AWS Big Data Blog
Category: Analytics

Cross-account integration between SaaS platforms using Amazon AppFlow
Implementing an effective data sharing strategy that satisfies compliance and regulatory requirements is complex. Customers often need to share data between disparate software as a service (SaaS) platforms within their organization or across organizations. On many occasions, they need to apply business logic to the data received from the source SaaS platform before pushing it […]

AWS recognized as a Challenger in the 2023 Gartner Magic Quadrant for Analytics and Business Intelligence Platforms
AWS has been named a Challenger in the 2023 Gartner Magic Quadrant for Analytics and Business Intelligence (ABI) Platforms. Previously, AWS was positioned as a Niche player in the Magic Quadrant for ABI platforms. The Gartner Magic Quadrant evaluates 20 ABI companies based on their Ability to Execute and Completeness of Vision. In our view, […]
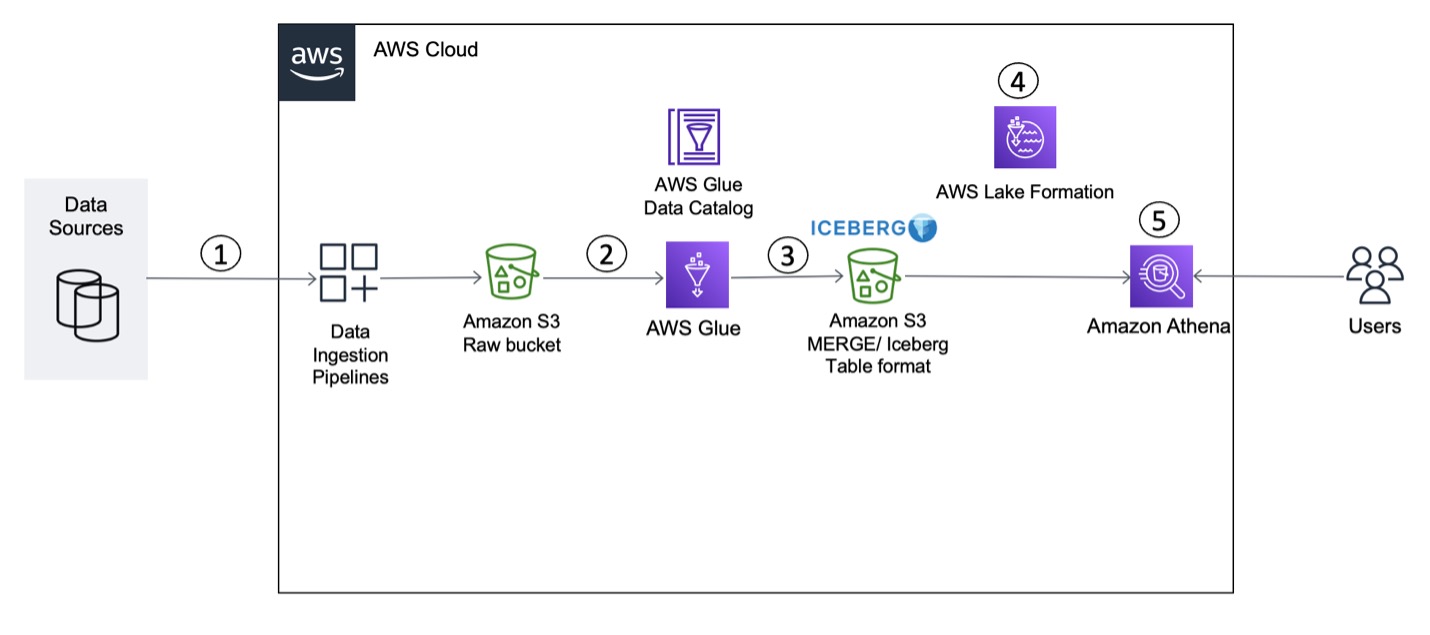
Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena
Building a data lake on Amazon Simple Storage Service (Amazon S3) provides numerous benefits for an organization. It allows you to access diverse data sources, build business intelligence dashboards, build AI and machine learning (ML) models to provide customized customer experiences, and accelerate the curation of new datasets for consumption by adopting a modern data […]

Simplify and speed up Apache Spark applications on Amazon Redshift data with Amazon Redshift integration for Apache Spark
Customers use Amazon Redshift to run their business-critical analytics on petabytes of structured and semi-structured data. Apache Spark is a popular framework that you can use to build applications for use cases such as ETL (extract, transform, and load), interactive analytics, and machine learning (ML). Apache Spark enables you to build applications in a variety […]

Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor
In a modern data architecture, unified analytics enable you to access the data you need, whether it’s stored in a data lake or a data warehouse. In particular, we have observed an increasing number of customers who combine and integrate their data into an Amazon Redshift data warehouse to analyze huge data at scale and […]

Get maximum value out of your cloud data warehouse with Amazon Redshift
Every day, customers are challenged with how to manage their growing data volumes and operational costs to unlock the value of data for timely insights and innovation, while maintaining consistent performance. Data creation, consumption, and storage are predicted to grow to 175 zettabytes by 2025, forecasted by the 2022 IDC Global DataSphere report. As data […]

Automate discovery of data relationships using ML and Amazon Neptune graph technology
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to […]

Accelerate HiveQL with Oozie to Spark SQL migration on Amazon EMR
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. Apache Hive has performed pretty well for a long time. But with advancements in infrastructure such as cloud computing and multicore machines with large RAM, Apache Spark started to gain visibility by […]
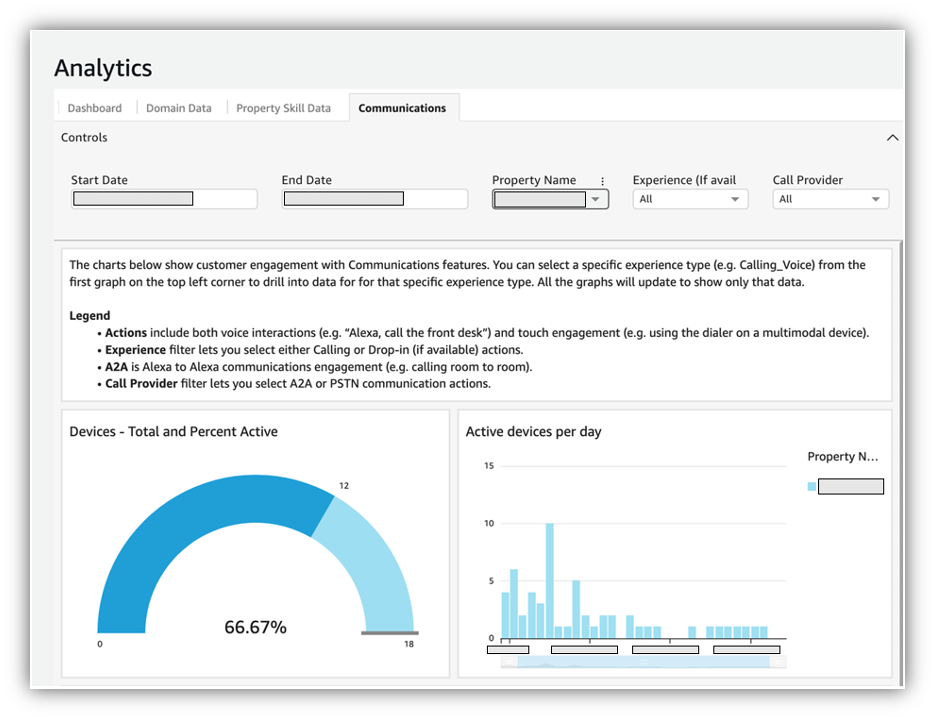
Alexa Smart Properties creates value for hospitality, senior living, and healthcare properties with Amazon QuickSight Embedded
This is a guest post by Preet Jassi from Alexa Smart Properties. Alexa Smart Properties (ASP) is powered by a set of technologies that property owners, property managers, and third-party solution providers can use to deploy and manage Alexa-enabled devices at scale. Alexa can simplify tasks like playing music, controlling lights, or communicating with on-site […]

Configure SAML federation for Amazon OpenSearch Serverless with AWS IAM Identity Center
Amazon OpenSearch Serverless is a serverless option of Amazon OpenSearch Service that makes it easy for you to run large-scale search and analytics workloads without having to configure, manage, or scale OpenSearch clusters. It automatically provisions and scales the underlying resources to deliver fast data ingestion and query responses for even the most demanding and […]