AWS Big Data Blog
Category: Analytics
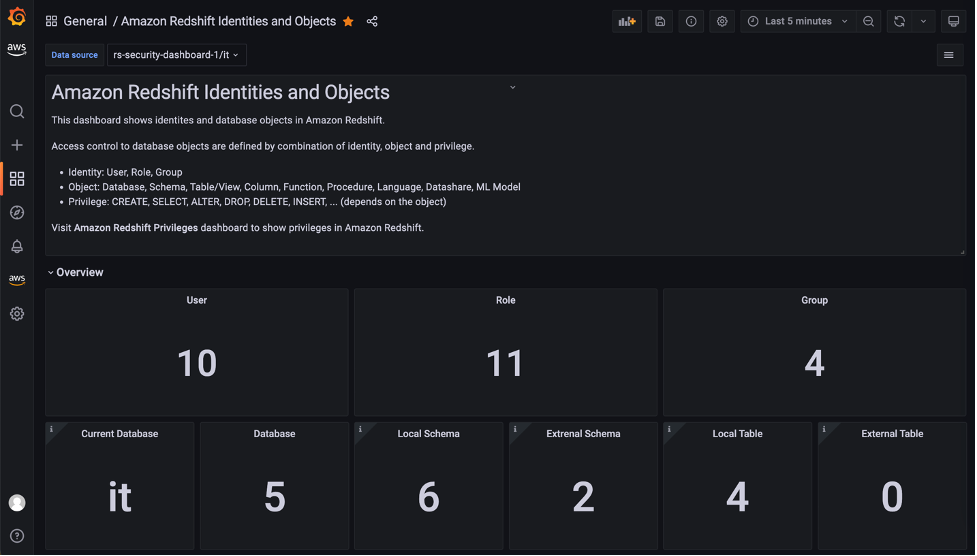
Visualize database privileges on Amazon Redshift using Grafana
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift enables you to use SQL for analyzing structured and semi-structured data with best price performance along with secure access to the data. As more users start querying data in a data warehouse, access control is paramount to protect valuable organizational […]

Build a semantic search engine for tabular columns with Transformers and Amazon OpenSearch Service
Finding similar columns in a data lake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The inability to accurately find and analyze data from disparate sources represents a potential efficiency killer for everyone from data scientists, medical researchers, academics, to financial and government analysts. Conventional […]

Enhance operational insights for Amazon MSK using Amazon Managed Service for Prometheus and Amazon Managed Grafana
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is an event streaming platform that you can use to build asynchronous applications by decoupling producers and consumers. Monitoring of different Amazon MSK metrics is critical for efficient operations of production workloads. Amazon MSK gathers Apache Kafka metrics and sends them to Amazon CloudWatch, where you can […]

Reduce Amazon EMR cluster costs by up to 19% with new enhancements in Amazon EMR Managed Scaling
In June 2020, AWS announced the general availability of Amazon EMR Managed Scaling. With EMR Managed Scaling, you specify the minimum and maximum compute limits for your clusters, and Amazon EMR automatically resizes your cluster for optimal performance and resource utilization. EMR Managed Scaling constantly monitors key workload-related metrics and uses an algorithm that optimizes the […]

Simplify Online Analytical Processing (OLAP) queries in Amazon Redshift using new SQL constructs such as ROLLUP, CUBE, and GROUPING SETS
Amazon Redshift is a fully managed, petabyte-scale, massively parallel data warehouse that makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. We are continuously investing to make analytics easy with Redshift by simplifying SQL constructs and adding new operators. Now we are adding […]

Patterns for enterprise data sharing at scale
Data sharing is becoming an important element of an enterprise data strategy. AWS services like AWS Data Exchange provide an avenue for companies to share or monetize their value-added data with other companies. Some organizations would like to have a data sharing platform where they can establish a collaborative and strategic approach to exchange data […]

Build a real-time GDPR-aligned Apache Iceberg data lake
Data lakes are a popular choice for today’s organizations to store their data around their business activities. As a best practice of a data lake design, data should be immutable once stored. But regulations such as the General Data Protection Regulation (GDPR) have created obligations for data operators who must be able to erase or […]

Introducing AWS Glue crawlers using AWS Lake Formation permission management
Data lakes provide a centralized repository that consolidates your data at scale and makes it available for different kinds of analytics. AWS Glue crawlers are a popular way to scan data in a data lake, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog. AWS Lake […]

Configure ADFS Identity Federation with Amazon QuickSight
Amazon QuickSight Enterprise edition can integrate with your existing Microsoft Active Directory (AD), providing federated access using Security Assertion Markup Language (SAML) to dashboards. Using existing identities from Active Directory eliminates the need to create and manage separate user identities in AWS Identity Access Management (IAM). Federated users assume an IAM role when access is requested through an […]

How Vanguard made their technology platform resilient and efficient by building cross-Region replication for Amazon Kinesis Data Streams
This is a guest post co-written with Raghu Boppanna from Vanguard. At Vanguard, the Enterprise Advice line of business improves investor outcomes through digital access to superior, personalized, and affordable financial advice. They made it possible, in part, by driving economies of scale across the globe for investors with a highly resilient and efficient technical […]