AWS Big Data Blog
Amazon EMR 2020 year in review
Tens of thousands of customers use Amazon EMR to run big data analytics applications on Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto at scale. Amazon EMR automates the provisioning and scaling of these frameworks, and delivers high performance at low cost with optimized runtimes and support for a wide range of Amazon Elastic Compute Cloud (Amazon EC2) instance types and Amazon Elastic Kubernetes Service (Amazon EKS) clusters. Amazon EMR makes it easy for data engineers and data scientists to develop, visualize, and debug data science applications with Amazon EMR Studio (preview) and Amazon EMR Notebooks.
You can hear customers describe how they use Amazon EMR in the following 2020 AWS re:Invent sessions:
- How Nielsen built a multi-petabyte data platform using Amazon EMR
- Contextual targeting and ad tech migration best practices
- The right tool for the job: Enabling analytics at scale at Intuit
You can also find more information in the following posts:
- How the Allen Institute uses Amazon EMR and AWS Step Functions to process extremely wide transcriptomic datasets
- How the ZS COVID-19 Intelligence Engine helps Pharma & Med device manufacturers understand local healthcare needs & gaps at scale
- Dream11’s journey to building their Data Highway on AWS
- Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
Throughout 2020, we worked to deliver better Amazon EMR performance at a lower price, and to make Amazon EMR easier to manage and use for big data analytics within your Lake House Architecture. This post summarizes the key improvements during the year and provides links to additional information.
Differentiated engine performance
Amazon EMR simplifies building and operating big data environments and applications. You can launch an EMR cluster in minutes. You don’t need to worry about infrastructure provisioning, cluster setup, configuration, or tuning. Amazon EMR takes care of these tasks, allowing you to focus your teams on developing differentiated big data applications. In addition to eliminating the need for you to build and manage your own infrastructure to run big data applications, Amazon EMR gives you better performance than simply using open-source distributions, and provides 100% API compatibility. This means you can run your workloads faster without changing any code.
Amazon EMR runtime for Apache Spark is a performance-optimized runtime environment for Spark that is active by default. We first introduced the EMR runtime for Apache Spark in Amazon EMR release 5.28.0 in November 2019, and used queries based on the TPC-DS benchmark to measure the performance improvement over open-source Spark 2.4. Those results showed considerable improvement: the geometric mean in query execution time was 2.4 times faster and the total query runtime was 3.2 times faster. As discussed in Turbocharging Query Execution on Amazon EMR at AWS re:Invent 2020, we’ve continued to improve the runtime, and our latest results show that Amazon EMR 5.30 is three times faster than without the runtime, which means you can run petabyte-scale analysis at less than half the cost of traditional on-premises solutions. For more information, see How Drop used the EMR runtime for Apache Spark to halve costs and get results 5.4 times faster.
We’ve also improved Hive and PrestoDB performance. In April 2020, we announced support for Hive Low Latency Analytical Processing (LLAP) as a YARN service starting with Amazon EMR 6.0. Our tests show that Apache Hive is two times faster with Hive LLAP on Amazon EMR 6.0. You can choose to use Hive LLAP or dynamically allocated containers. In May 2020, we introduced the Amazon EMR runtime for PrestoDB in Amazon EMR 5.30. Our most recent tests based on TPC-DS benchmark queries compare Amazon EMR 5.31, which uses the runtime, to Amazon EMR 5.29, which does not. The geometric mean in query execution time is 2.6 times faster with Amazon EMR 5.31 and the runtime for PrestoDB.
Simpler incremental data processing
Apache Hudi (Hadoop Upserts, Deletes, and Incrementals) is an open-source data management framework used for simplifying incremental data processing and data pipeline development. You can use it to perform record-level inserts, updates, and deletes in Amazon Simple Storage Service (Amazon S3) data lakes, thereby simplifying building change data capture (CDC) pipelines. With this capability, you can comply with data privacy regulations and simplify data ingestion pipelines that deal with late-arriving or updated records from sources like streaming inputs and CDC from transactional systems. Apache Hudi integrates with open-source big data analytics frameworks like Apache Spark, Apache Hive, and Presto, and allows you to maintain data in Amazon S3 or HDFS in open formats like Apache Parquet and Apache Avro.
We first supported Apache Hudi starting with Amazon EMR release 5.28 in November 2019. In June 2020, Apache Hudi graduated from incubator with release 0.6.0, which we support with Amazon EMR releases 5.31.0, 6.2.0, and higher. The Amazon EMR team collaborated with the Apache Hudi community to create a new bootstrap operation, which allows you to use Hudi with your existing Parquet datasets without needing to rewrite the dataset. This bootstrap operation accelerates the process of creating a new Apache Hudi dataset from existing datasets—in our tests using a 1 TB Parquet dataset on Amazon S3, the bootstrap performed five times faster than bulk insert.
Also in June 2020, starting with Amazon EMR release 5.30.0, we added support for the HoodieDeltaStreamer utility, which provides an easy way to ingest data from many sources, including AWS Data Migration Services (AWS DMS). With this integration, you can now ingest data from upstream relational databases to your S3 data lakes in a seamless, efficient, and continuous manner. For more information, see Apply record level changes from relational databases to Amazon S3 data lake using Apache Hudi on Amazon EMR and AWS Database Migration Service.
Amazon Athena and Amazon Redshift Spectrum added support for querying Apache Hudi datasets in S3-based data lakes—Athena announcing in July 2020 and Redshift Spectrum announcing in September. Now, you can query the latest snapshot of Apache Hudi Copy-on-Write (CoW) datasets from both Athena and Redshift Spectrum, even while you continue to use Apache Hudi support in Amazon EMR to make changes to the dataset.
Differentiated instance performance
In addition to providing better software performance with Amazon EMR runtimes, we offer more instance options than any other cloud provider, allowing you to choose the instance that gives you the best performance and cost for your workload. You choose what types of EC2 instances to provision in your cluster (standard, high memory, high CPU, high I/O) based on your application’s requirements, and fully customize your cluster to suit your requirements.
In December 2020, we announced that Amazon EMR now supports M6g, C6g, and R6g instances with versions 6.1.0, 5.31.0 and later, which enables you to use instances powered by AWS Graviton2 processors. Graviton2 processors are custom designed by AWS using 64-bit Arm Neoverse cores to deliver the best price performance for cloud workloads running in Amazon EC2. Although your performance benefit will vary based on the unique characteristics of your workloads, our tests based on the TPC-DS 3 TB benchmark showed that the EMR runtime for Apache Spark provides up to 15% improved performance and up to 30% lower costs on Graviton2 instances relative to equivalent previous generation instances.
Easier cluster optimization
We’ve also made it easier to optimize your EMR clusters. In July 2020, we introduced Amazon EMR Managed Scaling, a new feature that automatically resizes your EMR clusters for best performance at the lowest possible cost. EMR Managed Scaling eliminates the need to predict workload patterns in advance or write custom automatic scaling rules that depend on an in-depth understanding of the application framework (for example, Apache Spark or Apache Hive). Instead, you specify the minimum and maximum compute resource limits for your clusters, and Amazon EMR constantly monitors key metrics based on the workload and optimizes the cluster size for best resource utilization. Amazon EMR can scale the cluster up during peaks and scale it down gracefully during idle periods, reducing your costs by 20–60% and optimizing cluster capacity for best performance.
EMR Managed Scaling is supported for Apache Spark, Apache Hive, and YARN-based workloads on Amazon EMR versions 5.30.1 and above. EMR Managed Scaling supports EMR instance fleets, enabling you to seamlessly scale Spot Instances, On-Demand Instances, and instances that are part of a Savings Plan, all within the same cluster. You can take advantage of Managed Scaling and instance fleets to provision the cluster capacity that has the lowest chance of getting interrupted, for the lowest cost.
In October 2020, we announced Amazon EMR support for the capacity-optimized allocation strategy for provisioning EC2 Spot Instances. The capacity-optimized allocation strategy automatically makes the most efficient use of available spare capacity while still taking advantage of the steep discounts offered by Spot Instances. You can now specify up to 15 instance types in your EMR task instance fleet configuration. This provides Amazon EMR with more options in choosing the optimal pools to launch Spot Instances from in order to decrease chances of Spot interruptions, and increases the ability to relaunch capacity using other instance types in case Spot Instances are interrupted when Amazon EC2 needs the capacity back.
For more information, see How Nielsen built a multi-petabyte data platform using Amazon EMR and Contextual targeting and ad tech migration best practices.
Workload consolidation
Previously, you had to choose between using fully managed Amazon EMR on Amazon EC2 or self-managing Apache Spark on Amazon EKS. When you use Amazon EMR on Amazon EC2, you can choose from a wide range of EC2 instance types to meet price and performance requirements, but you can’t run multiple versions of Apache Spark or other applications on a cluster, and you can’t use unused capacity for non-Amazon EMR applications. When you self-manage Apache Spark on Amazon EKS, you have to do the heavy lifting of installing, managing, and optimizing Apache Spark to run on Kubernetes, and you don’t get the benefit of optimized runtimes in Amazon EMR.
You no longer have to choose. In December 2020, we announced the general availability of Amazon EMR on Amazon EKS, a new deployment option for Amazon EMR that allows you to run fully managed open-source big data frameworks on Amazon EKS. If you already use Amazon EMR, you can now consolidate Amazon EMR-based applications with other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management using common Amazon EKS tools. If you currently self-manage big data frameworks on Amazon EKS, you can now use Amazon EMR to automate provisioning and management, and take advantage of the optimized Amazon EMR runtimes to deliver better performance at lower cost.
Amazon EMR on EKS enables your team to collaborate more efficiently. You can run applications on a common pool of resources without having to provision infrastructure, and co-locate multiple Amazon EMR versions on a single Amazon EKS cluster to rapidly test and verify new Amazon EMR versions and the included open-source frameworks. You can improve developer productivity with faster cluster startup times because Amazon EMR application containers on existing Amazon EKS cluster instances start within 15 seconds, whereas creating new clusters of EC2 instances can take several minutes. You can use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to programmatically author, schedule, and monitor workflows, and use EMR Studio (preview) to develop, visualize, and debug applications. We discuss Amazon MWAA and EMR Studio more in the next section.
For more information, see Run Spark on Kubernetes with Amazon EMR on Amazon EKS and Amazon EMR on EKS Development Guide.
Higher developer productivity
Of course, your goal with Amazon EMR is not only to achieve the best price performance for your big data analytics workloads, but also to deliver new insights that help you run your business.
In November 2020, we announced Amazon MWAA, a fully managed service that makes it easy to run open-source versions of Apache Airflow on AWS, and to build workflows to run your extract, transform, and load (ETL) jobs and data pipelines. Airflow workflows retrieve input from sources like Amazon S3 using Athena queries, perform transformations on EMR clusters, and can use the resulting data to train machine learning (ML) models on Amazon SageMaker. Workflows in Airflow are authored as Directed Acyclic Graphs (DAGs) using the Python programming language.
At AWS re:Invent 2020, we introduced the preview of EMR Studio, a new notebook-first integrated development environment (IDE) experience with Amazon EMR. EMR Studio makes it easy for data scientists to develop, visualize, and debug applications written in R, Python, Scala, and PySpark. It provides fully managed Jupyter notebooks and tools like Spark UI and YARN Timeline Service to simplify debugging. You can install custom Python libraries or Jupyter kernels required for your applications directly to your EMR clusters, and can connect to code repositories such as AWS CodeCommit, GitHub, and Bitbucket to collaborate with peers. EMR Studio uses AWS Single Sign-On (AWS SSO), enabling you to log in directly with your corporate credentials without signing in to the AWS Management Console.
EMR Studio kernels and applications run on EMR clusters, so you get the benefit of distributed data processing using the performance-optimized EMR runtime for Apache Spark. You can create cluster templates in AWS Service Catalog to simplify running jobs for your data scientists and data engineers, and can take advantage of EMR clusters running on Amazon EC2, Amazon EKS, or both. For example, you might reuse existing EC2 instances in your shared Kubernetes cluster to enable fast startup time for development work and ad hoc analysis, and use EMR clusters on Amazon EC2 to ensure the best performance for frequently run, long-running workloads.
To learn more, see Introducing a new notebook-first IDE experience with Amazon EMR and Amazon EMR Studio.
Unified governance
At AWS, we recommend you use a Lake House Architecture to modernize your data and analytics infrastructure in the cloud. A Lake House Architecture acknowledges the idea that taking a one-size-fits-all approach to analytics eventually leads to compromises. It’s not simply about integrating a data lake with a data warehouse, but rather about integrating a data lake, data warehouse, and purpose-built analytics services, and enabling unified governance and easy data movement. For more information about this approach, see Harness the power of your data with AWS Analytics by Rahul Pathak, and his AWS re:Invent 2020 analytics leadership session.
As shown in the following diagram, Amazon EMR is one element in a Lake House Architecture on AWS, along with Amazon S3, Amazon Redshift, and more.
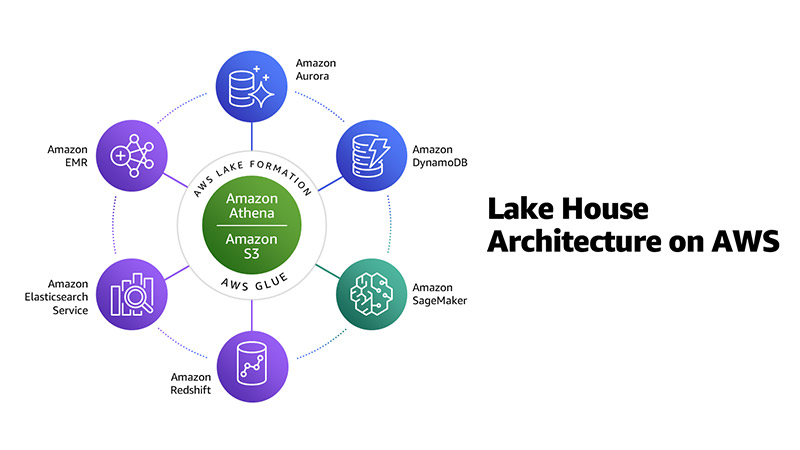
One of the most important pieces of a modern analytics architecture is the ability for you to authorize, manage, and audit access to data. AWS gives you the fine-grained access control and governance you need to manage access to data across a data lake and purpose-built data stores and analytics services from a single point of control.
In October 2020, we announced the general availability of Amazon EMR integration with AWS Lake Formation. By integrating Amazon EMR with AWS Lake Formation, you can enhance data access control on multi-tenant EMR clusters by managing Amazon S3 data access at the level of databases, tables, and columns. This feature also enables SAML-based single sign-on to EMR Notebooks and Apache Zeppelin, and simplifies the authentication for organizations using Active Directory Federation Services (ADFS). With this integration, you have a single place to manage data access for Amazon EMR, along with the other AWS analytics services shown in the preceding diagram. At AWS re:Invent 2020, we announced the preview of row-level security for Lake Formation, which makes it even easier to control access for all the people and applications that need to share data.
In January 2021, we introduced Amazon EMR integration with Apache Ranger. Apache Ranger is an open-source project that provides authorization and audit capabilities for Hadoop and related big data applications like Apache Hive, Apache HBase, and Apache Kafka. Starting with Amazon EMR 5.32, we’re including plugins to integrate with Apache Ranger 2.0 that enable authorization and audit capabilities for Apache SparkSQL, Amazon S3, and Apache Hive. You can set up a multi-tenant EMR cluster, use Kerberos for user authentication, use Apache Ranger 2.0 (managed separately outside the EMR cluster) for authorization, and configure fine-grained data access policies for databases, tables, columns, and S3 objects.
With this native integration, you use the Amazon EMR security configuration to specify Apache Ranger details, without the need for custom bootstrap scripts. You can reuse existing Apache Hive Ranger policies, including support for row-level filters and column masking.
To learn more, see Integrate Amazon EMR with AWS Lake Formation and Integrate Amazon EMR with Apache Ranger.
Jumpstart your migration to Amazon EMR
Building a modern data platform using the Lake House Architecture enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools like Amazon EMR. Migrating your big data and ML to AWS and Amazon EMR offers many advantages over on-premises deployments. These include separation of compute and storage, increased agility, resilient and persistent storage, and managed services that provide up-to-date, familiar environments to develop and operate big data applications. We can help you design, deploy, and architect your analytics application workloads in AWS and help you migrate your big data and applications.
The AWS Well-Architected Framework helps you understand the pros and cons of decisions you make while building systems on AWS. By using the framework, you learn architectural best practices for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud, and ways to consistently measure your architectures against best practices and identify areas for improvement. In May 2020, we announced the Analytics Lens for the AWS Well-Architected Framework, which offers comprehensive guidance to make sure that your analytics applications are designed in accordance with AWS best practices. We believe that having well-architected systems greatly increases the likelihood of business success.
To move to Amazon EMR, you can download the Amazon EMR migration guide to follow step-by-step instructions, get guidance on key design decisions, and learn best practices. You can also request an Amazon EMR Migration Workshop, a virtual workshop to jumpstart your Apache Hadoop/Spark migration to Amazon EMR. You can also learn how AWS partners have helped customers migrate to Amazon EMR in Mactores’s Seagate case study, Cloudwick’s on-premises to AWS Cloud migration to drive cost efficiency, and DNM’s global analytics platform for the cinema industry.
About the Authors
 Abhishek Sinha is a Principal Product Manager at Amazon Web Services.
Abhishek Sinha is a Principal Product Manager at Amazon Web Services.
 Al MS is a product manager for Amazon EMR at Amazon Web Services.
Al MS is a product manager for Amazon EMR at Amazon Web Services.
 BJ Haberkorn is principal product marketing manager for analytics at Amazon Web Services. BJ has worked previously on voice technology including Amazon Alexa, real time communications systems, and processor design. He holds BS and MS degrees in electrical engineering from the University of Virginia.
BJ Haberkorn is principal product marketing manager for analytics at Amazon Web Services. BJ has worked previously on voice technology including Amazon Alexa, real time communications systems, and processor design. He holds BS and MS degrees in electrical engineering from the University of Virginia.