AWS Big Data Blog
Category: Expert (400)

Securely connect Kafka client applications to your Amazon MSK Serverless cluster from different VPCs and AWS accounts
In this post, we show you how Kafka clients can use Zilla Plus to securely access your MSK Serverless clusters through Identity and Access Management (IAM) authentication over PrivateLink, from as many different AWS accounts or VPCs as needed. We also show you how the solution provides a way to support a custom domain name for your MSK Serverless cluster.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 2
(Continued from Part 1) In this post, we show how you can give on-premises clients and spoke account resources private access to OpenSearch Serverless collections distributed across multiple business unit accounts.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 1
In this post, we show how organizations can provide secure, private access to multiple Amazon OpenSearch Serverless collections from both on-premises environments and distributed AWS accounts using a single centralized interface VPC endpoint and Route 53 Profiles.

Extract data from Amazon Aurora MySQL to Amazon S3 Tables in Apache Iceberg format
In this post, you learn how to set up an automated, end-to-end solution that extracts tables from Amazon Aurora MySQL Serverless v2 and writes them to Amazon S3 Tables in Apache Iceberg format using AWS Glue.

Scale fine-grained permissions across warehouses with Amazon Redshift and AWS IAM Identity Center
This post provides a comprehensive technical walkthrough for implementing Amazon Redshift federated permissions with AWS IAM Identity Center to help achieve scalable data governance across multiple data warehouses. It demonstrates a practical architecture where an Enterprise Data Warehouse (EDW) serves as the producer data warehouse with centralized policy definitions, helping automatically enforce security policies to consuming Sales and Marketing data warehouses without manual reconfiguration.

Reducing costs for shuffle-heavy Apache Spark workloads with serverless storage for Amazon EMR Serverless
In this post, we explore the cost improvements we observed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper look at how serverless storage helps reduce costs for shuffle-heavy Spark workloads, and we outline practical guidance on identifying the types of queries that can benefit most from enabling serverless storage in your EMR Serverless Spark jobs.

Optimize HBase reads with bucket caching on Amazon EMR
In this post, we demonstrate how to improve HBase read performance by implementing bucket caching on Amazon EMR. Our tests reduced latency by 57.9% and improved throughput by 138.8%. This solution is particularly valuable for large-scale HBase deployments on Amazon S3 that need to optimize read performance while managing costs.
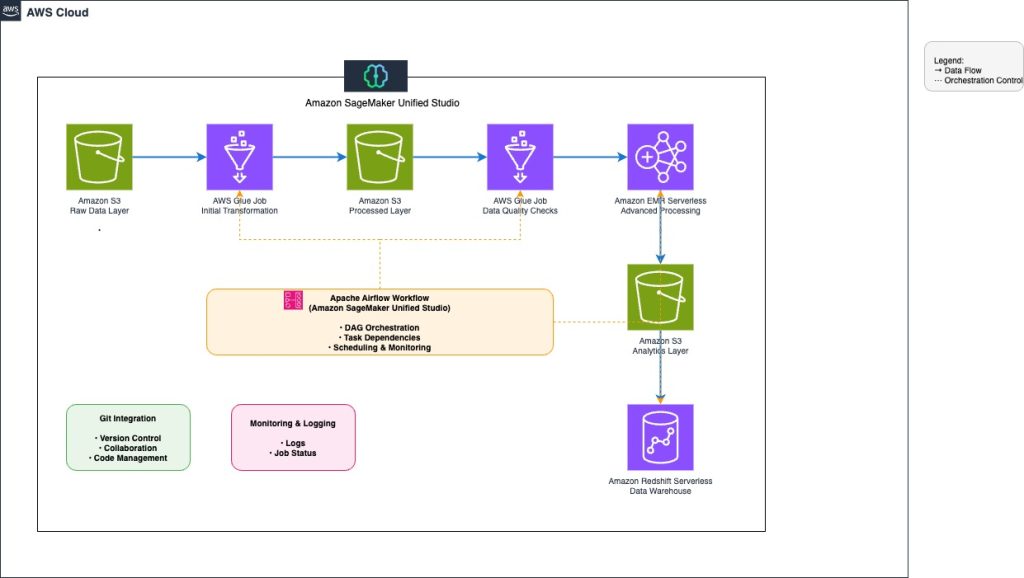
Orchestrate end-to-end scalable ETL pipeline with Amazon SageMaker workflows
This post explores how to build and manage a comprehensive extract, transform, and load (ETL) pipeline using SageMaker Unified Studio workflows through a code-based approach. We demonstrate how to use a single, integrated interface to handle all aspects of data processing, from preparation to orchestration, by using AWS services including Amazon EMR, AWS Glue, Amazon Redshift, and Amazon MWAA. This solution streamlines the data pipeline through a single UI.
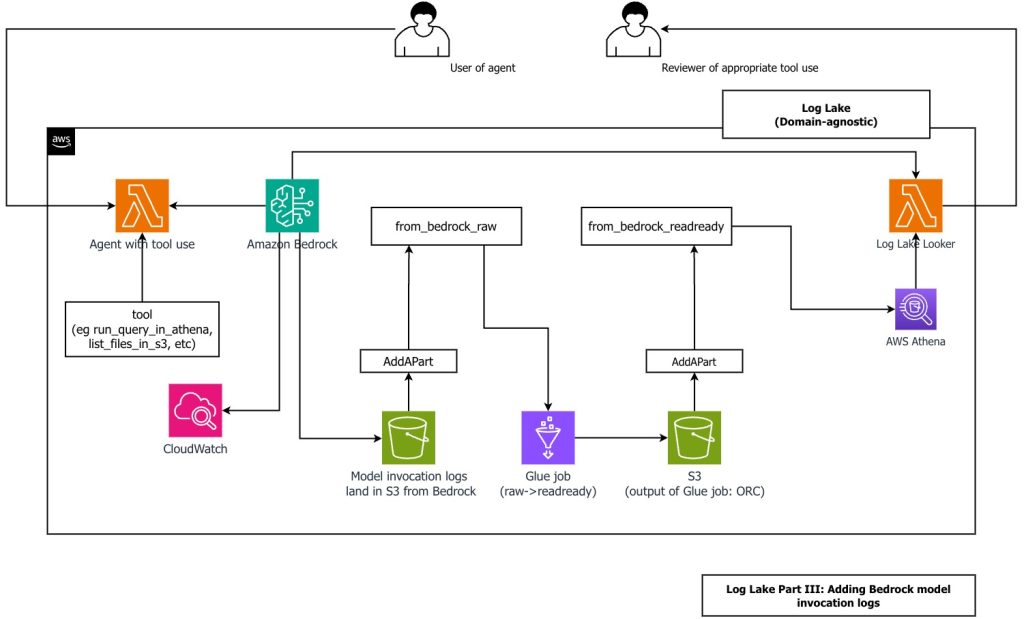
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.
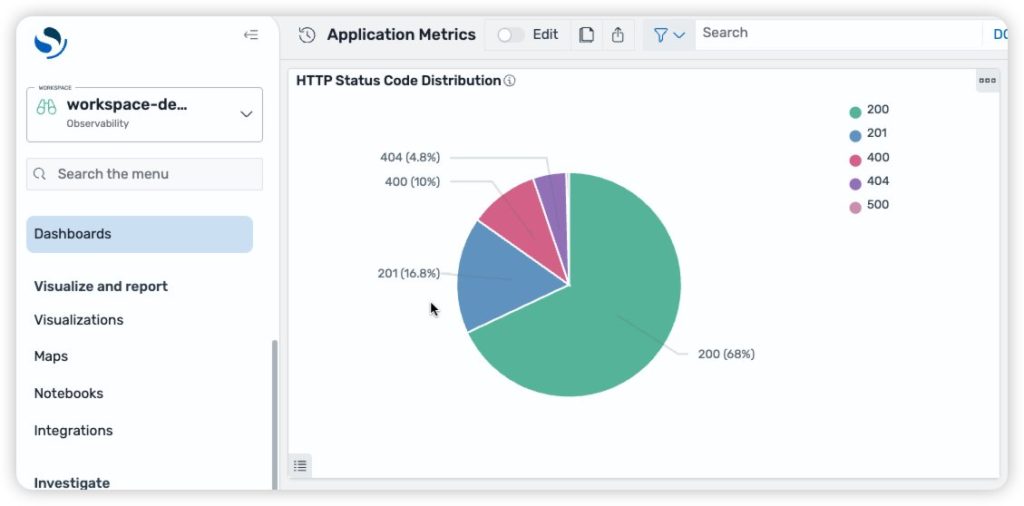
Managing Amazon OpenSearch UI infrastructure as code with AWS CDK
As organizations scale their observability and analytics capabilities across multiple AWS Regions and environments, maintaining consistent dashboards becomes increasingly complex. Teams often spend hours manually recreating dashboards, creating workspaces, linking data sources, and validating configurations across deployments—a repetitive and error-prone process that slows down operational visibility. The next generation OpenSearch UI in Amazon OpenSearch Service […]