Что такое стимулированное обучение?
Что такое стимулированное обучение?
Обучение с подкреплением (RL) — это метод машинного обучения (ML), который обучает программное обеспечение принимать решения для достижения наиболее оптимальных результатов. Такое обучение основано на имитации процесса обучения методом проб и ошибок, который люди используют для достижения своих целей. Действия программного обеспечения, направленные на достижение цели, усиливаются, а действия, отвлекающие от цели, игнорируются.
Алгоритмы RL используют парадигму вознаграждения и санкций при обработке данных. Они учатся на основе отзывов о каждом действии и самостоятельно находят наилучшие способы обработки для достижения конечных результатов. Алгоритмы также способны получать вознаграждение с задержкой. Лучшая общая стратегия может потребовать краткосрочных жертв, поэтому лучший найденный ими подход может включать некие наказания или регресс. RL — это мощный метод, помогающий системам искусственного интеллекта (ИИ) достичь оптимальных результатов в невидимых средах.
Каковы преимущества обучения с подкреплением?
Обучение с подкреплением (RL) имеет много преимуществ. Ниже описаны три наиболее распространенные из них.
Высокая эффективность в сложной среде
Алгоритмы RL можно использовать в сложных средах со множеством правил и зависимостей. В той же среде человек может быть не в состоянии определить наилучший путь, даже обладая превосходными знаниями о среде. Вместо этого алгоритмы RL без моделей быстро адаптируются к постоянно меняющимся средам и находят новые стратегии для оптимизации результатов.
Минимизация человеческого вмешательства
В стандартных алгоритмах машинного обучения люди должны маркировать пары данных, чтобы управлять алгоритмом. При использовании алгоритма RL в этом нет необходимости, поскольку он учится самостоятельно. В то же время алгоритм предлагает механизмы интеграции обратной связи с людьми, позволяющие создавать системы, адаптированные к предпочтениям, опыту и корректировкам человека.
Оптимизация для достижения долгосрочных целей
Поскольку обучение RL ориентировано на максимальное увеличение вознаграждения в долгосрочной перспективе, оно эффективно для сценариев, в которых действия влекут за собой длительные последствия. Такой тип особенно хорошо подходит для реальных ситуаций, когда обратная связь по каждому шагу не всегда доступна, поскольку позволяет извлечь уроки из отсроченных вознаграждений.
Например, решения о потреблении или хранении энергии могут иметь долгосрочные последствия. Обучение RL можно использовать для оптимизации энергоэффективности и затрат в долгосрочной перспективе. При наличии соответствующей архитектуры агенты RL также могут обобщать выученные стратегии для выполнения похожих, но не идентичных задач.
Каковы примеры использования обучения с подкреплением?
Обучение с подкреплением (RL) можно применять к широкому спектру реальных случаев использования. Далее представлены несколько примеров.
Персонализация маркетинга
В таких приложениях, как системы рекомендаций, RL может настраивать предложения для отдельных пользователей в зависимости от их взаимодействия. Таким образом, степень персонализации опыта повышается. Например, приложение может показывать пользователю рекламу на основе демографической информации. При каждом рекламном взаимодействии приложение узнает, какую рекламу следует показывать пользователю для оптимизации сбыта товаров.
Трудности оптимизации
Стандартные методы оптимизации урегулируют проблемы путем оценки и сравнения возможных решений на основе определенных критериев. RL, напротив, позволяет учиться на основе взаимодействия, чтобы со временем находить лучшие или наиболее подходящие решения.
Например, система оптимизации расходов на облако использует RL для адаптации к меняющимся потребностям в ресурсах и выбора оптимальных типов, количества и конфигураций инстансов. Система принимает решения на основе таких факторов, как текущая и доступная облачная инфраструктура, расходы и использование.
Финансовые прогнозы
Динамика финансовых рынков сложна, статистические свойства со временем меняются. Алгоритмы RL могут оптимизировать долгосрочную прибыль, учитывая транзакционные издержки и адаптируясь к рыночным изменениям.
Например, алгоритм наблюдает за правилами и закономерностями фондового рынка, прежде чем тестировать действия и регистрировать соответствующие вознаграждения. Алгоритм динамически создает значение функции и разрабатывает стратегию максимального увеличения прибыли.
Как работает обучение с подкреплением?
Процесс изучения алгоритмов обучения с подкреплением (RL) аналогичен обучению с подкреплением животных и людей в области поведенческой психологии. Например, ребенок может обнаружить, что он получает похвалу родителей, когда помогает брату или сестре либо убирается, но получает негативную реакцию, когда бросает игрушки или кричит. Вскоре ребенок узнает, какое сочетание действий приносит конечную награду.
Алгоритм RL имитирует аналогичный процесс обучения. Оно пробует различные виды деятельности, чтобы изучить соответствующие отрицательные и положительные ценности для достижения конечного результата вознаграждения.
Основные понятия
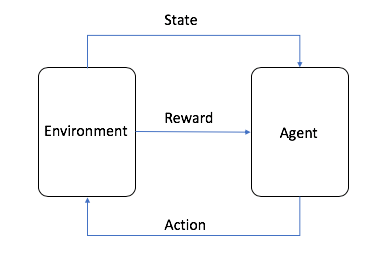
При обучении с подкреплением необходимо ознакомиться с несколькими ключевыми понятиями:
- Агент – это алгоритм МО (или автономная система).
- Среда – это адаптивное проблемное пространство с такими атрибутами, как переменные, граничные значения, правила и допустимые действия.
- Действие – это шаг, который агент RL предпринимает для навигации по среде.
- Состояние – это среда в данный момент времени.
- Вознаграждение – это положительное, отрицательное или нулевое значение (другими словами, награда либо наказание) за выполнение действия.
- Совокупное вознаграждение – это сумма всех вознаграждений или конечное значение.
Основы алгоритма
Обучение с подкреплением основано на процессе принятия решений по Маркову – математическом моделировании принятия решений с использованием дискретных временных шагов. На каждом этапе агент выполняет новое действие, которое приводит к изменению состояния окружающей среды. Точно так же текущее состояние приписывается последовательности предыдущих действий.
Путем проб и ошибок при перемещении по среде агент создает набор правил или политик типа «если-то». Эти правила помогают компании решить, какие действия предпринять дальше для получения оптимального совокупного вознаграждения. Агент также должен выбрать между дальнейшим исследованием среды для получения новых вознаграждений за действия в состоянии и выбором известных действий в данном состоянии с высоким вознаграждением. Это называется компромиссом между разведкой и эксплуатацией.
Какие типы алгоритмов обучения с подкреплением существуют?
В случае с обучением с подкреплением (RL) используются различные алгоритмы, такие как Q-обучение, методы градиента политики, методы Монте-Карло и обучение временным различиям. Глубокое обучение с подкреплением основано на применении глубоких нейронных сетей для обучения с подкреплением. Одним из примеров алгоритма глубокого обучения RL является оптимизация политики региона доверия (TRPO).
Все эти алгоритмы можно разделить на две большие категории.
RL на основе моделей
RL на основе моделей обычно используется в тех случаях, когда среда четко определена и неизменна, а тестирование реальных сред затруднено.
Сначала агент разрабатывает внутреннее представление (модель) среды. Для разработки этой модели используется описанный ниже процесс.
- Решение выполняет действия в окружающей среде и отмечает новое состояние и ценность вознаграждения.
- Оно связывает переход от действия к состоянию со значением вознаграждения.
По завершении модели агент моделирует последовательности действий на основе вероятности оптимального совокупного вознаграждения. Затем решение дополнительно присваивает значения самим последовательностям действий. Таким образом, агент разрабатывает различные стратегии в среде для достижения желаемой конечной цели.
Пример
Представьте себе робота, который учится перемещаться по новому зданию, чтобы добраться до определенной комнаты. Первоначально робот свободно исследует и строит внутреннюю модель (или карту) здания. Например, он может выучить, что лифт находится в 10 метрах от главного входа. Составив карту, робот может построить серию кратчайших маршрутов между различными местами здания, которые часто посещает.
RL без моделей
RL без моделей наиболее эффективна в больших, сложных, трудно поддающихся описанию средах, а также в неизвестных и изменчивых средах, где тестирование на основе среды не имеет существенных недостатков.
Агент не разрабатывает внутреннюю модель среды и ее динамики. Вместо этого в среде используется метод проб и ошибок, чтобы оценить и отметить пары действие – состояние, а также последовательности пар действие – состояние для разработки политики.
Пример
Представьте себе беспилотный автомобиль, который должен ориентироваться в городском потоке машин. Дороги, дорожное движение, поведение пешеходов и множество других факторов могут сделать среду очень динамичной и сложной. ИИ-команды на начальных этапах обучают транспортное средство в смоделированной среде. Транспортное средство выполняет действия в зависимости от текущего состояния, получая вознаграждения или наказания.
Со временем, преодолев миллионы миль по различным виртуальным сценариям, транспортное средство обучается действиям, наиболее соответствующим каждому состоянию, не моделируя всю динамику движения. При внедрении в реальный мир транспортное средство использует изученную политику, но продолжает совершенствовать ее, добавляя новые данные.
В чем разница между машинным обучением с подкреплением, машинным обучением под наблюдением и машинным обучением без наблюдения?
Обучение под наблюдением, обучение без наблюдения и обучение с подкреплением (RL) являются алгоритмами машинного обучения в области искусственного интеллекта, однако между ними есть различия.
Подробнее об обучении под наблюдением и без наблюдения »
Обучение с подкреплением и обучение под наблюдением
Обучение под наблюдением позволяет определить как входные данные, так и ожидаемые связанные выходные данные. Представим набор изображений, на которых стоит пометка, что это собаки или кошки. Ожидается, что алгоритм идентифицирует новое изображение животного как собаку или кошку.
Алгоритмы обучения под наблюдением изучают закономерности и отношения между парами ввода и вывода. Затем они прогнозируют результаты на основе новых входных данных. Наблюдатель, как правило, человек, должен маркировать каждую запись данных в наборе обучающих данных выходными данными.
RL, напротив, имеет четко определенную конечную цель в виде желаемого результата, при этом наблюдатель, который мог бы заранее маркировать соответствующие данные, отсутствует. Во время обучения вместо того, чтобы пытаться сопоставить входные данные с известными выходными данными, решение сопоставляет входные данные с возможными результатами. Поощряя желаемое поведение, пользователь отдает предпочтение наилучшим результатам.
Обучение с подкреплением и обучение без наблюдения
В процессе обучения алгоритмы обучения без наблюдения получают входные данные без определенных выходных данных. Они выявляют скрытые закономерности и связи в данных статистически. Представим набор документов: алгоритм может сгруппировать их по категориям, которые он идентифицирует на основе слов в тексте. Конкретные результаты при этом отсутствуют; они находятся в пределах диапазона.
У RL, напротив, есть заранее определенная конечная цель. Несмотря на исследовательский подход, результаты исследований непрерывно проверяются и совершенствуются, чтобы повысить вероятность достижения конечной цели. RL может научиться достигать весьма конкретных результатов.
С какими трудностями связано обучение с подкреплением?
Приложения на базе обучения с подкреплением (RL), безусловно, могут изменить мир, однако развертывание этих алгоритмов может оказаться непростой задачей.
Практичность
Экспериментировать с реальными системами поощрения и санкций может оказаться непрактичным. Например, тестирование дрона в реальном мире без предварительного тестирования в симуляторе может привести к поломке значительного количества летательных аппаратов. В реальности среды меняются часто и существенно практически внезапно. Таким образом, практическая эффективность алгоритма может оказаться под угрозой.
Интерпретируемость
Как и в любой другой научной области, для разработки стандартов и процедур анализ данных также основывается на убедительных исследованиях и результатах. Специалисты по обработке данных предпочитают знать, как было сделано конкретное заключение, чтобы его можно было доказать и повторить.
При использовании сложных алгоритмов RL бывает трудно определить причины, по которым была предпринята определенная последовательность шагов. Какие последовательные действия привели к оптимальному конечному результату? Трудности, связанные с определением таких действий, обуславливают проблемы с внедрением.
Как AWS способствует обучению с подкреплением?
В ассортименте Amazon Web Services (AWS) есть множество предложений для разработки, обучения и развертывания алгоритмов обучения с подкреплением (RL) для реальных приложений.
С помощью Amazon SageMaker разработчики и специалисты по обработке данных могут быстро и легко разрабатывать масштабируемые модели RL. Объедините платформу для глубокого обучения (например, TensorFlow или Apache MXNet), набор инструментов RL (например, RL Coach или RLlib) и среду для имитации реального сценария. Его можно использовать для создания и тестирования модели.
С помощью AWS RoboMaker разработчики могут запускать, масштабировать и автоматизировать моделирование с помощью алгоритмов RL для робототехники без каких-либо требований к инфраструктуре.
Получите практический опыт работы с AWS DeepRacer, полностью автономным гоночным автомобилем масштаба 1/18. Полностью настроенную облачную среду решения можно использовать для обучения моделей RL и конфигураций нейронных сетей.
Начните обучение с подкреплением на AWS, создав аккаунт уже сегодня.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages