AWS Big Data Blog
Tag: Amazon SageMaker
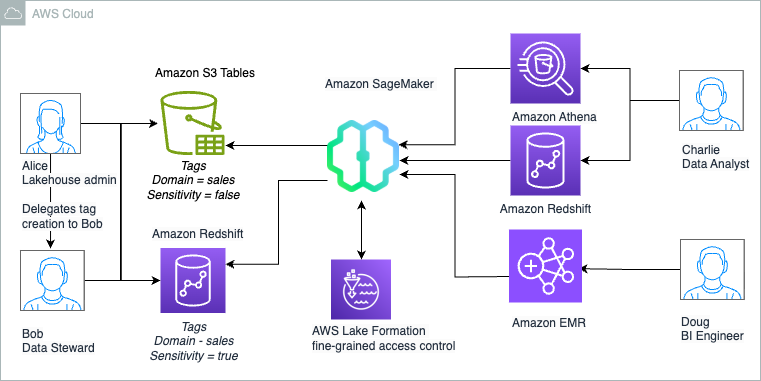
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Develop and deploy a generative AI application using Amazon SageMaker Unified Studio
In this post, we demonstrate how to use Amazon Bedrock Flows in SageMaker Unified Studio to build a sophisticated generative AI application for financial analysis and investment decision-making.

Automate data lineage in Amazon SageMaker using AWS Glue Crawlers supported data sources
In this post, we explore its real-world impact through the lens of an ecommerce company striving to boost their bottom line. To illustrate this practical application, we walk you through how you can use the prebuilt integration between SageMaker Catalog and AWS Glue crawlers to automatically capture lineage for data assets stored in Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.

Accelerate your data quality journey for lakehouse architecture with Amazon SageMaker, Apache Iceberg on AWS, Amazon S3 tables, and AWS Glue Data Quality
This post explores how you can use AWS Glue Data Quality to maintain data quality of S3 Tables and Apache Iceberg tables on general purpose S3 buckets. We’ll discuss strategies for verifying the quality of published data and how these integrated technologies can be used to implement effective data quality workflows.

Connect, share, and query where your data sits using Amazon SageMaker Unified Studio
In this blog post, we will demonstrate how business units can use Amazon SageMaker Unified Studio to discover, subscribe to, and analyze these distributed data assets. Through this unified query capability, you can create comprehensive insights into customer transaction patterns and purchase behavior for active products without the traditional barriers of data silos or the need to copy data between systems.

Manage access controls in generative AI-powered search applications using Amazon OpenSearch Service and Amazon Cognito
In this post, we show you how to manage user access to enterprise documents in generative AI-powered tools according to the access you assign to each persona. This post illustrates how to build a document search RAG solution that makes sure only authorized users can access and interact with specific documents based on their roles, departments, and other relevant attributes. It combines OpenSearch Service and Amazon Cognito custom attributes to make a tag-based access control mechanism that makes it straightforward to manage at scale.

Create, train, and deploy Amazon Redshift ML model integrating features from Amazon SageMaker Feature Store
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]

Optimize Python ETL by extending Pandas with AWS Data Wrangler
April 2024: This post was reviewed for accuracy. Developing extract, transform, and load (ETL) data pipelines is one of the most time-consuming steps to keep data lakes, data warehouses, and databases up to date and ready to provide business insights. You can categorize these pipelines into distributed and non-distributed, and the choice of one or […]
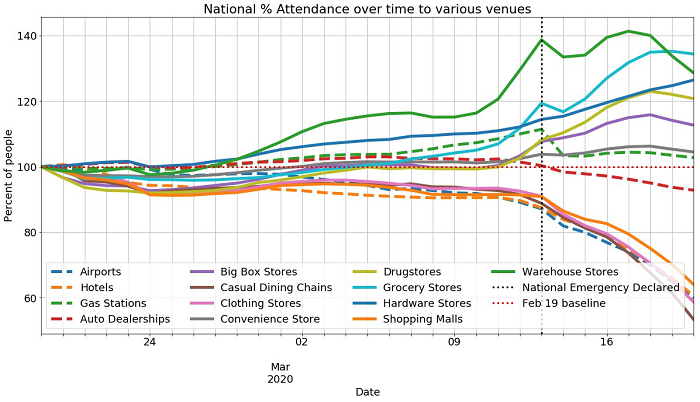
Exploring the public AWS COVID-19 data lake
This post walks you through accessing the AWS COVID-19 data lake through the AWS Glue Data Catalog via Amazon SageMaker or Jupyter and using the open-source AWS Data Wrangler library. AWS Data Wrangler is an open-source Python package that extends the power of Pandas library to AWS and connects DataFrames and AWS data-related services (such as Amazon Redshift, Amazon S3, AWS Glue, Amazon Athena, and Amazon EMR). For more information about what you can build by using this data lake, see the associated public Jupyter notebook on GitHub.