O que é um pipeline de dados?
O que é um pipeline de dados?
Um pipeline de dados é uma série de etapas de processamento para preparar dados corporativos para análise. As organizações têm um grande volume de dados de várias fontes, como aplicativos, dispositivos da Internet das Coisas (IoT) e outros canais digitais. No entanto, os dados brutos são inúteis; eles devem ser movidos, classificados, filtrados, reformatados e analisados para business intelligence. Um pipeline de dados inclui várias tecnologias para verificar, resumir e encontrar padrões nos dados para informar as decisões de negócios. Pipelines de dados bem organizados oferecem suporte a vários projetos de big data, como visualizações de dados, análises exploratórias de dados e tarefas de machine learning.
Quais são os benefícios de um pipeline de dados?
Os pipelines de dados permitem integrar dados de diferentes fontes e transformá-los para análise. Eles removem silos de dados e tornam sua análise de dados mais confiável e precisa. Aqui estão alguns dos principais benefícios de um pipeline de dados.
Melhor qualidade dos dados
Os pipelines de dados limpam e refinam os dados brutos, melhorando sua utilidade para os usuários finais. Eles padronizam formatos para campos como datas e números de telefone enquanto verificam erros de entrada. Eles também removem a redundância e garantem a qualidade consistente dos dados em toda a organização.
Processamento eficiente de dados
Os engenheiros de dados precisam realizar muitas tarefas repetitivas enquanto transformam e carregam dados. Os pipelines de dados permitem que eles automatizem tarefas de transformação de dados e se concentrem em encontrar os melhores insights de negócios. Os pipelines de dados também ajudam os engenheiros de dados a processar mais rapidamente os dados brutos que perdem valor com o tempo.
Integração de dados abrangente
Um pipeline de dados abstrai funções de transformação de dados para integrar conjuntos de dados de fontes diferentes. Ele pode cruzar valores dos mesmos dados de várias fontes e corrigir inconsistências. Por exemplo, imagine que o mesmo cliente faz uma compra em sua plataforma de comércio eletrônico e em seu serviço digital. No entanto, eles escrevem seu nome incorretamente no serviço digital. O pipeline pode corrigir essa inconsistência antes de enviar os dados para análise.
Como funciona um pipeline de dados?
Assim como uma tubulação de água move a água do reservatório para suas torneiras, um pipeline de dados move os dados do ponto de coleta para o armazenamento. Um pipeline de dados extrai dados de uma fonte, faz alterações e os salva em um destino específico. Explicamos os componentes críticos da arquitetura de pipeline de dados abaixo.
Fontes de dados
Uma fonte de dados pode ser uma aplicação, um dispositivo ou outro banco de dados. Fontes diferentes podem enviar dados para o pipeline. O pipeline também pode extrair pontos de dados usando uma chamada de API, webhook ou processo de duplicação de dados. Você pode sincronizar a extração de dados para processamento em tempo real ou coletar dados em intervalos programados de suas fontes de dados.
Transformações
À medida que os dados brutos fluem pelo pipeline, eles mudam para se tornarem mais úteis para business intelligence. Transformações são operações (como classificação, reformatação, desduplicação, verificação e validação) que alteram dados. Seu pipeline pode filtrar, resumir ou processar dados para atender aos seus requisitos de análise.
Dependências
Como as mudanças acontecem sequencialmente, podem existir dependências específicas que reduzem a velocidade de movimentação de dados no pipeline. Existem dois tipos principais de dependências - técnicas e de negócios. Por exemplo, se o pipeline tiver que esperar que uma fila central seja preenchida antes de prosseguir, é uma dependência técnica. Por outro lado, se o pipeline tiver que pausar até que outra unidade de negócios verifique os dados, é uma dependência de negócios.
Destinos
O endpoint de seu pipeline de dados pode ser um data warehouse, data lake ou outra aplicação de análise de dados ou business intelligence. Às vezes, o destino também é chamado de coletor de dados.
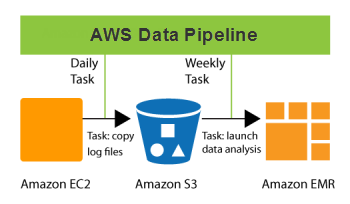
Quais são os tipos de pipeline de dados?
Existem dois tipos principais de pipelines de dados: pipelines de processamento de fluxo e pipelines de processamento em lote.
Pipelines de processamento de fluxo
Um fluxo de dados é uma sequência contínua e incremental de pacotes de dados de pequeno porte. Geralmente representa uma série de eventos que ocorrem durante um determinado período. Por exemplo, um fluxo de dados pode mostrar dados do sensor contendo medições durante a última hora. Uma única ação, como uma transação financeira, também pode ser chamada de evento. Os pipelines de streaming processam uma série de eventos para análises em tempo real.
A transmissão de dados requer baixa latência e alta tolerância a falhas. Seu pipeline de dados deve ser capaz de processar dados mesmo que alguns pacotes de dados sejam perdidos ou cheguem em uma ordem diferente da esperada.
Pipelines de processamento em lote
Os pipelines de dados de processamento em lote processam e armazenam dados em grandes volumes ou lotes. Eles são adequados para tarefas ocasionais de alto volume, como contabilidade mensal.
O pipeline de dados contém uma série de comandos sequenciados e cada comando é executado em todo o lote de dados. O pipeline de dados fornece a saída de um comando como entrada para o seguinte comando. Após a conclusão de todas as transformações de dados, o pipeline carrega todo o lote em um data warehouse na nuvem ou em outro armazenamento de dados semelhante.
Leia sobre o processamento em lote »
Diferença entre pipelines de dados em lote e de fluxo
Os pipelines de processamento em lote são executados com pouca frequência e geralmente fora dos horários de pico. Eles exigem alto poder de computação por um curto período quando são executados. Por outro lado, os pipelines de processamento de fluxo são executados continuamente, mas exigem baixo poder de computação. Em vez disso, eles precisam de conexões de rede confiáveis e de baixa latência.
Qual é a diferença entre pipelines de dados e pipelines ETL?
Um pipeline de extração, transformação e carregamento (ETL) é um tipo especial de pipeline de dados. As ferramentas ETL extraem ou copiam dados brutos de várias fontes e os armazenam em um local temporário chamado de área de preparação. Elas transformam os dados na área de preparação e os carregam em data lakes ou armazéns.
Nem todos os pipelines de dados seguem a sequência ETL. Alguns podem extrair os dados de uma fonte e carregá-los em outro lugar sem transformações. Outros pipelines de dados seguem uma sequência de extração, carregamento e transformação (ELT), onde extraem e carregam dados não estruturados diretamente em um data lake. Eles realizam alterações depois de mover as informações para data warehouses na nuvem.
Como a AWS pode oferecer suporte aos seus requisitos de pipeline de dados?
O AWS Glue é um serviço de integração de dados sem servidor que facilita aos usuários de análise descobrir, preparar, mover e integrar dados de várias fontes para análise, aprendizado de máquina e desenvolvimento de aplicativos.
- É possível descobrir e conectar-se a mais de 80 armazenamentos de dados diversos.
- Você pode gerenciar seus dados em um catálogo de dados centralizado.
- Engenheiros de dados, desenvolvedores de ETL, analistas de dados e usuários corporativos podem usar o AWS Glue Studio para criar, executar e monitorar pipelines de ETL para carregar dados em data lakes.
- O AWS Glue Studio oferece interfaces visuais de ETL, Notebook e editor de código, para que os usuários tenham ferramentas adequadas às suas habilidades.
- Com as sessões interativas, os engenheiros de dados podem explorar dados, bem como criar e testar trabalhos usando seu IDE ou notebook preferido.
- O AWS Glue usa a tecnologia sem servidor e escala automaticamente sob demanda, para que você possa se concentrar em obter insights de dados em escala de petabytes sem gerenciar a infraestrutura.
Comece a usar o AWS Glue criando uma conta da AWS.
Próximas etapas para pipeline de dados
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages