AWS for Industries
Building a cloud-based EV charging monitoring platform with real-time AI analytics
The transition to electric mobility is accelerating worldwide, creating a critical operational challenge for Charge Point Operators (CPOs): how do you monitor and maintain thousands of electric vehicle (EV) charging points across vast geographic areas while ensuring maximum uptime and customer satisfaction?
In this post, we share how Iberdrola-BP Pulse in conjunction with GaleoTech, a systems integrator specialized in Internet of Things (IoT) for the energy sector, built EVBrain—a cloud-based platform on AWS that enables real-time monitoring, proactive incident detection, and AI-powered analytics for EV charging infrastructure across Spain. EVBrain processes data from hundreds of charging points using the Open Charge Point Protocol (OCPP), detecting anomalies before they impact customers and providing operators with actionable intelligence to maximize charger availability.
The challenge: Providing EV charger reliability at scale
As Europe’s EV charging market experiences explosive growth, CPOs face several operational challenges:
- Minimizing downtime – Communication failures, hardware faults, and software anomalies can render chargers unavailable, directly impacting revenue and customer trust
- Reactive issue management – Traditional monitoring lacks proactive detection, meaning incidents are only spotted after they occur and users are already affected
- Limited visibility – Operators need comprehensive insights across their entire network, from individual charging points to the electrical infrastructure powering them
- Operational complexity – Managing hundreds of charging stations requires processing thousands of OCPP messages per second with sub-minute latency
Solution overview
EVBrain addresses these challenges through a fully serverless architecture built on AWS managed services. The platform processes OCPP messages in real time, automatically detects 26 distinct types of incidents (including connector faults, boot cycles, and anomalous energy delivery), and provides operators with six comprehensive dashboards for monitoring network health.
Key capabilities include:
- Near-real-time monitoring with sub-minute latency for communication failures and hardware faults
- Proactive incident detection that identifies issues before customer complaints
- An AI-powered assistant using Amazon Bedrock for natural language queries on recharges, incidents, and metrics with Agent-User Interaction (AG-UI) protocol integration
- Extended monitoring of Low Voltage Cabinets (LVCs) that supply power to charging stations
- Remote operations capability for circuit breaker management
The following diagram illustrates the solution architecture.
Figure 1. High-level architecture diagram of EVBrain on AWS
The EVBrain architecture follows AWS Well-Architected Framework principles and consists of four distinct layers: ingestion, processing, application, and presentation.
Ingestion layer
AWS IoT Core manages MQTT connections from Iberdrola backend (CPMS), authenticating devices using X.509 certificates. Messages flow into Amazon Simple Queue Service (Amazon SQS) queues—separate standard queues handle OCPP requests and responses, with dead-letter queues (DLQs) for error management. This decoupling makes sure the system can handle traffic spikes without message loss.
We use SQS standard queues rather than FIFO because the vast majority of OCPP messages are independent and benefit from parallel processing. For the specific race conditions that do require ordering, the processing AWS Lambda function persists the in-flight state in Amazon DynamoDB and reroutes the affected message to a dedicated SQS standard delay queue with a configured delivery delay, so the retry happens after its counterpart has landed.
Processing layer
Lambda functions process messages in real time:
- Request/response writers – Persist OCPP messages for audit and analysis.
- Uptime writers – Calculate availability metrics across the network.
- Incident processors – Run 26 detection algorithms co-designed with our operations team. They combine deterministic rules expressed as JsonLogic and stored in DynamoDB (so rules can be tuned without redeploying) with lightweight analytical detectors that query Tinybird over rolling time windows, plus a deduplication guard that avoids re-notifying while the same incident remains open for a charger.
- Mailing writers – Send critical alerts to operations teams.
Processed data flows to Tinybird for real-time analytics, Amazon Aurora for PostgreSQL for relational metadata, and DynamoDB for high-performance NoSQL operations.
Application layer
The backend API runs on Lambda behind Amazon API Gateway, which provides throttling and JWT authentication. Amazon Cognito handles identity management, while AWS WAF protects against common web exploits. Amazon ElastiCache for Redis caches session data, and Amazon Aurora for PostgreSQL runs in Multi-AZ configuration for high availability.
Presentation layer
The single-page application (SPA) is delivered through Amazon Simple Storage Service (Amazon S3) and Amazon CloudFront, providing six main views:
- Dashboard – Network-wide KPIs and real-time status
- Map – Geographic visualization of charging points with status indicators
- Incidents – Detailed incident tracking and resolution workflows
- Analytics – Historical availability metrics and trends (uptime, session, manufacturers, and more)
- Charging sessions – Individual transaction details and analytics
- Asset management – Configuration and metadata for all network assets
The following screenshot shows an example of the EVBrain web application showing the Map view.
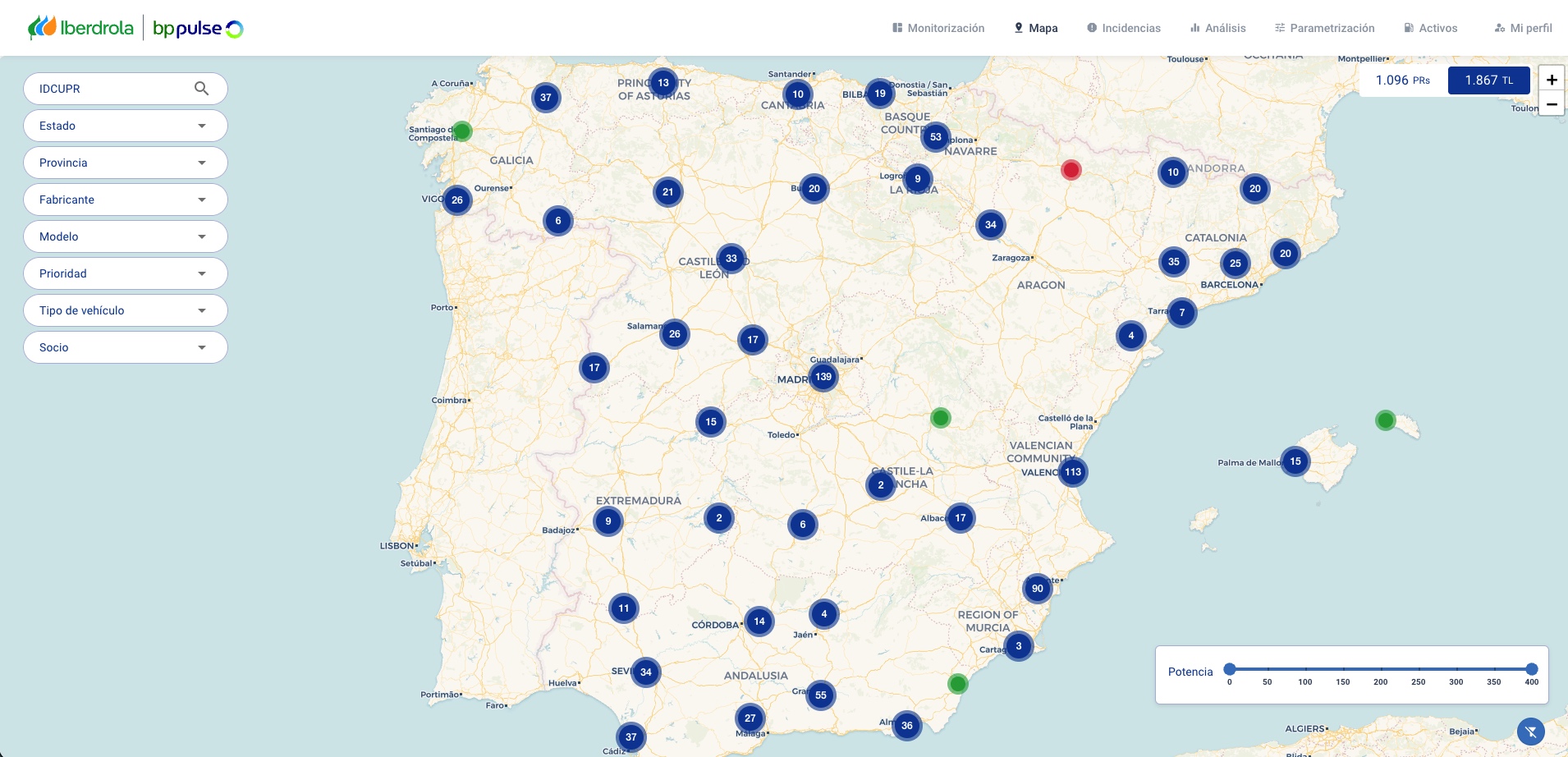
Figure 2. Screenshot of EVBrain web application showing the Map view
Extending monitoring to Low Voltage Cabinets
EVBrain extends beyond charging points to monitor the LVCs that power them. An IoT gateway architecture communicates with Programmable Logic Controllers (PLCs) using Modbus TCP protocol, monitoring voltage, current, power consumption, and critical alarms (door open, emergency stop, temperature).
Bidirectional MQTT communication through AWS IoT Core supports remote operations—operators can open, close, or reset circuit breakers directly from the EVBrain interface. When critical events occur, the system automatically creates incident records in Amazon Aurora for PostgreSQL, so operations teams have visibility across the entire electrical infrastructure.
The following diagram illustrates the monitoring architecture.
Figure 3. Architecture diagram for Low Voltage Cabinet monitoring
The following screenshot shows an example of the information flow diagram for LVC telemetry.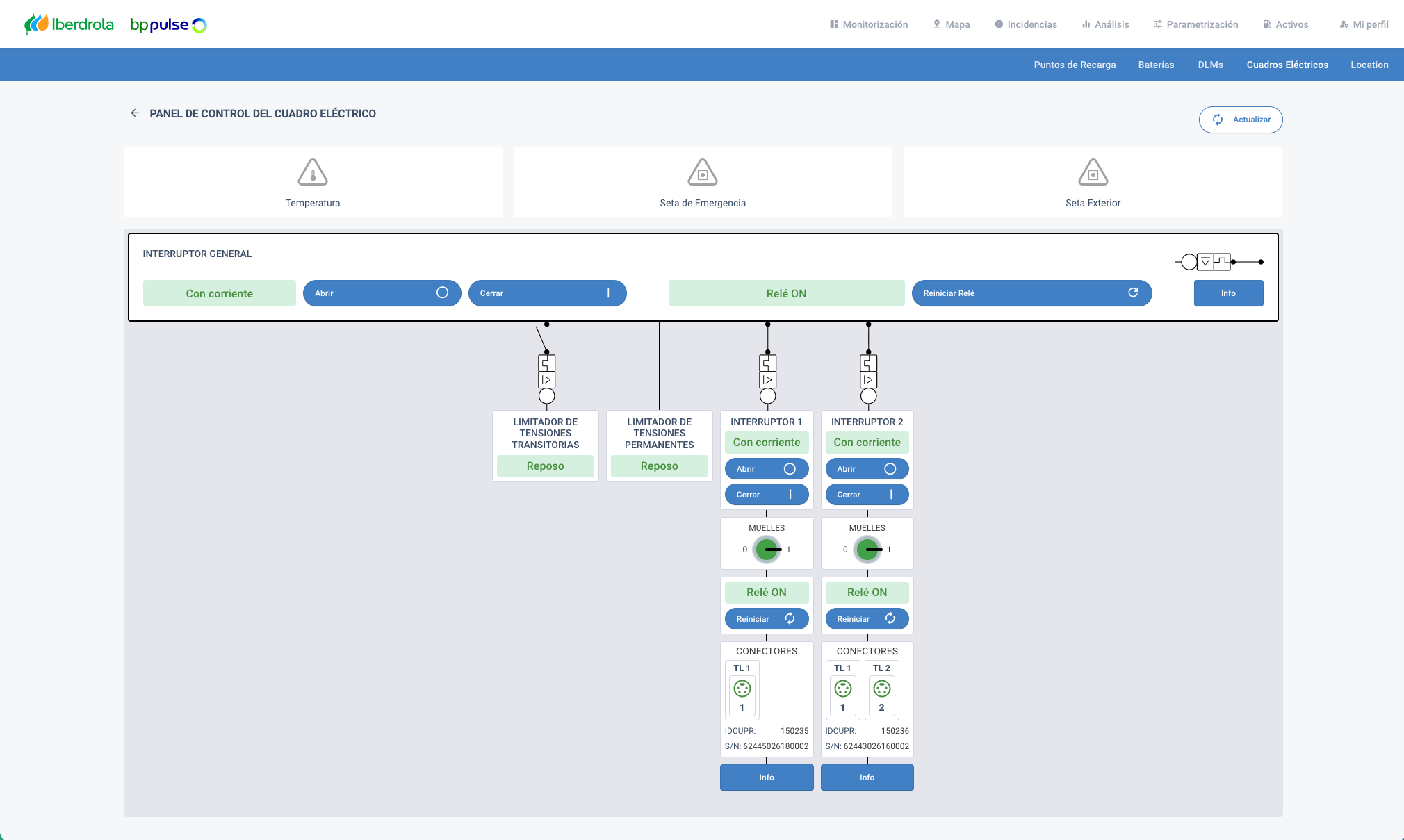
Figure 4. Information flow diagram for Low Voltage Cabinet telemetry
A data flow automatic remediation example
When a charging point in Barcelona reports a StatusNotification with status “Faulted” and error code “06 - ev: v2g comm error” on one of its connectors at 14:23:15 UTC, EVBrain ingests the event within seconds. AWS IoT Core relays the message through Amazon SQS to a Lambda function that persists the raw OCPP payload to the data layer for audit, forwards the record to Tinybird for real-time analytics, and runs the incident detection algorithms. The processor identifies the “Faulted” state, classifies severity as “HIGH”, and writes the incident record to Amazon Aurora for PostgreSQL, where the EVBrain frontend marks the charging point as not available to platform users. In parallel, Amazon Simple Notification Service (Amazon SNS) distributes an alert to the operations team within 2 seconds from detection. Simultaneously, the incident processor evaluates the failure pattern against historical data and determines that, for this specific error code, a remote reboot resolves the fault in over 85% of cases. The system automatically issues an OCPP Reset command through API Gateway to the charging point, which reboots in approximately 30 seconds. When the charger sends its first StatusNotification with an “Available” status at 2 minutes 15 seconds, the processing Lambda function detects the status change and automatically closes the incident in Amazon Aurora for PostgreSQL — no manual intervention is required.
AI-powered analytics with Amazon Bedrock
EVBrain includes an AI-powered assistant built on Amazon Bedrock using Anthropic’s Claude models through the AG-UI protocol for real-time streaming responses. The agent runs on Amazon Bedrock AgentCore Runtime and accesses EVBrain data through an Amazon Bedrock AgentCore Gateway that unifies multiple Model Context Protocol (MCP) servers as tool targets. The primary MCP server is a custom EVBrain MCP Server built with FastMCP and deployed on Amazon Elastic Container Service (Amazon ECS), which wraps the entire EVBrain REST API—exposing read and write operations across platform domains as invocable tools:
- Recharges and sessions – Query individual charging sessions, charging curves, and energy delivery metrics with filtering by date, location, charger, or transaction.
- Incidents and KPIs – Retrieve incident records, manage resolution workflows, and access incident management KPIs such as closing times by severity and open/close evolution.
- Aggregated metrics and assets – Access aggregated metrics (uptime, energy, power, recharges) with monthly, daily, or total views, plus full asset inventory and geolocation data.
- Operational commands (planned) – Future releases will extend the AI assistant with the ability to trigger OCPP commands such as remote reboots, manage electrical panel telemetry, modify asset metadata, and schedule recurring reports and analyses directly from the conversation. The goal is that an operator can ask the assistant for a given report or analysis once, and then configure from the chat that the same output is generated automatically on a recurring basis (for example, daily or weekly) and delivered to one or more recipients through Amazon Simple Email Service (Amazon SES). One-time reports will remain available on demand through the assistant itself.
Through this AI integration, EVBrain now provides operators with natural language-driven tools to monitor the system both proactively and reactively.
The following diagram illustrates the AI assistant architecture, showing AG-UI Server connected to EVBrain MCP through Amazon Bedrock.
Figure 5. AI assistant architecture showing AG-UI Server connected to EVBrain MCP through Amazon Bedrock
The following screenshot shows an example of the chat in the EVBrain application.
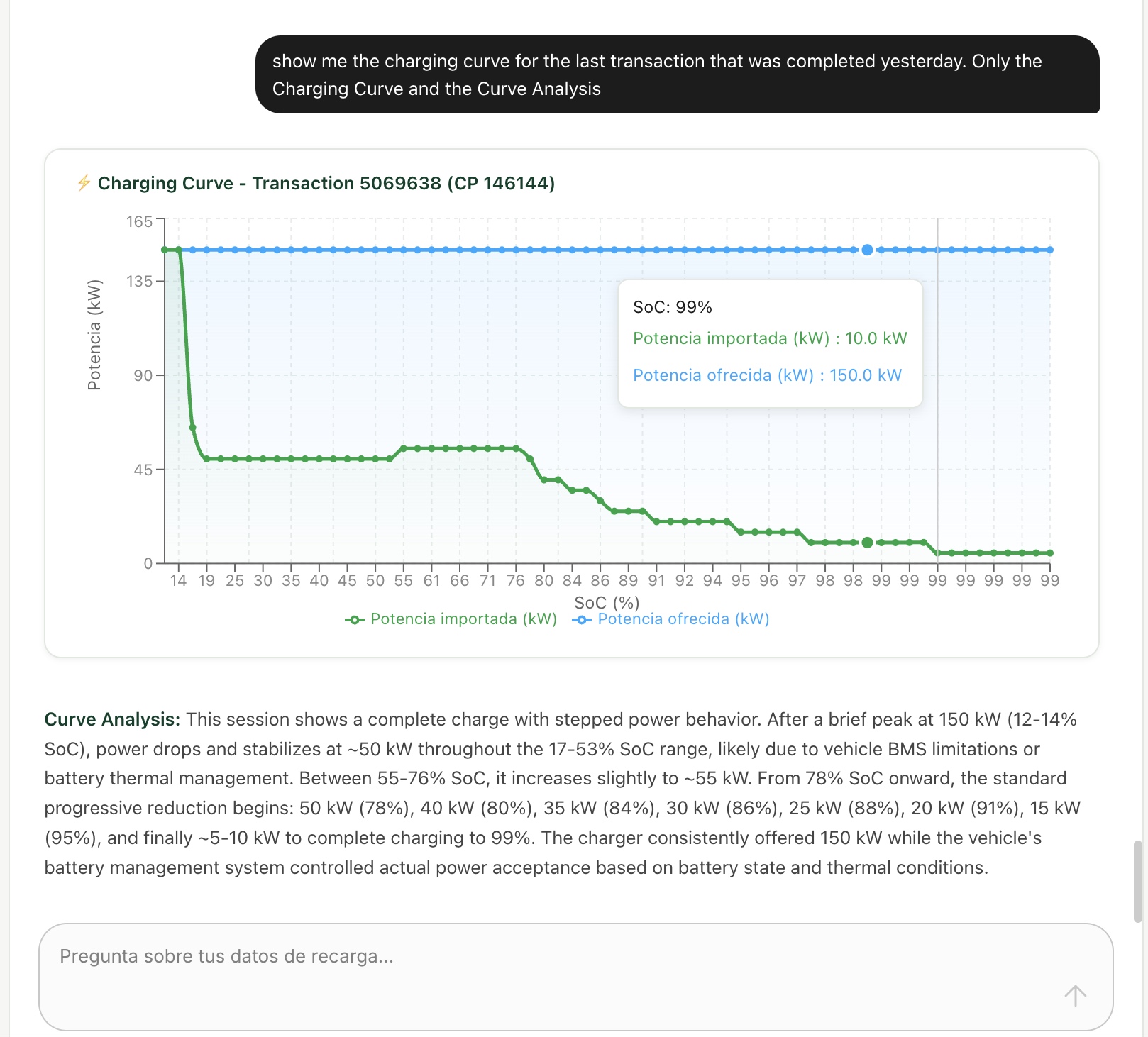
Figure 6. Visualization of the chat in EVBrain application
Security: Defense in depth
EVBrain implements comprehensive security controls:
- Network isolation – Amazon Virtual Private Cloud (Amazon VPC) segmentation with public, private, and protected subnets
- Encryption – Data at rest using AWS Key Management Service (AWS KMS) and in transit using TLS 1.2+
- Identity management – AWS IAM Identity Center for workforce access, Amazon Cognito for application users
- Compliance and monitoring – AWS CloudTrail for audit logging, AWS Config for configuration compliance, and Amazon GuardDuty for threat detection
Results and business impact
Since deployment, EVBrain has delivered measurable business value:
- Maximized uptime – Detection of communication failures and hardware faults within minutes, significantly reducing the mean time to resolution. In 2025, aligned with EVBrain’s adoption and stabilization, the uptime of the EV platform increased by 15%, from 82% to the current 97%.
- Excellence for Drivers – More than half a million recharges in 2025 (over 50,000 recharges per month) with over 17,000 MWh of energy delivered. Currently, there are over 2,000 daily recharges. Looking at the recharge type: 65% are ultra-high power (UHP, <150kW); 25% are high power (HP, >50kW); and less than 10% are low power (LP, <50kW).
- Enhanced operations – Identification of 26 distinct incident types before they impact customers. These 26 types are automatically detected by the platform and reported to the operations team. More than 80% of these incidents are solved before escalating to the field services team. In the last 12 months, the platform has captured approximately 2,000 monthly incidents.
- Operational efficiency – Consolidated monitoring across charging points and electrical infrastructure in a single platform. Currently, 1,152 charging points with 1,973 connectors are connected to EVBrain. The system handles over 500,000 messages per day (OCPP only) and approximately 400 messages per minute. With 1 million rows ingested per day, the EVBrain platform processes 14,000 downstream requests per day at an average full latency of less than 800 milliseconds.
- Scalability – EVBrain will accommodate the business scale-up, which projects 10,000–12,000 charging points by 2030. EVBrain is a fully managed, serverless architecture, providing automatic scaling out-of-the-box to handle network growth without manual intervention. Furthermore, EVBrain has been stress-tested under loads equivalent to 50 times the current data volume (25 million messages per day) using the same architecture, showing no significant changes in latency or other relevant parameters.
Lessons learned and best practices
Building EVBrain taught us several valuable lessons:
- Decouple ingestion from business logic with standard queues – Using SQS standard queues and confining the ordering problem to a targeted retry using a delay queue when the processing Lambda function detects a
StopTransactionarriving before its matchingStartTransactiongave us FIFO-like guardrails only where OCPP requires them, while keeping the rest of the pipeline at full Standard throughput. This pattern was decisive to sustain 500,000 messages per day as of the time of writing and to pass stress tests with 50 times the current volume without re-architecting. - Codify operations knowledge as explicit detectors, not black-box models – Encoding each OCPP failure pattern either as a deterministic JsonLogic rule stored in DynamoDB or as a targeted Tinybird pipe, co-defined with the operations team, proved more effective than generic unsupervised anomaly models. Detections are explainable, tunable per charger family without redeploying, and can be added or retired in isolation—which is how we reached a state where more than 80% of incidents are resolved before escalation to field services.
- Close the detection-to-remediation loop automatically where the data supports it – Pairing the incident detectors with historical resolution data (for example, the communication-dropout pattern that is resolved by a remote reboot in over 85% of cases) lets EVBrain issue OCPP Reset commands without waiting for a human operator, and close the incident automatically when the charger reports “
Available” again. This same pattern was later extended to LVCs, where operators can remotely open, close, or reset circuit breakers from the interface—reusing the same event-driven pipeline for a completely different class of assets. - Separate operational storage from analytical storage from day one – Keeping Amazon Aurora for PostgreSQL as the system of record for incidents and asset metadata, DynamoDB for high-throughput operational state, and Tinybird for time-series analytics on top of the same OCPP stream allowed each workload to scale independently and avoided the typical pattern of a single overloaded database. It is also what made the Amazon Bedrock based AI assistant viable: the MCP tools query each backend for what it is best at, which keeps latency low on the 14,000 downstream requests per day the platform already serves.
- Treat EVBrain as an N1 inside a broader operations chain, not as an island – Designing EVBrain explicitly as a first-line operations platform that automatically resolves what it can and escalates the rest to SiteTracker (the Iberdrola–BP Pulse Field Service tool) to generate the corresponding work order, together with AWS IoT Core MQTT authentication based on per-device X.509 certificates and network segmentation across public, private, and protected subnets, was key to integrating the platform into the existing operational and security perimeter of the joint venture without friction. Defining this boundary early prevented rework when new asset classes (LVCs) and new channels (the AI assistant) were added.
- Use AWS IoT Core Basic Ingest whenever the device does not need a broker – When the device or hardware can model its own publish pattern and does not require bidirectional MQTT messaging—as is the case with the LVC telemetry ingest—we send the payloads through AWS IoT Core Basic Ingest. This bypasses the message broker and routes the data directly through AWS IoT rules into the target AWS services, using AWS IoT Core as a rules-based router rather than as a full broker. Reserving the broker only for truly bidirectional workloads (such as commands to devices) reduced ingest cost meaningfully and simplified the data path.
Conclusion
EVBrain demonstrates how serverless, cloud-based architecture on AWS addresses the operational challenges of large-scale EV charging networks. By combining real-time data processing, advanced analytics, and AI, the platform enables Iberdrola-BP Pulse to deliver reliable charging experiences across Spain.
As the network expands, EVBrain scales automatically while maintaining consistent performance and sub-minute latency.
For organizations building industrial IoT solutions in the energy and mobility sectors, EVBrain illustrates how AWS provides a comprehensive platform that delivers tangible business value through managed services, serverless architecture, and integrated AI capabilities. To start building your own scalable IoT platform today connect with an AWS specialist to discuss your energy and mobility use case.