AWS Big Data Blog
Category: Learning Levels

How Fresenius Medical Care aims to save dialysis patient lives using real-time predictive analytics on AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post is co-written by Kanti Singh, Director of Data & Analytics at Fresenius Medical Care. Fresenius Medical Care is the world’s leading provider of kidney care […]

Reduce network traffic costs of your Amazon MSK consumers with rack awareness
May 2025: This post was reviewed and the CloudFormation template was updated for accuracy Amazon Managed Streaming for Apache Kafka (Amazon MSK) runs Apache Kafka clusters for you in the cloud. Although using cloud services means you don’t have to manage racks of servers any more, we take advantage of rack aware features in Apache […]

New row and column interactivity options for tables and pivot tables in Amazon QuickSight – Part 1
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to create and deliver insights to everyone in your organization. You can make your data come to life with rich interactive charts and create beautiful dashboards to share with thousands of users, either directly within a QuickSight application, or embedded in […]

Introducing AWS Glue interactive sessions for Jupyter
Interactive Sessions for Jupyter is a new notebook interface in the AWS Glue serverless Spark environment. Starting in seconds and automatically stopping compute when idle, interactive sessions provide an on-demand, highly-scalable, serverless Spark backend to Jupyter notebooks and Jupyter-based IDEs such as Jupyter Lab, Microsoft Visual Studio Code, JetBrains PyCharm, and more. Interactive sessions replace […]
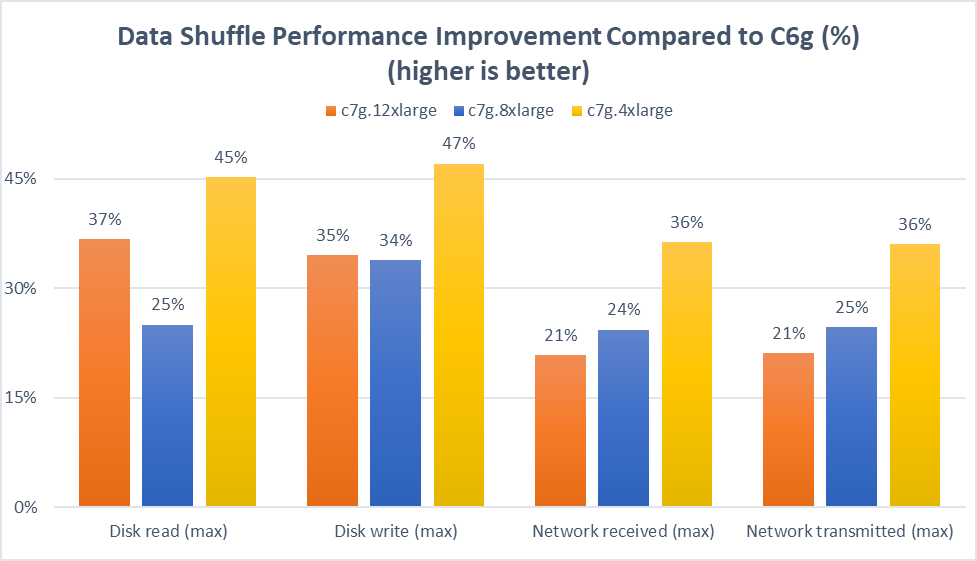
Amazon EMR on EKS gets up to 19% performance boost running on AWS Graviton3 Processors vs. Graviton2
Amazon EMR on EKS is a deployment option that enables you to run Spark workloads on Amazon Elastic Kubernetes Service (Amazon EKS) easily. It allows you to innovate faster with the latest Apache Spark on Kubernetes architecture while benefiting from the performance-optimized Spark runtime powered by Amazon EMR. This deployment option elects Amazon EKS as […]

Build a pseudonymization service on AWS to protect sensitive data: Part 1
According to an article in MIT Sloan Management Review, 9 out of 10 companies believe their industry will be digitally disrupted. In order to fuel the digital disruption, companies are eager to gather as much data as possible. Given the importance of this new asset, lawmakers are keen to protect the privacy of individuals and […]
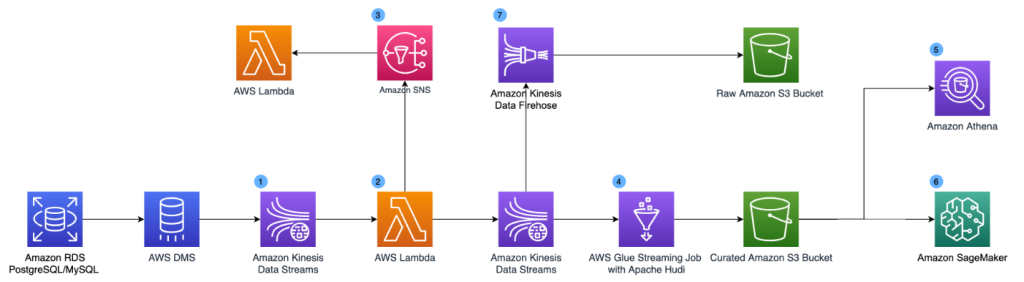
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platform
This is a guest post by Kevin Chun, Staff Software Engineer in Core Engineering at NerdWallet. NerdWallet’s mission is to provide clarity for all of life’s financial decisions. This covers a diverse set of topics: from choosing the right credit card, to managing your spending, to finding the best personal loan, to refinancing your mortgage. […]

Forwood Safety uses Amazon QuickSight Q to extend life-saving safety analytics to larger audiences
This is a guest post by Faye Crompton from Forwood Safety. Forwood provides fatality prevention solutions to organizations across the globe. At Forwood Safety, we have a laser focus on saving lives. Our solutions, which provide full content and proven methodology via verification tools and analytical capabilities, have one purpose: eliminating fatalities in the workplace. […]
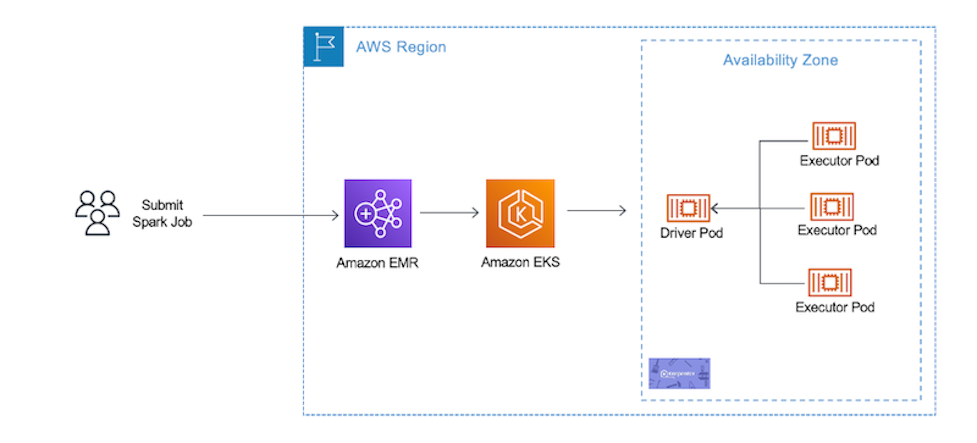
Design patterns to manage Amazon EMR on EKS workloads for Apache Spark
Amazon EMR on Amazon EKS enables you to submit Apache Spark jobs on demand on Amazon Elastic Kubernetes Service (Amazon EKS) without provisioning clusters. With EMR on EKS, you can consolidate analytical workloads with your other Kubernetes-based applications on the same Amazon EKS cluster to improve resource utilization and simplify infrastructure management. Kubernetes uses namespaces to provide isolation between […]

Best practices to optimize cost and performance for AWS Glue streaming ETL jobs
AWS Glue streaming extract, transform, and load (ETL) jobs allow you to process and enrich vast amounts of incoming data from systems such as Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK), or any other Apache Kafka cluster. It uses the Spark Structured Streaming framework to perform data processing in near-real […]