AWS Big Data Blog
Category: Amazon Data Firehose

Audit AWS service events with Amazon EventBridge and Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon EventBridge is a serverless event bus that makes it easy to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS […]

Gain insights into your Amazon Kinesis Data Firehose delivery stream using Amazon CloudWatch
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. The volume of data being generated globally is growing at an ever-increasing pace. Data is generated to support an increasing number of use cases, such as IoT, advertisement, gaming, security monitoring, machine […]

Unify log aggregation and analytics across compute platforms
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Our customers want to make sure their users have the best experience running their application on AWS. To make this happen, you need to monitor and fix software problems as quickly as […]

Load CDC data by table and shape using Amazon Kinesis Data Firehose Dynamic Partitioning
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services. Customers already use Amazon Kinesis Data Firehose to ingest raw data […]

Continuous monitoring with Sumo Logic using Amazon Kinesis Data Firehose HTTP endpoints
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon Kinesis Data Firehose streams data to AWS destinations such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, and Amazon OpenSearch Service. Additionally, Kinesis Data Firehose supports destinations to third-party partners. […]

Amazon Data Firehose now supports dynamic partitioning to Amazon S3
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon Data Firehose provides a convenient way to reliably load streaming data into data lakes, data stores, and analytics services. It can capture, transform, and deliver streaming data to Amazon Simple Storage […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]

Streaming Amazon DynamoDB data into a centralized data lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. For organizations moving towards […]

Build seamless data streaming pipelines with Amazon Kinesis Data Streams and Amazon Data Firehose for Amazon DynamoDB tables
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. The global wearables market […]
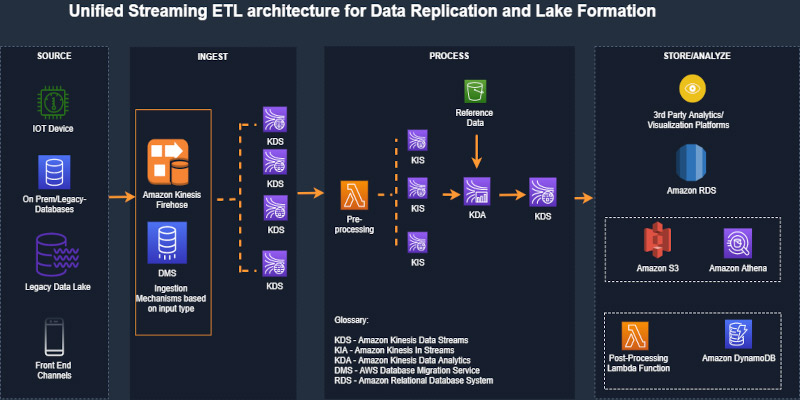
Unified serverless streaming ETL architecture with Amazon Kinesis Data Analytics
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Businesses across the world […]