 유형(선형 회귀, 이진 분류, 멀티클래스 분류)을 식별합니다. 그런 다음 후보 파이프라인 10개가 제시됩니다. 파이프라인에는 누락된 값 처리/새 기능 엔지니어링 등의 데이터 사전 처리 단계, 그리고 문제 유형과 일치하는 ML 알고리즘을 사용하는 모델 훈련 단계가 모두 포함됩니다. 이 단계가 완료되면 기능 엔지니어링 단계가 진행됩니다.
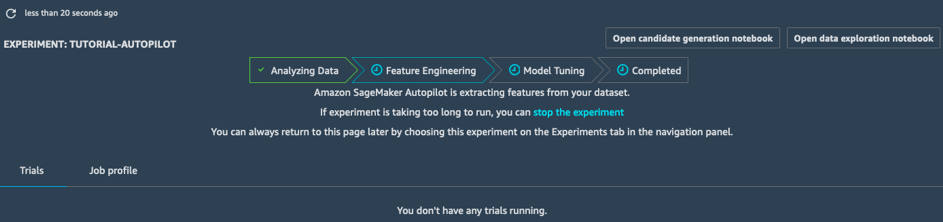
기능 엔지니어링
실험의 기능 엔지니어링 단계에서는 각 후보 파이프라인용으로 훈련 및 검증 데이터 세트가 생성되며 S3 버킷에 모든 아티팩트가 저장됩니다. 기능 엔지니어링 단계에서는 자동 생성 노트북 두 개를 열어서 확인할 수 있습니다.
- 데이터 탐색 노트북에는 데이터 세트 관련 정보와 통계가 포함되어 있습니다.
- 후보 생성 노트북에는 파이프라인 10개의 정의가 포함되어 있습니다. 이 노트북은 실제로 실행할 수 있으므로 Autopilot 작업의 내용을 정확하게 재현하고 각 모델이 구축되는 방식을 파악할 수 있으며, 원하는 경우 모델을 계속 조정할 수도 있습니다.
이 두 노트북을 활용하면 데이터가 사전 처리되는 방식 및 모델 구축/최적화 방식을 자세히 파악할 수 있습니다. 이처럼 데이터를 명확하게 파악할 수 있는 기능은 Amazon SageMaker Autopilot의 중요한 기능입니다.
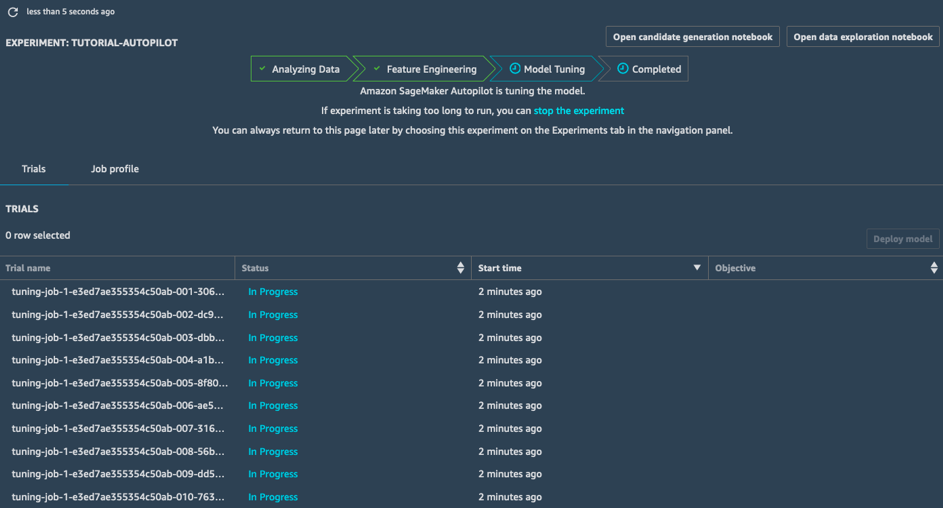
모델 튜닝
모델 튜닝 단계에서 SageMaker Autopilot은 각 후보 파이프라인과 사전 처리된 데이터 세트에 대해 하이퍼파라미터 최적화 작업을 시작합니다. 이 작업과 연관된 훈련 작업에서는 광범위한 하이퍼파라미터 값을 확인한 다음 빠르게 모델의 범위를 좁혀 성능이 우수한 모델을 선택합니다.
이 단계가 완료되면 SageMaker Autopilot 작업이 완료됩니다. 그러면 SageMaker Studio에서 모든 작업을 확인하고 살펴볼 수 있습니다.
6단계. 최적 모델 배포
실험이 완료되면 최적의 튜닝 모델을 선택한 다음 Amazon SageMaker에서 관리하는 엔드포인트로 배포할 수 있습니다.
다음 단계에 따라 최적 튜닝 작업을 선택하고 모델을 배포합니다.
참고: 자세한 내용은 최적 모델 선택 및 배포를 참조하세요.
a. 실험의 실험 목록에서 목표 옆의 당근 모양 아이콘을 선택하여 튜닝 작업을 내림차순으로 정렬합니다. 최적 튜닝 작업이 별표로 강조 표시됩니다.
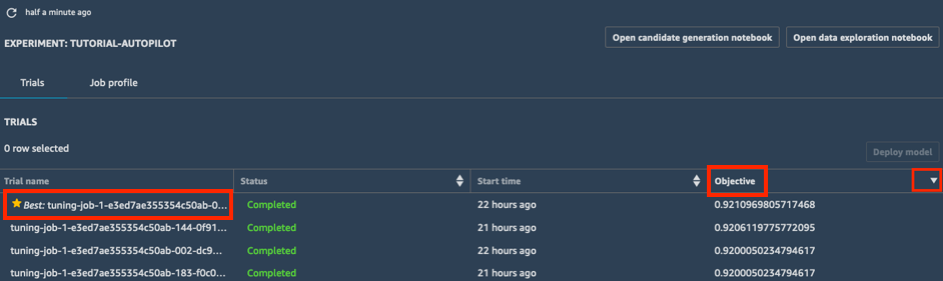
b. 별표가 표시된 최적 튜닝 작업을 선택하고 모델 배포를 선택합니다.
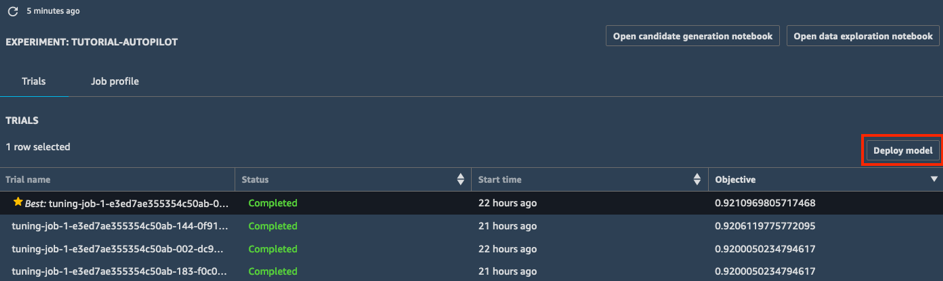
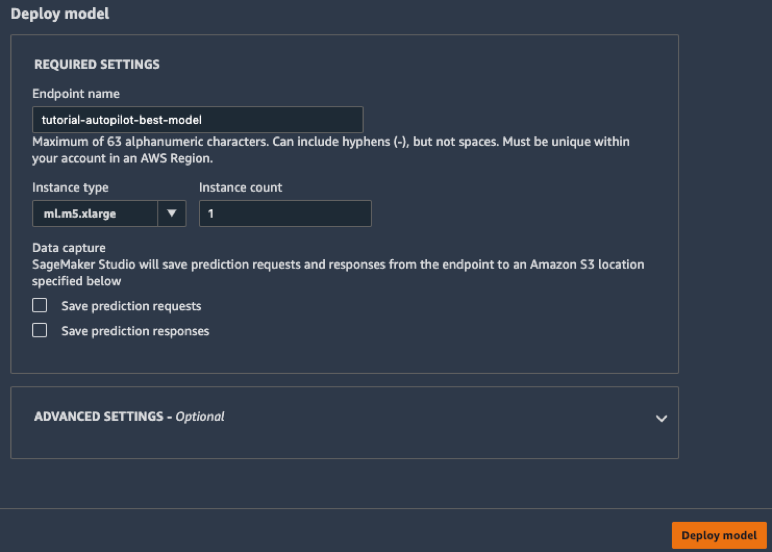
c. 모델 배포 상자에 엔드포인트의 이름을 tutorial-autopilot-best-model과 같이 입력하고 모든 설정은 기본값으로 유지합니다. 모델 배포를 선택합니다.
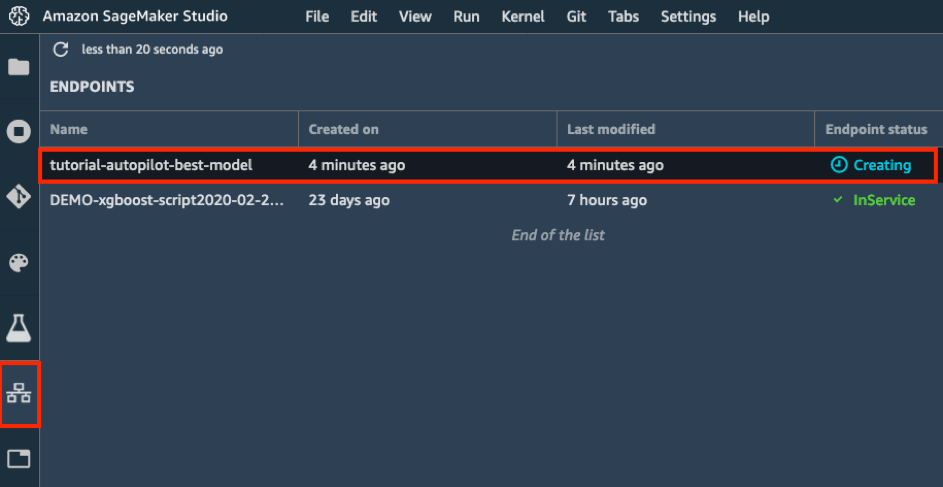
Amazon SageMaker를 통해 관리되는 HTTPS 엔드포인트에 모델이 배포됩니다.
d. 왼쪽 도구 모음에서 엔드포인트 아이콘을 선택합니다. 모델이 생성되는 중임을 확인할 수 있습니다. 모델 생성은 몇 분 정도 걸립니다. 엔드포인트 상태가 InService로 바뀌면 데이터를 전송하고 예측 정보를 수신할 수 있습니다.
7단계. 모델을 사용한 예측
이제 모델을 배포했으므로 데이터 세트의 첫 2,000개 샘플을 예측할 수 있습니다. 이 예측에는 boto3 SDK의 invoke_endpoint API를 사용합니다. 예측 프로세스에서는 주요 기계 학습 지표인 정확도, 정밀도, 회수 및 F1 점수를 계산합니다.
다음 단계에 따라 모델을 사용하여 샘플을 예측합니다.
참고: 자세한 내용은 Amazon SageMaker 실험을 사용하여 기계 학습 관리를 참조하세요.
다음 코드를 복사하여 Jupyter 노트북에 붙여넣은 다음 실행을 선택합니다.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
다음 출력이 표시됩니다.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
이 출력은 예측한 샘플 수를 보여 주는 진행률 표시기입니다.
8단계. 정리
이 단계에서는 이번 실습에서 사용한 리소스를 종료합니다.
중요: 비용 절감을 위해 현재 사용 중이지 않은 리소스는 종료하는 것이 좋습니다. 리소스를 종료하지 않으면 계정에 요금이 청구됩니다.
엔드포인트 삭제: 다음 코드를 복사하여 Jupyter 노트북에 붙여넣은 다음 실행을 선택합니다.
sess.delete_endpoint(endpoint_name=ep_name)모델, 사전 처리한 데이터 세트 등의 모든 훈련 아티팩트를 정리하려면 다음 코드를 복사하여 코드 셀에 붙여넣은 다음 실행을 선택합니다.
참고: ACCOUNT_NUMBER는 실제 계정 번호로 바꿔야 합니다.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/권장되는 다음 단계
Amazon SageMaker Studio 둘러보기
Amazon SageMaker Autopilot에 대해 자세히 알아보기
자세한 내용은 블로그 게시물 또는 Autopilot 동영상 시리즈를 참조하세요.