Artificial Intelligence
Bring structure to diverse documents with Amazon Textract and transformer-based models on Amazon SageMaker
From application forms, to identity documents, recent utility bills, and bank statements, many business processes today still rely on exchanging and analyzing human-readable documents—particularly in industries like financial services and law.
In this post, we show how you can use Amazon SageMaker, an end-to-end platform for machine learning (ML), to automate especially challenging document analysis tasks with advanced ML models.
We walk you through the following high-level steps:
- Collect pre-training data.
- Train and deploy the model.
- Create an end-to-end Optical Character Recognition (OCR) pipeline.
You can find the sample code accompanying the walkthrough on GitHub.
Amazon Textract for structured document extraction
To successfully automate document-driven processes, businesses need tools to extract not just the raw text from received files, but the specific fields, attributes, and structures that are relevant to the process in question. For example, the presence or absence of a specific clause in a contract, or the name and address of an individual from an identity document.
With Amazon Textract, you can already go beyond simple extraction of handwritten or printed text (OCR). The service’s pre-trained structure extraction features offer recovery of higher-level structure including table layouts, key-value pairs (such as on forms), and invoice data—built by AWS, with no custom training or tuning required by you.
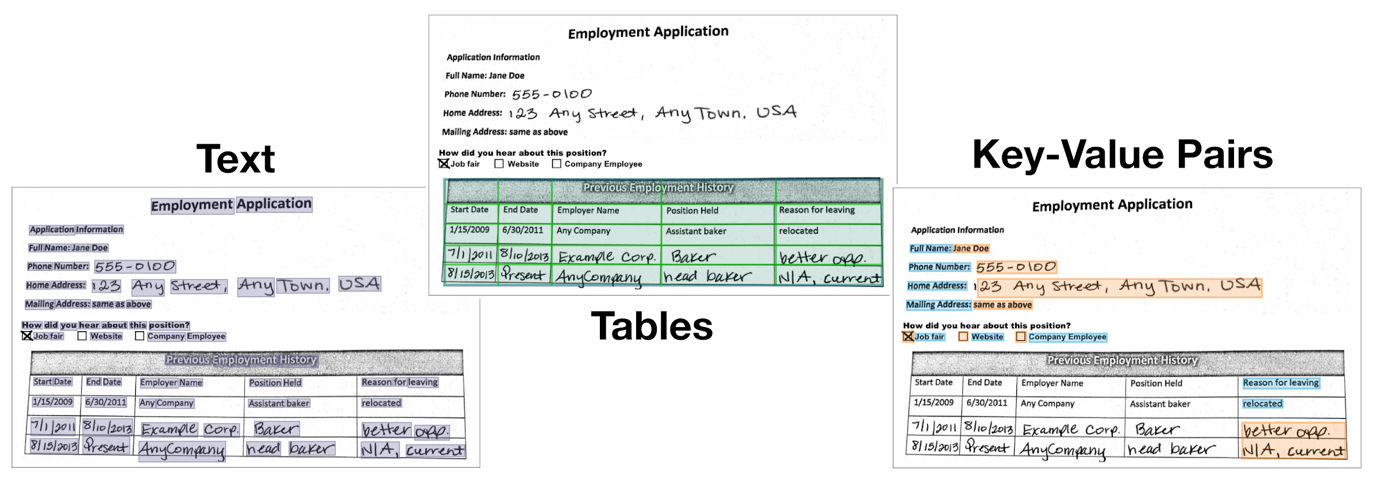
These general-purpose, pre-trained extraction tools preserve the verbatim text of the document without making any use case-specific assumptions. They greatly simplify a wide range of analysis tasks to simple, rule-based logic. For example, you can do the following:
- Loop through the table rows in a company’s balance sheet, mapping the first cell to the standard field in your database (for example
TOTAL CURRENT LIABILITIES:toTotal Current Liabilities) and extracting the currency amounts from the following cells - Loop through the key-value pairs from a completed, scanned application form, and flag any fields that appear not to have been filled out (for example, the key
Email addresshas an empty value or was not detected at all).
These built-in features continue to evolve and improve as we help customers build solutions for a wide range of use cases. However, the world’s documents and businesses are incredibly diverse. In case you need to extract some structure that isn’t suited to simple rule-based logic on these outputs, what additional tools might you explore?
BERT, transformers, and LayoutLM
In recent years, research on attention-based deep learning transformer models has significantly advanced the state-of-the-art in a wide range of text processing tasks, from classification and entity detection, to translation, question answering, and more.
Following the highly influential Attention Is All You Need paper (2017), the field witnessed not just the rise of the now well-known BERT model (2018), but an explosion of similar models based on and expanding related concepts (such as GPT, XLNet, RoBERTa, and many more).
The accuracy and power of transformer-based models is one clear reason they’re of interest, but we can already analyze Amazon Textract-extracted text using off-the-shelf AI services like Amazon Comprehend (for example, to classify text or pick out entity mentions) or Amazon Kendra (for natural language search and question answering). The AWS Document Understanding Solution demonstrates a range of these integrations.
Another, perhaps more interesting, reason to consider these techniques in OCR is that transformer-based models can be adapted to consume the absolute position of words on the page.
Although traditional text models (like RNNs, LSTMs, or even n-gram based methods) account for the order of words in the input, many are quite rigid in their approach of treating text as a linear sequence of words.
In practice, documents aren’t simple strings of words, but rich canvases with features like headings, paragraphs, columns, and tables. Because the input position encoding of models like BERT can incorporate this position information, we can boost performance by training models that learn not just from the content of the text, but the size and placement too. The following diagram illustrates this.
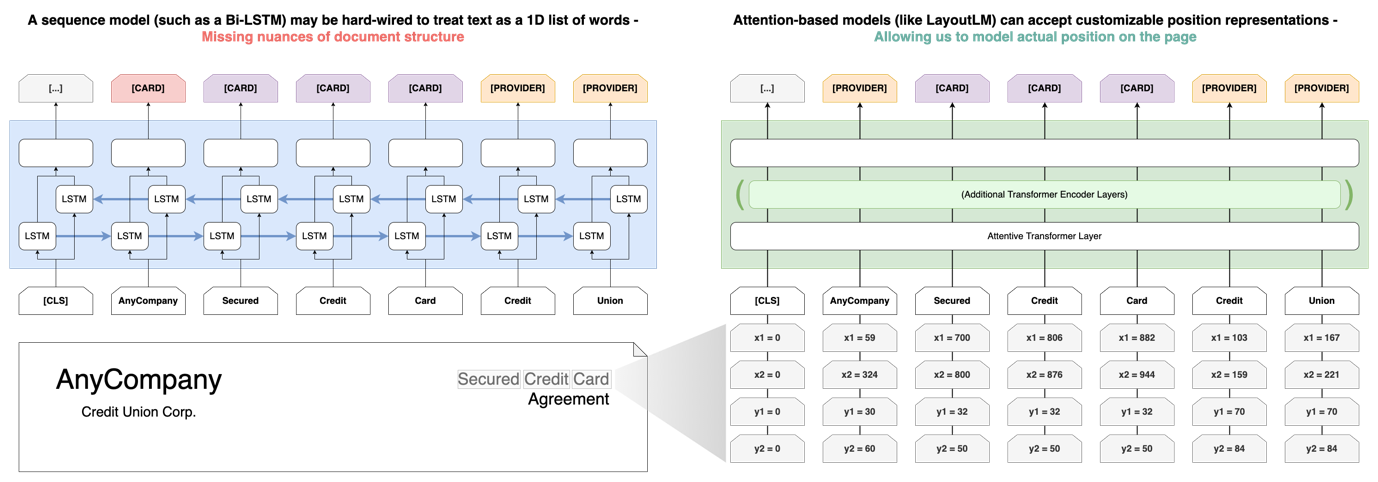
For example, different formats and spacing may make it difficult to build a purely position-based template to extract recipient and sender addresses from a letter, but an ML model using both the content and position of the text may more reliably extract only the address content.
In LayoutLM: Pre-training of Text and Layout for Document Image Understanding (2019), Xu, Li et al. proposed the LayoutLM model using this approach, which achieved state-of-the-art results on a range of tasks by customizing BERT with additional position embeddings.
Although new research will surely continue to evolve, you can already benefit from the available open-source implementations of LayoutLM and other models in this space to automate complex, domain-specific document understanding tasks in a trainable way on top of Amazon Textract.
From idea to application
To demonstrate the technique with publicly available data, we consider extracting information from a particularly challenging corpus: the Credit card agreement database published by the United States’ Consumer Financial Protection Bureau.
This dataset comprises PDFs of credit card agreements offered by hundreds of providers in the US. It includes the full legal terms under which credit is offered, as well as summary information of the kind that might be interesting to potential customers (such as APR interest rates, fees, and charges).

The documents are mostly digitally sourced rather than scans, so the OCR itself isn’t very challenging, but they’re diverse in formatting, structure, and wording. In this sense, they’re representative of many real-world document analysis use cases.
Consider, for example, the process of extracting the annual fee for a card:
- Some providers might include this information in a standardized summary table of disclosures, whereas others might list it within the text of the agreement
- Many providers have introductory offers (which may vary in duration and terms) before the standard annual fee comes into effect
- Some providers explicitly detail that the charge is applied in monthly installments, whereas others might simply list the annual amount
- Some providers group multiple cards under a single agreement document, whereas others split out one agreement per card offered
We train a single example model to extract 19 such fields from these documents (see the following screenshot), including:
- APR interest rates – Split out by categories such as purchases, balance transfers, introductory, and penalty rates
- Fees – Such as annual charges, foreign transaction fees, and penalties for late payment
- Longer clauses of interest – Such as the calculation of minimum payment, and local terms applicable to residents of certain states
- Basic information – Such as the name and address of the card provider, the names of cards, and the agreement effective date

The code for the example solution is provided on GitHub, which you can deploy and follow along.
To get started, first follow the instructions to deploy the solution stack and download the walkthrough notebooks in SageMaker.
Collect pre-training data
Transformer models like LayoutLM are typically pre-trained on a large amount of unlabeled data to learn general patterns of language (and, for position-aware models, page structure). In this way, specific downstream tasks can be learned with relatively little labeled data—a process commonly called fine-tuning.
For instance, in a legal use case, you may have a large number of historical legal contracts and documents, but only a few are annotated with the locations of particular clauses of interest (the task you want the model to perform).

Our first task then is to compile a representative collection of training documents digitized with Amazon Textract and have human labelers annotate some percentage of the dataset with the actual labels we want the model to produce.
For our example, we use the published microsoft/layoutlm-base-uncased pre-trained model (on the IIT CDIP 1.0 dataset) and annotate a relatively small number of credit card agreements from CFPB for fine-tuning.
Although this may be an appropriate fast-start even for real-world use cases, remember that large, pre-trained language models can carry some important implications:
- Model accuracy – This could be reduced if your documents are substantially different than the pre-training set, such as Wikipedia vs. news articles vs. legal contracts.
- Privacy – In some cases, input data can be reverse-engineered from a trained model, for example in Extracting Training Data from Large Language Models (2020).
- Bias – Large language models learn not just grammar and semantics from datasets, but other patterns too. Practitioners must consider the potential biases in source datasets, and what real-world harms this could cause if the model absorbs stereotypes, such as on gender, race, or religion. For example, see StereoSet: Measuring stereotypical bias in pretrained language models (2020).
In Notebook 1 of the solution sample, you walk through initial collection and annotation of data.
First, we run a fraction of the source documents through Amazon Textract to extract the text and position data. You could also consider extracting the full corpus and extending the modeling code to use this as unlabeled pre-training data.
Then, for documents we want to annotate, we extract individual pages as images using open-source tools.
This image data enables us to use the standard bounding box labeling tool in Amazon SageMaker Ground Truth to efficiently tag fields of interest by drawing boxes around them (see the following screenshot).

For the example use case, we provide 100 prepared annotations for pages in the dataset, so you can get started with a reasonable model without spending too much time labeling additional data.
With the unsupervised text and location data from Amazon Textract, and the bounding box labels from Ground Truth for a subset of the pages, we have the inputs needed to pre-train and fine-tune a model.
Train and deploy the model
To maintain full traceability from extracted words to output fields, our example frames the task as classifying each word between the different field types (or none). We use the LayoutLMForTokenClassification implementation provided in the popular Hugging Face Transformers library and fine-tune their layoutlm-base-uncased pre-trained model.
With the SageMaker framework container for Hugging Face transformers (also available for PyTorch, TensorFlow, Scikit Learn, and others), we can take advantage of pre-implemented setup and serving stacks. All we need to write is a script for training (parsing the input JSON from Amazon Textract and Ground Truth) and some override functions for inference (to apply the model directly to that JSON format).
Notebook 2 of the solution sample demonstrates how to run different training job experiments from the notebook through the SageMaker APIs, which run on dedicated infrastructure so you can benefit from per-second, pay-as-you-go billing for GPU resource time required for each job.
We can take advantage of SageMaker features like training job metrics, automatic hyperparameter tuning, and experiment tracking to explore different algorithm configurations and optimize model accuracy (see the following screenshots).
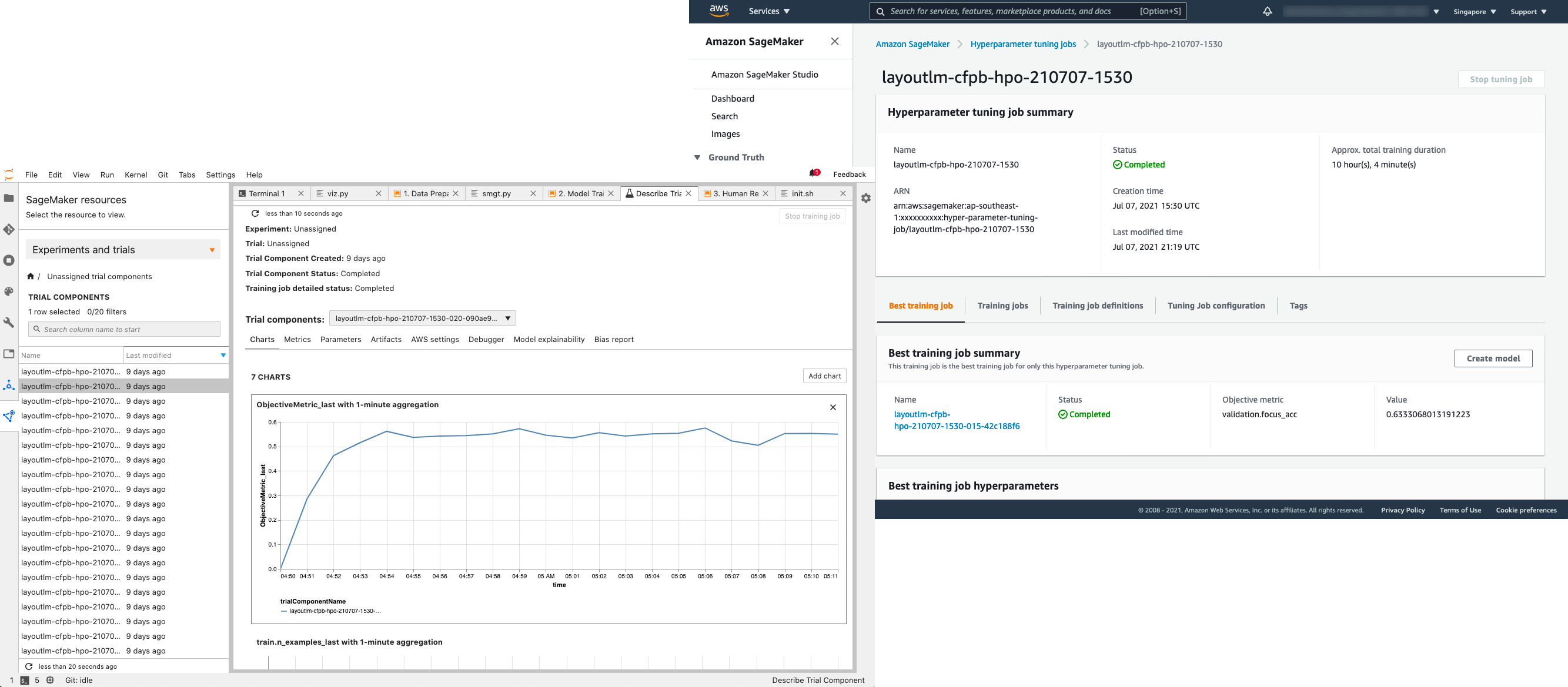
With training completed successfully, we have a model that can take Amazon Textract JSON results as input and pick out which words in the input document belong to the various defined entity types.
Because the model returns that same JSON format as the response, but enriched with the additional metadata, we can help simplify integration. Existing pipelines set up for Amazon Textract can read the JSON as usual, but take advantage of the extra fields if they’re present and understood by the consumer.
We can deploy the trained model to a real-time inference endpoint with a single function call in the SageMaker Python SDK, and then test it from the Amazon SageMaker Studio notebook (see the following screenshot).

Create an end-to-end OCR pipeline
In this example, as in most cases, you typically still have extra steps in the overall process flow besides running the source document through Amazon Textract and calling the ML model:
- Extracting the information is nearly always one step within a broader business process, which might include many different kinds of steps, both automated and manual.
- We often want to apply some business rules over the top of the ML model to add constraints or bridge remaining gaps between what the model outputs and the business process needs. For example, to enforce that certain fields must be numerical or follow particular patterns like an email address.
- We often need to validate the results of the automated extraction and trigger a human review if something seems to be wrong; for example, if required fields are missing or the model has low confidence.
- Some use cases may need image preprocessing before the OCR is even attempted; for example, to verify that an identity document looks legitimate, or to triage the type of image or document submitted.
- Some use cases may even apply multiple ML models to meet the overall business requirement.
Although you can build these end-to-end pipelines via point-to-point integrations, architectures like this can potentially become brittle to change.
If we instead use an orchestration service to manage the overall flow, we can help de-couple the architectures of individual stages. This makes it easier to swap out components and have a centralized view for tracing the path of stages.
AWS Step Functions is a low-code visual workflow service that we can use to orchestrate complex processes like this in a serverless fashion. The following diagram illustrates our workflow.
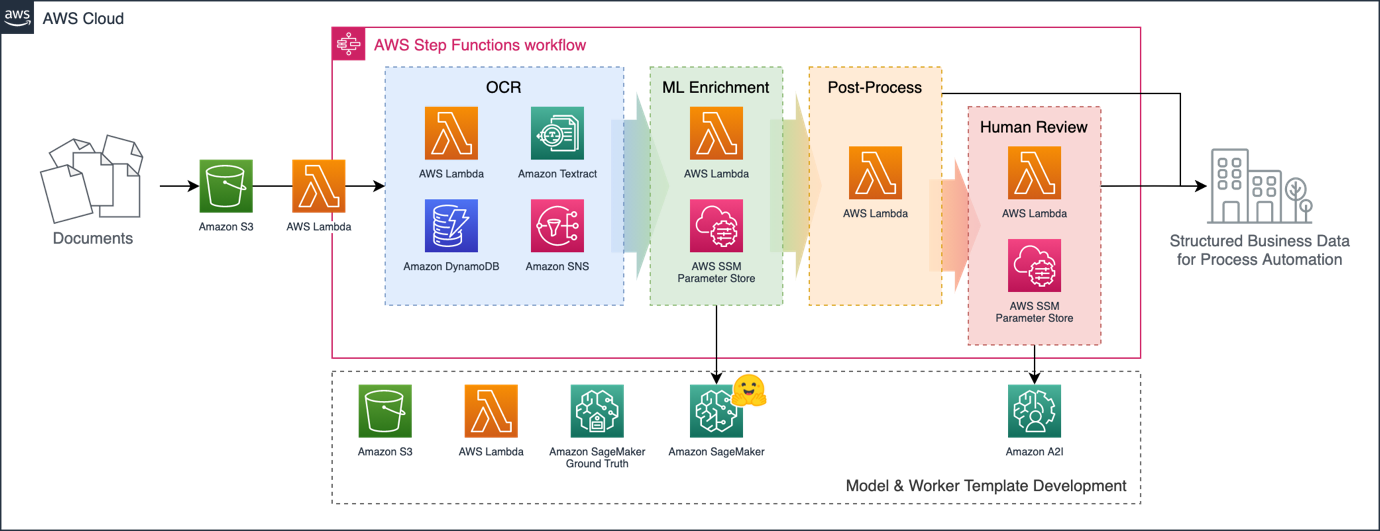
Step Functions allows us to build and monitor the full workflow visually as a graph, with integrations to a broad range of services and a serverless pricing model that’s independent of the time individual steps take to run, even for processes that might take up to a year to complete.
In our example, we chain together the steps of the initial OCR, ML model enrichment, rule-based postprocessing, and potential human review, as shown in the following screenshot. We can define the criteria for accepting model results vs. escalating to reviewers directly in Step Functions with no coding required. In this case, we use a simple overall confidence threshold check.
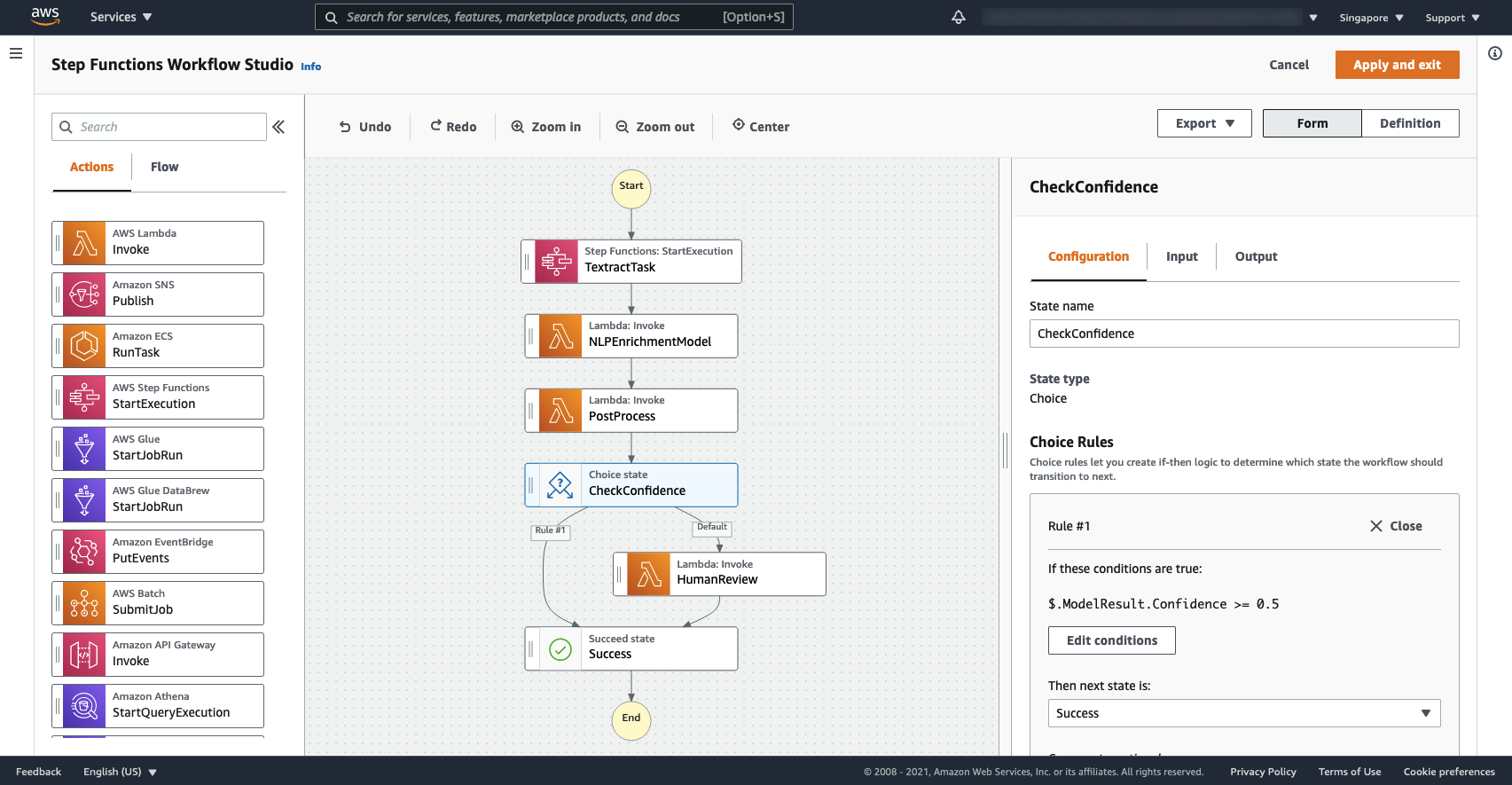
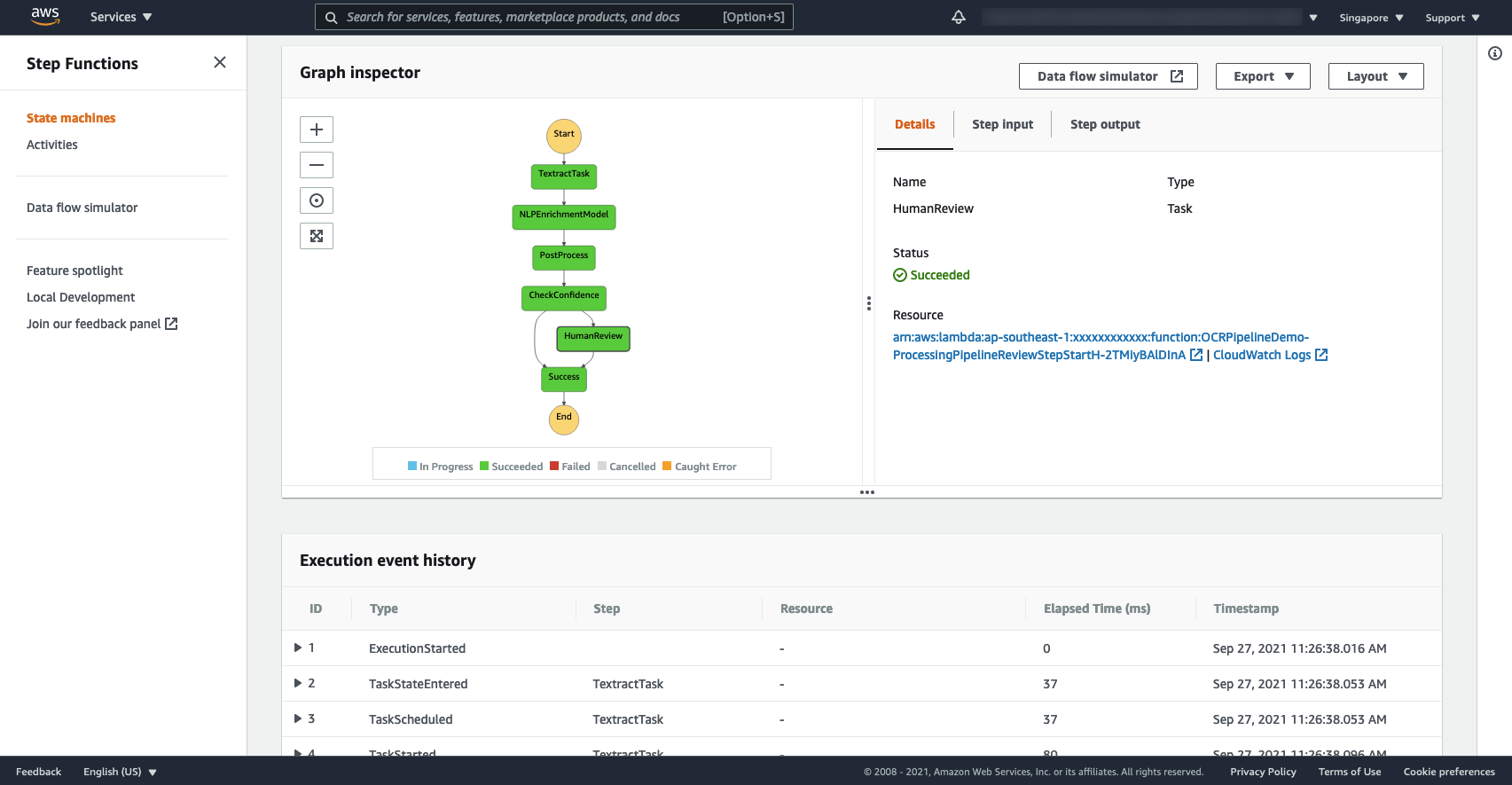
We can trigger running the Step Functions workflow automatically on upload of a new document to Amazon Simple Storage Service (Amazon S3) or via a broad range of other sources including Amazon EventBridge rules, AWS IoT Core Rules Engine, Amazon API Gateway, the Step Functions API itself, and more.
Likewise, although the Step Functions pipeline alone is enough to illustrate the example for our purposes, you have a broad range of options for integrating other services into the workflow or storing workflow outputs.
Ongoing learning and improvement
Human reviews in the solution are powered by Amazon Augmented AI (Amazon A2I), a service that shares a lot in common with Ground Truth (used earlier to gather initial training data), but is designed for online, single-item reviews rather than batch annotation jobs.
Amazon A2I has the following similarities to Ground Truth:
- You can define teams of your own workers to perform the work, use the public crowd with Amazon Mechanical Turk, or source skilled vendors through the AWS Marketplace
- The user interface for the task is defined in the Liquid HTML templating language, with a set of built-in tasks but also a range of public samples helping you build custom UIs for your needs
- Annotation outputs are in JSON format, stored on Amazon S3, which makes results easy to integrate with a wide range of downstream tools and processes
- Service pricing is by the number of items annotated or reviewed, regardless of job duration, with no need for you to maintain a server available for workers to log in to
In practice, an important consideration for the ongoing retraining of document digitization solutions is the potential tension between business process review activities and ML model training data collection.
If any gap exists between what the actual ML model outputs and what the business process uses, then using reviews to collect training data implicitly means increasing the reviewers’ workload because they need to check more than the minimum required to actually run the process.
In our basic example, the model detects (potentially multiple) mentions of the target entity types in the document, and then business rules (in the postprocessing step) consolidate these down. For the business process to work effectively, the minimum effort from a reviewer is to check and edit the consolidated value (for example, the credit card provider name). To use the data for retraining the model, however, the reviewer needs to go to the extra effort of annotating all mentions of the entity in the document.
Often, there’s a strong need to optimize the efficiency of online reviews in order to keep whatever process you’re automating running smoothly. Model improvement may also not require every one of these reviews to be incorporated into the training set (indeed, that could even skew the model in some cases if taken as an assumption).
Therefore, in the example solution (see Notebook 3), we demonstrate a custom review UI, which is different from the bounding box tool used to collect model training data (see the following screenshot).
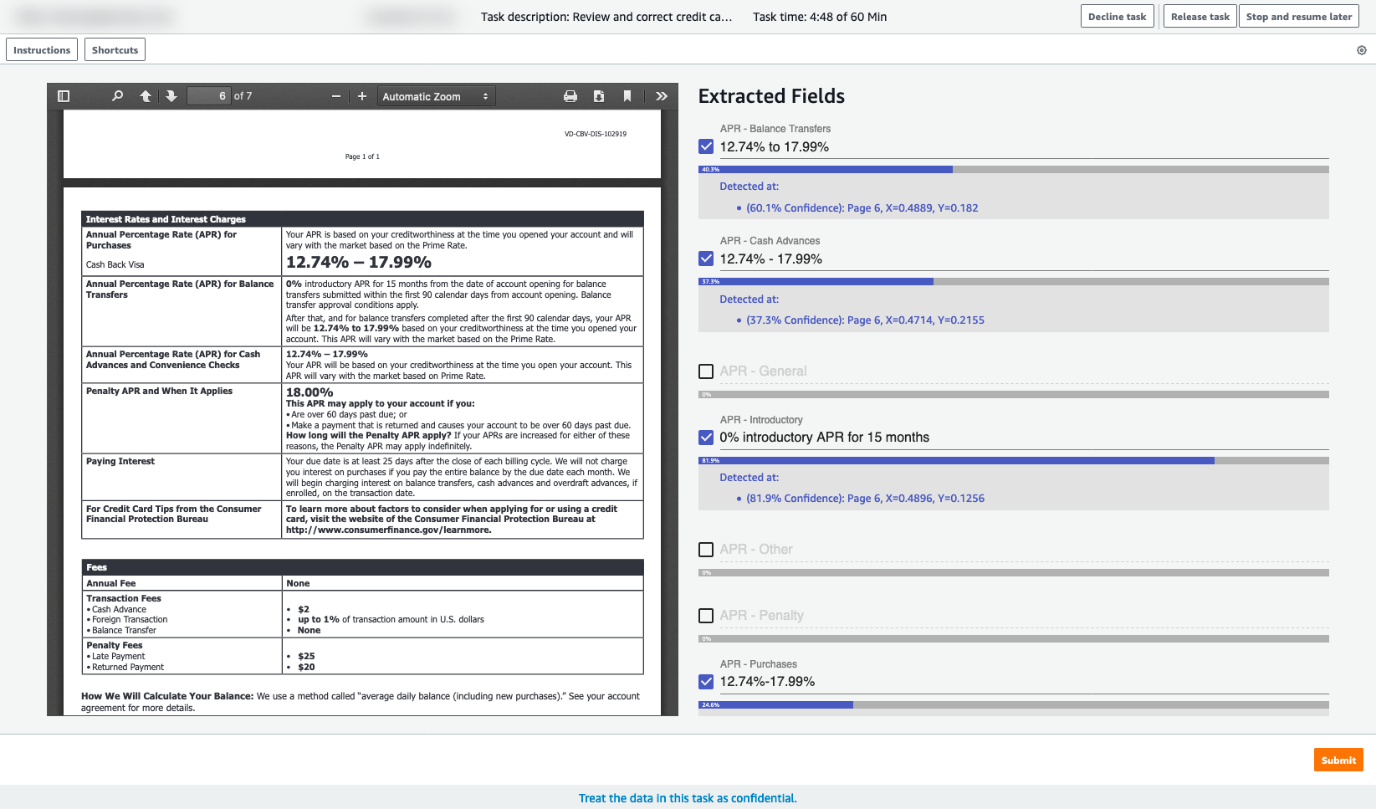
With this pattern, the results of (online) reviews can be stored and used to guide the (offline) training data collection team towards likely interesting and useful examples.
Of course, this is an example workflow only, and it might be practical to remove this separation, such as in the following cases:
- For documents where each field normally appears only once
- With a modified model where the consolidation of matches was part of the model itself
- Where training data needs to be collected at large scale and the impact of that extra effort on online reviews is acceptable
Conclusion and next steps
In this post, we showed a specific working example of ML-based postprocessing on Amazon Textract results, with broader possibilities for extension and customization.
With modern, transformer-based NLP model architectures, you can use pretrained models to build solutions with relatively little labeled data, or even create large in-house pre-training datasets from digitized but unlabeled documents.
In particular, location-aware language models like LayoutLM can ingest not just the extracted text but also the per-word bounding boxes output by Amazon Textract. This creates high-performing models that consider both the transcribed text and its location on the page.
SageMaker provides tools to accelerate the end-to-end ML project lifecycle: from collecting, labeling, and preprocessing data; through training and tuning models; to deploying, monitoring, and reviewing predictions from models in production.
Step Functions offers powerful tooling for orchestrating flexible, end-to-end workflows that combine these trainable models with business rules and other components.
Beyond integrating and customizing the process flow, you can extend the ML model itself in a number of ways by building on available open-source tools. For example, you can do the following:
- Simply classify whole pages (document type classification) instead of individual tokens (entity extraction)
- Apply existing training patterns for more generative text summarization or translation tasks to LayoutLM to create models capable of fixing OCR errors in the output instead of just annotating the text
- Further extend the input embeddings, for example to also represent the confidence score the OCR engine gave each detected word
When you combine SageMaker models with Amazon Textract, you can build and operationalize high-accuracy, highly customizable, retrainable automations for even complex document analysis tasks.
The example code discussed in this post is available on GitHub. We hope you find it useful and would love to hear about solutions you build inspired by it!
For other examples integrating Amazon Textract, see Additional Code Examples.
To find out more about starting out with SageMaker for your custom ML projects, refer to Get Started with Amazon SageMaker. You can also learn more about the SageMaker Python SDK, and running models on SageMaker with Hugging Face.
About the Author
 Alex Thewsey is a Machine Learning Specialist Solutions Architect at AWS, based in Singapore. Alex helps customers across Southeast Asia to design and implement solutions with AI and ML. He also enjoys karting, working with open source projects, and trying to keep up with new ML research.
Alex Thewsey is a Machine Learning Specialist Solutions Architect at AWS, based in Singapore. Alex helps customers across Southeast Asia to design and implement solutions with AI and ML. He also enjoys karting, working with open source projects, and trying to keep up with new ML research.