AWS Big Data Blog
How the ZS COVID-19 Intelligence Engine helps Pharma & Med device manufacturers understand local healthcare needs & gaps at scale
This post is co-written by Parijat Sharma: Principal, Strategy & Transformation, Wenhao Xia: Manager, Data Science, Vineeth Sandadi: Manager, Business Consulting from ZS Associates, Inc, Arianna Tousi: Strategy, Insights and Planning Consultant from ZS, Gopi Vikranth: Associate Principal from ZS. In their own words, “We’re passionately committed to helping our clients and their customers thrive, working side by side to drive customer value and results”.
The COVID-19 trajectory across the US continues to remain unstable and heterogeneous. Although certain cities and counties were able to tame the adverse effects of the pandemic by applying stricter controls on social life, newer hotspots are emerging in different locations sporadically.
Organizations in healthcare, pharma, and biotech are looking to adapt to a rapidly evolving and diverse local market landscape, and restart parts of their operations that are significantly impacted, such as patient support functions, sales, and key account management. Real-time insights into the rapidly evolving COVID-19 situation and its impact on all key stakeholders in the healthcare supply chain, including patients, physicians, and health systems, is a key asset in helping companies adapt based on local market dynamics and remain resilient to future disruptions. However, several life-science companies don’t have these insights because they lack the infrastructure to integrate and manage the relevant datasets at scale and the analytical capabilities to mine the data for the relevant insights.
ZS came into this critical situation and built a data lake on AWS to address these challenges. The primary characteristics of this data lake is that it’s largely open source, which gives ZS a head start to meet the product launch SLA using AWS. This post describes how ZS developed the data lake and brought their proprietary machine learning (ML) models to run on AWS, providing intelligent insight on COVID-19.
What is the ZS COVID-19 Intelligence Engine?
The ZS COVID-19 Intelligence Engine was designed as a customizable capability that does the following:
- Integrates diverse public and proprietary healthcare datasets in a scalable data warehouse that stores data in a secure and compliant manner
- Provides advanced descriptive and predictive analytical modules to forecast COVID-19 evolution and its impact on key stakeholders and the treatment journey
- Packages insights into intuitive preconfigured reports and dashboards for dissemination across an organization
AWS Cloud data and analytics infrastructure
In this section, we dive into the infrastructure components of the ZS COVID-19 Intelligence Engine. The objective was to quickly set up a data lake with an accompanying ingestion mechanism to allow rapid ingestion of public datasets, third-party data, and datasets from AWS Data Exchange.
The overall data processing solution is based on ZS’s REVO™ data management product, which uses Apache Spark on Amazon EMR. The Spark engine processes and transforms raw data into structured data that is ready for interactive analysis. The raw data comes in compressed text delimited format ranging from 100 MBs to 15 GB. After the data is cleansed and rules applied, the processed data is staged in Amazon Simple Storage Service (Amazon S3) buckets in Apache Parquet format. This data is selectively loaded into an Amazon Redshift cluster for fast interactive querying and repetitive analysis on subsets of data.
The Intelligence Engine also uses a powerful Amazon Elastic Compute Cloud (Amazon EC2) instance to run ML workloads, which predicts future COVID-19 caseloads at the county level. The prediction models run daily on a compute-optimized EC2 C5.24xlarge On-Demand Instance, allowing rapid turnaround of prediction results and saving overall cost for using On-Demand Instances.
ZS uses Amazon Redshift as the data warehouse in this architecture. Amazon Redshift is easy to launch and maintain and can quickly run analytical queries on large normalized datasets using standard ANSI SQL. After the raw data gets processed using ZS’s REVO™, the curated data is loaded into Amazon Redshift to run interactive analytical queries. The queries generate insights specific to local geography, county, and healthcare systems, and run on Amazon Redshift tables consisting of anonymized patient data. The Amazon Redshift cluster uses On-Demand Instances and is sized to accommodate 25 TB of data at the time of this product launch. Typical interactive queries include joining data across large tables, up to 1.5 billion rows in the main table.
The following diagram illustrates this architecture:
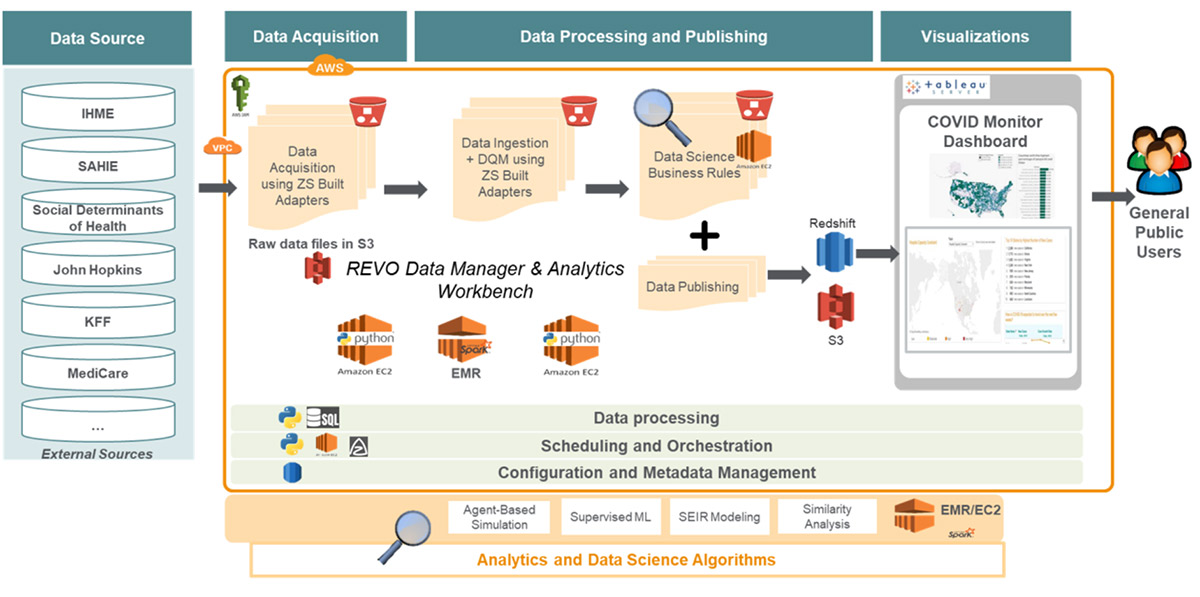
The ZS COVID-19 data lake has several benefits and applicable use cases:
- Streamlined data procurement processes – Eliminates the need for multiple ZS teams to procure, ingest, and process the same datasets separately
- Optimized common usage across clients and business questions – ZS uses this capability to publish common derivations of data that can then be utilized across different ZS teams and use cases to create a single version of truth
- Cross-functional processes and requirements – Some analytics use cases require cross-functional data and are significantly hampered by the ability of a user to access various data sources in one place—a data lake enables this by design
- Connected healthcare data – Due to developing common standards and integrating with MDM and ontologies, data from the public domain can be compliantly integrated with pharma manufacturer-specific data sources to enable seamless analytics on the data lake
Comprehensive healthcare data lake
At its core, the Intelligence Engine builds a scalable and integrated repository of diverse public and proprietary data sources. These datasets range in variety, volume, and velocity:
- COVID-19 incidence – There are several COVID-specific datasets that the public has become accustomed to viewing over the past several months, such as Johns Hopkins incidence tracking and IHME predictive data, which describes how the disease has been progressing over time and even into the future. This data tends to be at either the state or county level and is often refreshed daily. The data lake solution contains the entire history for these datasets, which, taken together, spans into the hundreds of gigabytes in size. In addition to these sources, ZS’ proprietary predictive models add an additional element of accuracy and are customized with ZS-specific insights.
- Government policies – Government policy data, which is mostly being used from AWS Data Exchange on behalf of the New York Times, explains the current state of government mandates and recommendations for varying degrees of lockdown or reopening as it pertains to the pandemic. This data is much smaller in volume, well under 1 GB total.
- Insurance claims at patient level – Thanks to the partnership with Symphony Health, ZS have had the opportunity to analyze and expose patient claims data that can be attributed to the specific hospital account or healthcare provider for which that claim took place. The insurance claims data is the largest volume of data—close to 15 TB—contributing to the ZS COVID-19 Intelligence Engine. ZS’ data engineering team has wrangled these large datasets with the help of Amazon EMR for aggregating and processing metrics, which are then stored in Amazon Redshift in a transformed version that is much smaller and can be more easily understood than the original raw datasets.
- HCP to site of care affiliations – Thanks to the partnership with Definitive Healthcare, ZS are in the process of integrating best-in-class physician-hospital and clinic affiliations from Definitive Healthcare with patient claims from Symphony to help assess available healthcare capacity and evolving approaches to care delivery and type of care being delivered by disease area.
- Other Intelligence engine data sources –
- State testing rates
- Mobility
- Demographics and social determinants of health
- Provider access and affinity for pharma commercial engagement (from ZS affinity/access monitor)
- Automated data ingestors for a variety of pharma manufacturer-specific data sources including specialty pharmacy and hub transactions, sales force activity, customer digital engagement, and more
Predictive models for COVID-19 projections and healthcare demand-supply gaps at a local level
To drive decision-making at a local level, ZS required more granular projections of COVID-19 disease spread than what’s publicly available at a state or national level. Therefore, as part of the Intelligence Engine, the ZS data science team aimed to developed an ensemble model of COVID-19 projections at the county level to identify emerging local healthcare gaps along different phases of the treatment process.
Developing a locally predictive model has many challenges, and ZS believe that no single model can capture all the virtually infinite drivers and factors contributing to disease spread within a specific geographic area. Therefore, the ZS data science team behind the COVID-19 projections has implemented multiple projection models, each with their own set of input data sources, assumptions, and parameters. This allows to increase the accuracy of the projection while retaining a level of stability and interpretability of tge model. These models include:
- Statistical curve fitting model – A disease progression curve using a Generalized Gaussian Cumulative Distribution Function, optimized to minimize prediction error of COVID-19 cases and deaths
- SEIR model – Traditional epidemiological disease progression model (pathway of Susceptible – Exposed – Infectious – Recovered) combined with traditional ML on model parameters
- Agent-based simulation – County-level simulation of individual interactions between people within the county
Obtaining a more granular view of future virus spread at a local level is critical in order to provide support for challenges in specific sites of care. Accurately projecting cases at the county level can be difficult for many reasons. Counties with low current case counts means that the model has little historical data to learn from (both in time since first infection and in magnitude of cases). Additionally, forecasts can be sensitive to many variables, and the current second wave of COVID-19 infections adds additional complications to tracking the spread of the virus.
To combat some of these difficulties, ZS implemented a two-phased approach to generate county-level projections. Counties with a long enough history of virus spread are projected independently using the three disease progression models we outlined, whereas counties with limited history are projected using a combination of state-level projections and social determinants of health factors that are predictive of disease spread (for example, age distribution in a certain county).
As the world around us continues to evolve and the COVID-19 situation with it, the ZS data science team is also working to adapt the model alongside the current situation. Currently, model adaptability and its self-learning ability are continuing to improve to better adapt to the onset of the second wave of the virus. Additional parameters and re-optimizations are happening daily as the situation develops.
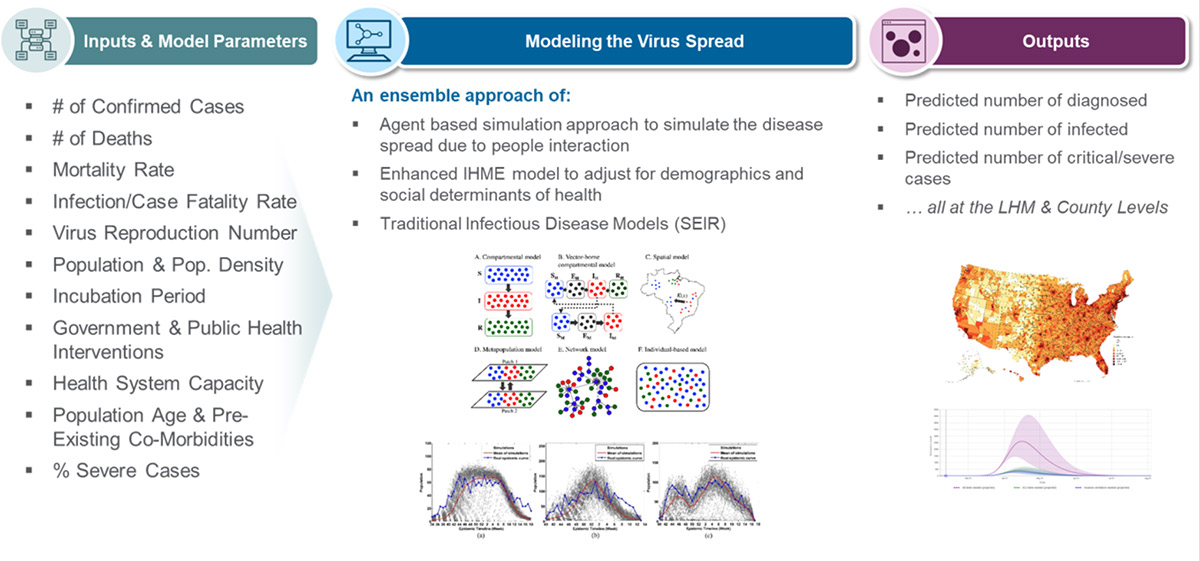
Following image shows the Input data sources, modeling techniques and outputs from ZS COVID-19 projection models:
Analyzing and predicting local non-COVID-19 treatment gaps and their drivers
Several flexible analytical tools can be used to evaluate barriers along the disease treatment journey for non-COVID-19 diseases at the local geography level, their evolution over time with COVID-19, and their underlying drivers. These tools summarize local changes in and the underlying drivers of the following:
- New patient diagnosis
- Changes in treatment approaches and drugs used
- Patient affordability and access to medications
- Persistency and compliance to treatment
- Healthcare demand, patients needing care and supply, provider capacity to offer care
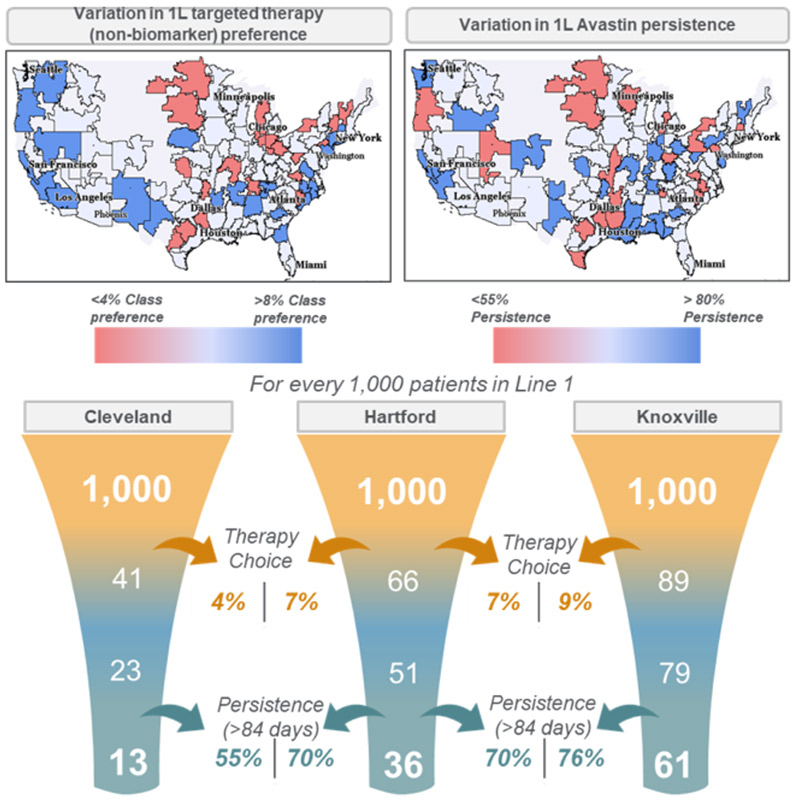
Following image represents output from the Intelligence Engine illustrating local variations in Healthcare gaps:
Intuitive visualization capabilities
The solution has two intuitive visualization capabilities:
- COVID-19 monitor – A public access dashboard with insights on historical and future predictions of trajectories of COVID-19 incidences and hospital capacity. These insights are available at the state level and further and allow you to drill into individual counties. The individual county-level view allows you to not only understand the severity of COVID-19 in that area, but also better understand how that county compares to other counties within the same state and observe what policies their local governments have set for the shutdown and reopening process.
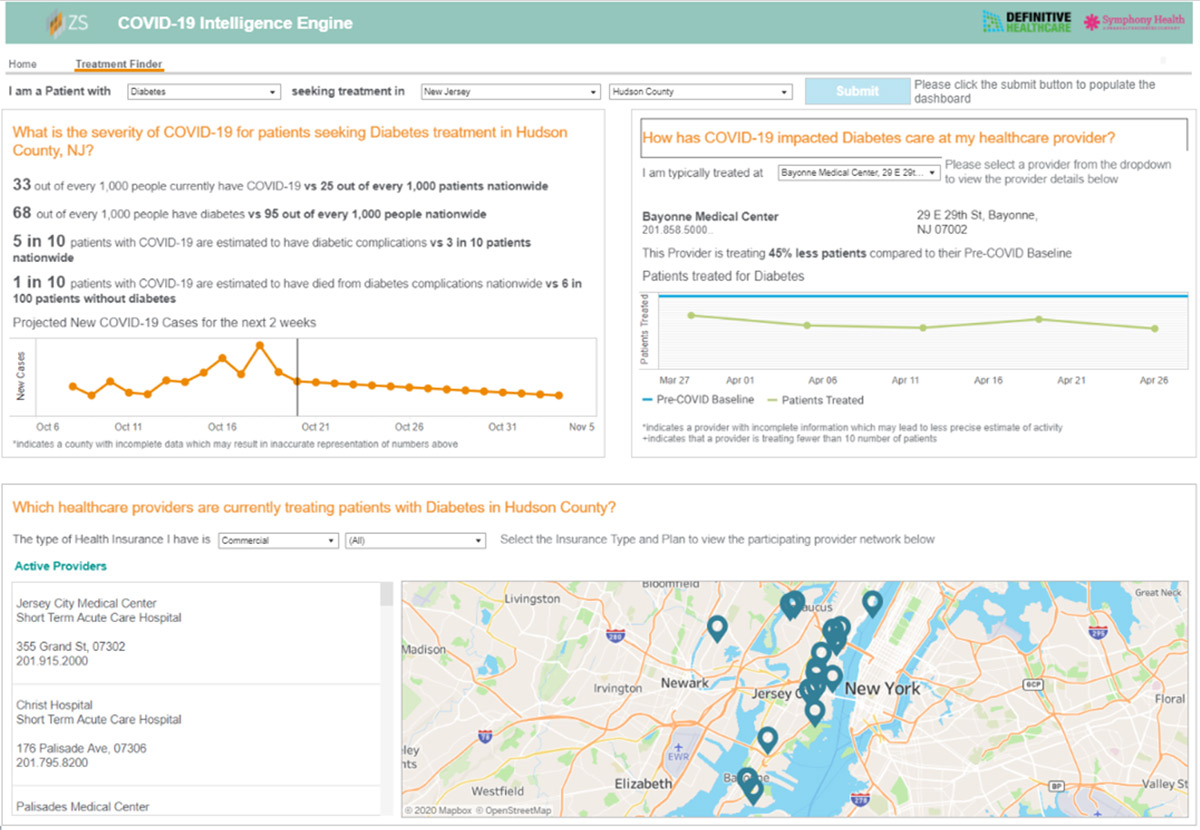
- Treatment finder: A second public access dashboard with near-real-time insights into individual hospital and physician group availability to treat patients for prominent non-COVID-19 diseases. This dashboard allows you to select a specific non-COVID-19 disease and identify the estimated number of COIVD-19-infected people in their geography with the disease, mortality rates, and the individual providers that are accepting patients with a specific disease and health insurance.
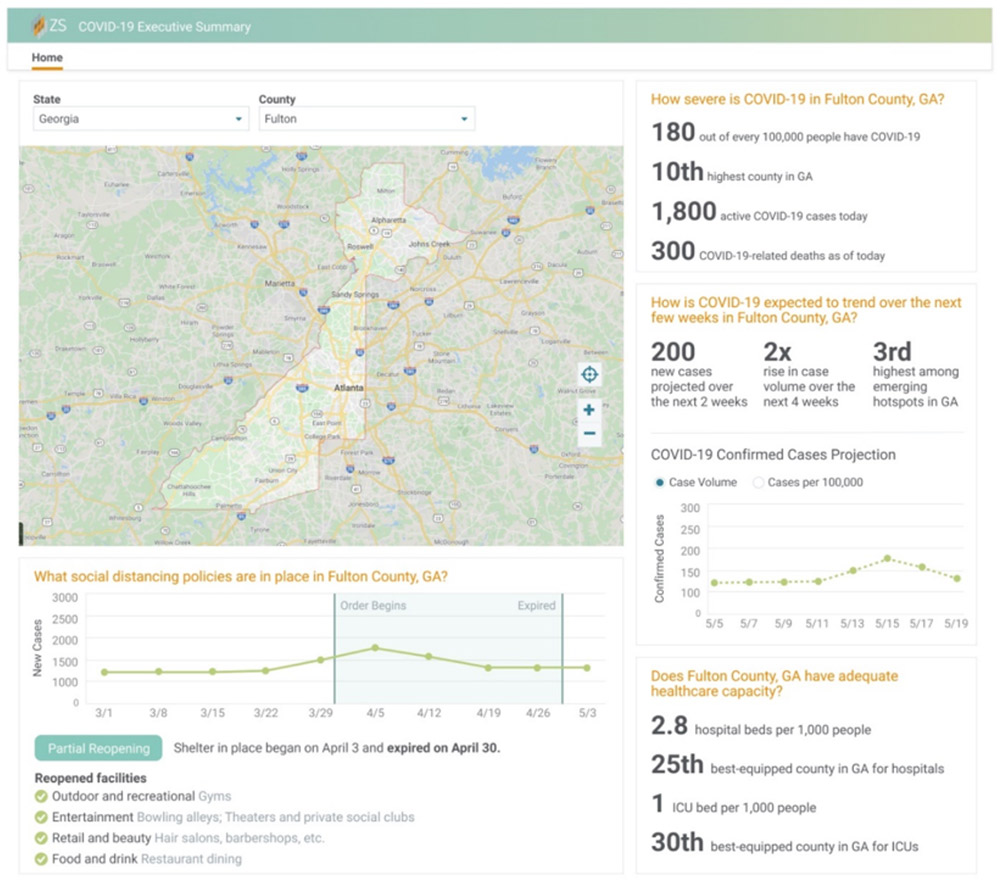
Following image represents Intelligence Engine screen with COVID-19 insights for a selected county:
Following image represents Intelligence engine screen that allows patients to find Hospitals / Physician offices that are open & accepting patients:
Conclusion
At its core, the ZS Intelligence Engine is a real-time planning tool. The rich set of AWS services and technologies make it possible to ingest data from various third-party sources—public and proprietary sources alike. AWS services used to build the architecture can run on open technologies. For example, building the the data lake would not have been possible without Amazon EMR and Amazon EC2. ZS had already been using Apache spark-based EMR instances—the service behind the REVOTM tool—prior to COVID-19 hitting us. ZS can run its ML models cost-effectively by using EC2 On-Demand Instances. Finally, using Amazon Redshift as a data warehouse solution allows ZS to provide COVID-19 analytical insights efficiently and cost-effectively.
Since the project went live, ZS has catered this product to at least six customers in pharma, biotech, and medical device spaces. They are using this product in a variety of ways, including but not limited to:
- Refining the forecast relating the COVID-19 trajectory to estimate demand for their products
- Assessing the level of openness of healthcare facilities to understand where patients across therapy areas are being treated
- Determining which patients and communities to support, because COVID-19 impacts attitudes and concerns regarding immunity and drug use, and greater unemployment means more reimbursement support requirements
- Readying the education and engagement field force for a mix of in-person and virtual interactions
- Preparing the supply chain to ensure continuity of care
To try out the analysis yourself, see ZS’s COVID-19 Intelligence Engine.
About the Authors

Saunak is a Sr. Solutions Architect with AWS helping customers and partners build data warehouse and scalable data platform on AWS.

Parijat is the current lead of strategy and transformation at ZS. He focuses on mid to small clients that are ready for a transformational process to commercialize new products/portfolio, purchase/sell assets or expand into new markets.

Wenhao has over 10 years of experience in various data science and advanced analytics field. During his time at ZS, he has helped both to build and popularize data science capabilities across many organizations.

Vineeth works with Pharmaceutical & Biotech manufacturers on a broad-spectrum of Commercial issues including Commercial Analytics, Organized provider Strategy & Resource Planning & Deployment.

Arianna is a Strategy, Insights and Planning Consultant in ZS’ High Tech practice. Arianna has extensive experience in working with clients across industries with go to market strategy and commercial effectiveness issues.

Gopi Vikranth is an Associate Principal in ZS’ High Tech Practice. He has extensive experience in helping clients across Retail, HiTech, Hospitality, Pharmaceutical & Insurance sectors leverage BigData & Analytics to drive Topline growth.